In Chapter 5.1 and Chapter 5.1, Part 2, we saw that eigenvalues and eigenvectors allow us to better understand the behavior of the linear transformation from Rn to Rn given by an n×n matrix A.
When understanding matrix powers and adjacency matrices, we often decomposed some arbitrary vector x as a linear combination of eigenvectors of A. But sometimes, the eigenvectors of A don’t span all of Rn, meaning we can’t write every other vector as a linear combination of eigenvectors of A. When does this happen, and why do we really care?
Recall that if A is an n×n matrix, then A has n eigenvalues, it’s just that some of the eigenvalues may be complex (leading to complex-valued eigenvectors), and some eigenvalues may be repeated. These n eigenvalues are all solutions to the characteristic polynomial of A,
p(λ)=det(A−λI)
The corresponding eigenvectors are the solutions to the system of equations (A−λI)v=0.
Suppose A has n linearly independent eigenvectors v1,v2,⋯,vn, with eigenvalues λ1,λ2,⋯,λn. What I’m about to propose next will seem a little arbitrary, but bear with me – you’ll see the power of this idea shortly. What happens if we multiply A by a matrix, say V, whose columns are the eigenvectors of A?
Here, Λ (the capitalized Greek letter for λ) is a diagonal matrix of eigenvalues in the same order as the eigenvectors in V.
AV=VΛ
We can take this a step further. IfV is invertible – which it is here, since we assumed A has n linearly independent eigenvectors – then we can multiply both sides of the equation above by V−1 on the right to get
A=VΛV−1
The existence of this decomposition is contingent on V being invertible, which happens when A has n linearly independent eigenvectors. If A doesn’t have “enough” eigenvectors, then V wouldn’t be invertible, and we wouldn’t be able to decompose A in this way.
Let’s start with a familiar example, A=[1221], which was the first example we saw in Chapter 5.1. A has eigenvalues λ1=3 and λ2=−1, and corresponding eigenvectors v1=[11] and v2=[1−1]. These eigenvectors are linearly independent, so A is diagonalizable, and we can write
V = np.array([[1, 1],
[1, -1]])
Lambda = np.diag([3, -1]) # New tool.
V_inv = np.linalg.inv(V)
V @ Lambda @ V_inv # The same as A!
array([[1., 2.],
[2., 1.]])
Is this decomposition unique? No, because we could have chosen a different set of eigenvectors, or wrote them in a different order (in which case Λ would be different). We’ll keep the eigenvectors in the same order, but instead let’s consider
V=[22−55]
which is also a valid eigenvector matrix for A. (Remember that any scalar multiple of an eigenvector is still an eigenvector!)
It is still true that A=VΛV−1. This may seem a little unbelievable (I wasn’t convinced at first), but remember that V−1 “undoes” any changes in scaling we introduce to V.
So, to compute Ak, we don’t need to multiply k matrices together (which would be a computational nightmare for large k). Instead, all we need to do is compute VΛkV−1. And remember, Λ is a diagonal matrix, so computing Λk is easy: we just raise the diagonal entries to the power in question.
Application 2: Understanding Linear Transformations¶
Remember that if A is an n×n matrix, then f(x)=Ax is a linear transformation from Rn to Rn. But, if A=VΛV−1, then
f(x)=Ax=VΛV−1x
This allows us to understand the effect of f on x in three stages. Remember that V’s columns are the eigenvectors of A, so the act of multiplying a vector y by V is equivalent to taking a linear combination of V’s columns (A’s eigenvectors) using the weights in y.
For example, V[3−4] says take 3 of the first eigenvector, and -4 of the second eigenvector, and add them together to get a new vector. If V[3−4]=[12], this says that taking 3 of the first eigenvector and -4 of the second eigenvector is the same as taking 1 of the first standard basis vector, [10] and 2 of the second standard basis vector, [01].
Intuitively, think of V as a matrix that takes in “amounts of each eigenvector” and outputs “amounts of each standard basis vector”, where the standard basis vectors are the columns of I.
i.e. multiplying V−1 by xexpresses x as a linear combination of the eigenvectors of A. If z is the output of V−1x, then x=Vz, meaning z contains the amounts of each eigenvector needed to produce x.
(This is non-standard notation, since V is not a function and eigenvector amounts and standard basis vector amounts are not sets but concepts, but I hope this helps convey the role of V and V−1 in this context.)
Taking a step back, recall
f(x)=Ax=VΛV−1x
What this is saying is f does three things:
First, it takes x and expresses it as a linear combination of the eigenvectors of A, which is V−1x. (This contains the “amounts of each eigenvector” needed to produce x.)
Then, it takes that linear combination V−1x and scales each eigenvector by its corresponding eigenvalue, i.e. it scales or stretches each eigenvector by a different amount. Remember that diagonal matrices only scale, they don’t do anything else!
Finally, it takes the resulting scaled vector ΛV−1x and expresses it as a linear combination of the standard basis vectors, i.e. it combines the correct amounts of the stretched eigenvectors to get the final result.
multiply by V−1express in eigenvector basis→multiply by Λscale eigenvectors→multiply by Vexpress in standard basis
Most matrices we’ve seen in Chapter 5.1 and here so far in Chapter 5.2 have been diagonalizable. I’ve tried to shield you from the messy world of non-diagonalizable matrices until now, but we’re ready to dive deeper.
Consider A=[1011]. The characteristic polynomial of A is
p(λ)=det(A−λI)=det[1−λ011−λ]=(1−λ)2
which has a double root of λ=1. So, A has a single eigenvalue λ=1. What are all of A’s eigenvectors? They’re solutions to Av=1v, i.e. (A−I)v=0. Let’s look at the null space of A−I:
A−I=[1−1011−1]=[0010]
The null space of A−I is spanned by the single vector [10]. So, A has a single line of eigenvectors, spanned by v1=[10].
So, does A have an eigenvalue decomposition? No, because we don’t have enough eigenvectors to form V. If we try and form V by using v1 in the first column and a column of zeros in the second column, we’d have
V=[1000]
but this is not an invertible matrix, so V is not invertible, and we can’t write A=VΛV−1. A is not diagonalizable! This means that it’s harder to interpret A as a linear transformation through the lens of eigenvectors, and it’s harder to understand the long-run behavior of Akx for an arbitrary x.
Let me emphasize what I mean by A needing to have nlinearly independent eigenvectors. Above, we found that [10] is an eigenvector of A, which means that any scalar multiple of [10] is also an eigenvector of A. But, the matrix
[1020]
is not invertible, meaning it can’t be the V in A=VΛV−1.
The 2×2 identity matrix I=[1001] has the characteristic polynomial p(λ)=(λ−1)2. So, I has a single eigenvalue λ=1, just like the last example.
But, λ=1 corresponds to two different eigenvector directions! I can pick any two linearly independent vectors in R2 and they’ll both be eigenvectors for I. For example, let v1=[1−3] and v2=[1198], meaning
V=[1−31198]
The matrix Λ is just [1001] which is the same as I itself. This means that as long as V is invertible (i.e. as long as I pick two linearly independent vectors in R2),
VΛV−1=VIV−1=VV−1=I
which means that indeed, I is diagonalizable. (Any matrix that is diagonal to begin with is diagonalizable: in A=PDP−1, P is just the identity matrix.)
If you’d rather look at this example through the lens of solving systems of equations, an eigenvector v=[ab] of I with eigenvalue λ=1 satisfies
Iv=[1001][ab]=[ab]=1[ab]
But, as a system this just says a=a and b=b, which is true for any v. Think of a and b both as independent variables; the set of possible v’s, then, is two dimensional (and is all of R2).
A is not invertible (column 2 is double column 1), so it has an eigenvalue of λ1=0, which corresponds to the eigenvector v1=[−21].
It also has an eigenvalue of λ2=5, corresponding to the eigenvector v2=[12]. (Remember, the quick way to spot this eigenvalue is to remember that the sum of the eigenvalues of A is equal to the trace of A, which is 1+4=5; since 0 is an eigenvalue, the other eigenvalue must be 5.)
Does A have an eigenvalue decomposition? Let’s see if anything goes wrong when we try and construct the eigenvector matrix V and the diagonal matrix Λ and multiplying VΛV−1.
V=[−2112],Λ=[0005]
VΛV−1=[−2112][0005][−2/51/51/52/5]=[1224]
Everything worked out just fine! A is diagonalizable, even though it’s not invertible.
As we saw in an earlier example, the matrix [1011] does not have two linearly independent eigenvectors, and so is not diagonalizable. I’d like to dive deeper into identifying when a matrix is diagonalizable.
The algebraic multiplicity of an eigenvalue, as the name suggests, is purely a property of the characteristic polynomial. Alone, they don’t tell us whether or not a matrix is diagonalizable. Instead, we’ll need to look at another form of multiplicity alongside the algebraic multiplicity.
The geometric multiplicity of an eigenvalue can’t be determined from the characteristic polynomial alone – instead, it involves finding nullsp(A−λiI) and finding its dimension, i.e. the number of linearly independent vectors needed to span it. But in general,
1≤GM(λi)≤AM(λi)
Think of the algebraic multiplicity of an eigenvalue as the “potential” number of linearly independent eigenvectors for an eigenvalue, sort of like the number of slots we have for that eigenvalue. The geometric multiplicity, on the other hand, is the number of linearly independent eigenvectors we actually have for that eigenvalue. As we’ll see in the following examples, when the geometric multiplicity is less than the algebraic multiplicity for any eigenvalue, the matrix in question is not diagonalizable.
In each of the following matrices A, we’ll
Find the algebraic multiplicity of each of A’s eigenvalues.
For each eigenvalue, find the geometric multiplicity and a basis for the eigenspace.
Conclude whether A is diagonalizable.
As usual, attempt these examples on your own first before peeking at the solutions.
First, we’ll find the characteristic polynomial of A:
p(λ)=det(A−λI)=∣∣1−λ0011−λ0011−λ∣∣=(1−λ)3
(You should practice quickly finding the characteristic polynomial of a 3×3 matrix; Chapter 5.1 has relevant examples.)
This tells us that A has a single eigenvalue λ=1, with algebraic multiplicity AM(1)=3.
The geometric multiplicity of λ=1 is dim(nullsp(A−I)). Let’s look at A−I:
A−I=⎣⎡000100010⎦⎤
A−I has rank 2, so dim(nullsp(A−I))=3−2=1 (from the rank-nullity theorem), so the geometric multiplicity of λ=1 is GM(1)=1.
The vector v1=⎣⎡100⎦⎤ is an eigenvector for λ=1, and so is any scalar multiple of v1; I found this by noticing that the first column of A−I is all zeros. So,
nullsp(A−I)=span⎝⎛⎩⎨⎧⎣⎡100⎦⎤⎭⎬⎫⎠⎞
Since GM(1)=1<AM(1)=3, A is not diagonalizable. A only has one linearly independent eigenvector!
So, the eigenvalues are λ1=1 and λ2=0.5, each with algebraic multiplicity AM(1)=AM(0.5)=1.
The fact that A has two distinct eigenvalues alone tells us that A is diagonalizable, since each eigenvalue has exactly one independent eigenvector (which really means a line of eigenvectors, or a 1-dimensional eigenspace) and eigenvectors for different eigenvalues are always linearly independent. Let’s find those eigenvectors to be sure.
For λ1=1, we solve (A−I)v=0:
A−I=[−0.20.20.3−0.3]
The null space of this matrix is spanned by [32], so nullsp(A−I)=span({[32]}) and GM(1)=1.
For λ2=0.5, we solve (A−0.5I)v=0:
A−0.5I=[0.30.20.30.2]
The null space of this matrix is spanned by [−11], so nullsp(A−0.5I)=span({[−11]}) and GM(0.5)=1.
Since A has two linearly independent eigenvectors, it is diagonalizable:
So, A has eigenvalues λ1=3 with AM(3)=2 and λ2=1 with AM(1)=1.
For λ1=3, we solve (A−3I)v=0:
A−3I=⎣⎡−1101−10000⎦⎤
rank(A−3I)=1 (since all columns are multiples of ⎣⎡−110⎦⎤), so dim(nullsp(A−3I))=3−1=2, which means GM(3)=2. At this point, we can conclude that A is diagonalizable! But, let’s find a basis for the eigenspace nullsp(A−3I) to be thorough.
Two linearly independent vectors in nullsp(A−3I) are ⎣⎡110⎦⎤ and ⎣⎡001⎦⎤, so nullsp(A−3I)=span⎝⎛⎩⎨⎧⎣⎡110⎦⎤,⎣⎡001⎦⎤⎭⎬⎫⎠⎞. This is just one possible basis for the eigenspace; it’s not the only one.
What this says is any linear combination of ⎣⎡110⎦⎤ and ⎣⎡001⎦⎤ is also an eigenvector for λ=3. For example, ⎣⎡210120003⎦⎤⎣⎡−1−113⎦⎤=3⎣⎡−1−113⎦⎤.
For λ2=1, we solve (A−I)v=0:
A−I=⎣⎡110110002⎦⎤
Since AM(1)=1, we know that there could only be one linearly independent eigenvector for λ2=1, so GM(1)=1 too. One such eigenvector is ⎣⎡1−10⎦⎤, so nullsp(A−I)=span⎝⎛⎩⎨⎧⎣⎡1−10⎦⎤⎭⎬⎫⎠⎞.
Since A has three linearly independent eigenvectors, it is diagonalizable:
(Note that this A is almost identical to the A in the previous example, but with a 1 switched to a 0 in the second row.)
Solution
A is upper triangular, so its eigenvalues are the entries on the diagonal: λ1=2, λ2=2, λ3=3. So, AM(2)=2 and AM(3)=1.
For λ1=2, we solve (A−2I)v=0:
A−2I=⎣⎡000100001⎦⎤
rank(A−2I)=2, so dim(nullsp(A−2I))=1, so GM(2)=1. At this point, we can conclude that A is not diagonalizable, since GM(2)<AM(2). Noticing that the first column of A−2I is all zeros, v1=⎣⎡100⎦⎤ is an eigenvector, and
nullsp(A−2I)=span⎝⎛⎩⎨⎧⎣⎡100⎦⎤⎭⎬⎫⎠⎞
For λ3=3, we solve (A−3I)v=0:
A−3I=⎣⎡−1001−10000⎦⎤
Using similar logic, GM(3)=1 and
nullsp(A−3I)=span⎝⎛⎩⎨⎧⎣⎡001⎦⎤⎭⎬⎫⎠⎞
A only has two linearly independent eigenvectors, one for λ=2 and one for λ=3, but is a 3×3 matrix, and hence its not diagonalizable. (Also, for λ1=2, the geometric multiplicity, 1, is less than the algebraic multiplicity, 2, but we need equality for all eigenvalues in order for A to be diagonalizable.)
Symmetric matrices – that is, square matrices where A=AT – behave really nicely through the lens of eigenvectors, and understanding exactly how they work is key to Chapter 5.3, when we generalize beyond square matrices.
If you search for the spectral theorem online, you’ll often just see Statement 4 above; I’ve broken the theorem into smaller substatements to see how they are chained together.
The proof of Statement 1 is beyond our scope, since it involves fluency with complex numbers. If the term “complex conjugate” means something to you, read the proof here – it’s relatively short.
I’m not going to cover the proof of Statement 3 here, as I don’t think it’ll add to your learning.
Orthogonal matrices Q satisfy QTQ=QQT=I, meaning their columns (and rows) are orthonormal, not just orthogonal to one another. The fact that QTQ=QQT=I means that QT=Q−1, so taking the transpose of a matrix is the same as taking its inverse.
So, instead of
A=VΛV−1
we’ve “upgraded” to
A=QΛQT
This is the main takeaway of the spectral theorem: that symmetric matrices can be diagonalized by an orthogonal matrix. Sometimes, A=QΛQT is called the spectral decomposition of A, but all it is is a special case of the eigenvalue decomposition for symmetric matrices.
Why do we prefer QΛQT over VΛV−1? Taking the transpose of a matrix is much easier than inverting it, so actually working with QΛQT is easier.
no inversion needed!A=QΛQT⟹Ak=QΛkQT
But it’s also an improvement in terms of interpretation: remember that orthogonal matrices are matrices that represent rotations. So, if A is symmetric, then the linear transformation f(x)=Ax is a sequence of rotations and stretches.
f(x)=Ax=QΛQTx
Let’s make sense of this visually. Consider the symmetric matrix A=[1221].
import numpy as np
import plotly.graph_objects as go
from plotly.subplots import make_subplots
from utils import plot_vectors
def plot_unit_square_and_transform(
A=None,
B=None,
name_A="A",
name_B="B",
vdeltax_A=-0.3,
vdeltay_A=0.2,
vdeltax_B=0.5,
vdeltay_B=0,
return_fig=False,
show_labels=True,
axis_range=[-3.5, 3.5],
title=''
):
"""
Visualize transformation of the unit square and basis vectors under two matrices.
Left: vectors A u_x and A u_y and parallelogram from A (default is identity -- the unit square and basis)
Right: vectors B u_x and B u_y and parallelogram from B (default is the input B)
"""
# Default: left is unit, right is input (legacy)
if A is None:
A = np.eye(2)
if B is None:
B = np.eye(2)
# Vertices of the unit square
square = np.array([
[0, 0], # A
[1, 0], # B
[1, 1], # C
[0, 1], # D
[0, 0] # A (to close the square)
])
square_A = (A @ square.T).T
square_B = (B @ square.T).T
# Create subplot figure
left_title = r"$$" + name_A + r"\vec u_x \text{ and } " + name_A + r"\vec u_y$$" if (name_A and show_labels) else ""
right_title = r"$$" + name_B + r"\vec u_x \text{ and } " + name_B + r"\vec u_y$$" if (name_B and show_labels) else ""
fig = make_subplots(
rows=1, cols=2,
subplot_titles=(left_title, right_title),
horizontal_spacing=0.08,
)
# Common axis settings
axis_style = dict(
showgrid=True,
gridcolor="#f0f0f0",
zeroline=False, # We'll add our own zero lines
showline=True,
linecolor="#f0f0f0",
mirror=True,
ticks="outside",
showticklabels=True,
tickfont=dict(family="Palatino, serif", size=14),
)
# Set axis ranges to [-4, 4] for both subplots
for i in [1, 2]:
fig.update_xaxes(
range=axis_range,
constrain="domain",
dtick=1,
**axis_style,
row=1, col=i
)
fig.update_yaxes(
range=axis_range,
scaleanchor=f"x{i}",
dtick=1,
**axis_style,
row=1, col=i
)
# --- Draw faint 0 grid lines underneath everything else ---
for i in [1, 2]:
# Horizontal y=0
fig.add_shape(
type="line",
x0=-4, x1=4, y0=0, y1=0,
line=dict(color="rgba(170,170,170,0.25)", width=2, dash="solid"),
row=1, col=i,
layer="below"
)
# Vertical x=0
fig.add_shape(
type="line",
x0=0, x1=0, y0=-4, y1=4,
line=dict(color="rgba(170,170,170,0.25)", width=2, dash="solid"),
row=1, col=i,
layer="below"
)
# -- Plot left parallelogram (A unit square) in blue
fig.add_trace(
go.Scatter(
x=square_A[:,0], y=square_A[:,1],
fill="toself",
fillcolor="rgba(61,129,246,0.4)",
line=dict(color="rgba(0,0,0,0)", width=0), # No perimeter
name=f"{name_A} square",
showlegend=False
),
row=1, col=1
)
# -- Plot right parallelogram (B unit square) in orange
fig.add_trace(
go.Scatter(
x=square_B[:,0], y=square_B[:,1],
fill="toself",
fillcolor="rgba(255,140,0,0.4)",
line=dict(color="rgba(0,0,0,0)", width=0),
name=f"{name_B} square",
showlegend=False
),
row=1, col=2
)
# --- Draw vectors using plot_vectors ---
# Standard basis vectors
u_x = np.array([1, 0])
u_y = np.array([0, 1])
# Left: A u_x, A u_y in #3d81f6
Au_x = A @ u_x
Au_y = A @ u_y
if show_labels:
left_vecs = [
(tuple(Au_x), '#3d81f6', rf'${name_A}\vec u_x$'),
(tuple(Au_y), '#3d81f6', rf'${name_A}\vec u_y$'),
]
else:
left_vecs = [
(tuple(Au_x), '#3d81f6', None),
(tuple(Au_y), '#3d81f6', None),
]
left_fig = plot_vectors(left_vecs, vdeltax=vdeltax_A, vdeltay=vdeltay_A)
left_fig.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
paper_bgcolor="rgba(0,0,0,0)",
xaxis=dict(visible=False),
yaxis=dict(visible=False),
margin=dict(l=0, r=0, t=0, b=0)
)
# Add the vector traces to the left subplot
for trace in left_fig.data:
fig.add_trace(trace, row=1, col=1)
# Add the vector annotations to the left subplot, if enabled
if show_labels:
for ann in left_fig.layout.annotations:
if hasattr(ann, "to_plotly_json"):
ann_dict = ann.to_plotly_json()
else:
ann_dict = dict(ann)
ann_dict = {k: v for k, v in ann_dict.items() if k not in {"xref", "yref", "axref", "ayref"}}
fig.add_annotation(**ann_dict, row=1, col=1)
# Right: B u_x, B u_y in orange
Bu_x = B @ u_x
Bu_y = B @ u_y
if show_labels:
right_vecs = [
(tuple(Bu_x), 'orange', rf'${name_B}\vec u_x$'),
(tuple(Bu_y), 'orange', rf'${name_B}\vec u_y$'),
]
else:
right_vecs = [
(tuple(Bu_x), 'orange', None),
(tuple(Bu_y), 'orange', None),
]
right_fig = plot_vectors(right_vecs, vdeltax=vdeltax_B, vdeltay=vdeltay_B)
right_fig.update_layout(
plot_bgcolor="rgba(0,0,0,0)",
paper_bgcolor="rgba(0,0,0,0)",
xaxis=dict(visible=False),
yaxis=dict(visible=False),
margin=dict(l=0, r=0, t=0, b=0),
)
for trace in right_fig.data:
fig.add_trace(trace, row=1, col=2)
if show_labels:
for ann in right_fig.layout.annotations:
if hasattr(ann, "to_plotly_json"):
ann_dict = ann.to_plotly_json()
else:
ann_dict = dict(ann)
ann_dict = {k: v for k, v in ann_dict.items() if k not in {"xref", "yref", "axref", "ayref"}}
fig.add_annotation(**ann_dict, row=1, col=2)
fig.update_layout(
font=dict(family="Palatino, serif", size=16),
plot_bgcolor="white",
paper_bgcolor="white",
margin=dict(l=20, r=20, t=40, b=20),
width=800, height=400,
title=title
)
if return_fig:
return fig
fig.show(renderer='png', scale=3)
# Example usage (default: left=unit, right=A):
A = np.array([[1, 2], [2, 1]])
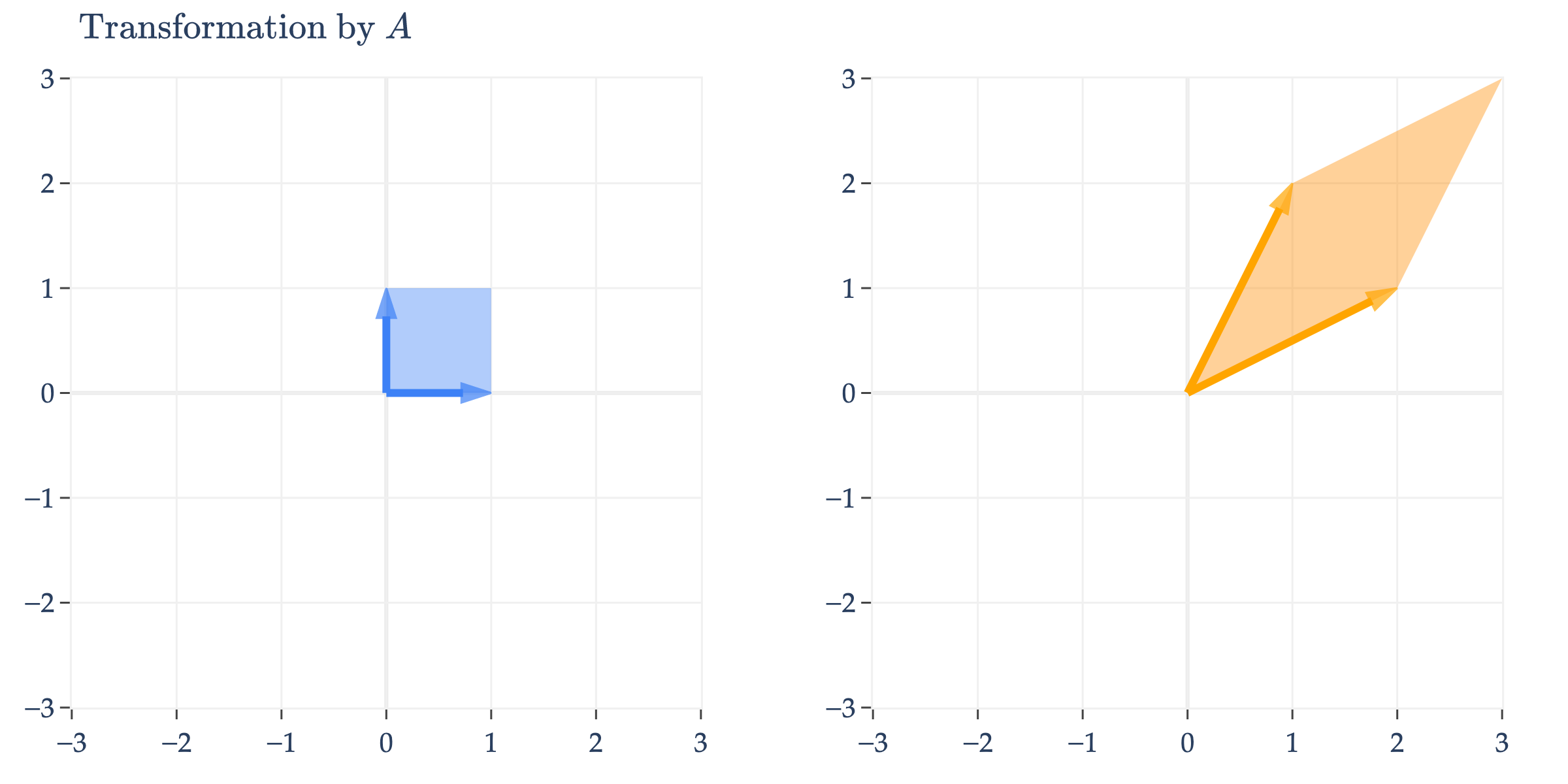
plot_unit_square_and_transform(B=A, name_B="A", show_labels=False, axis_range=[-3, 3], title=r'$$\text{Transformation by } A$$')
A appears to perform an arbitrary transformation; it turns the unit square into a parallelogram, as we first saw in Chapter 2.9.
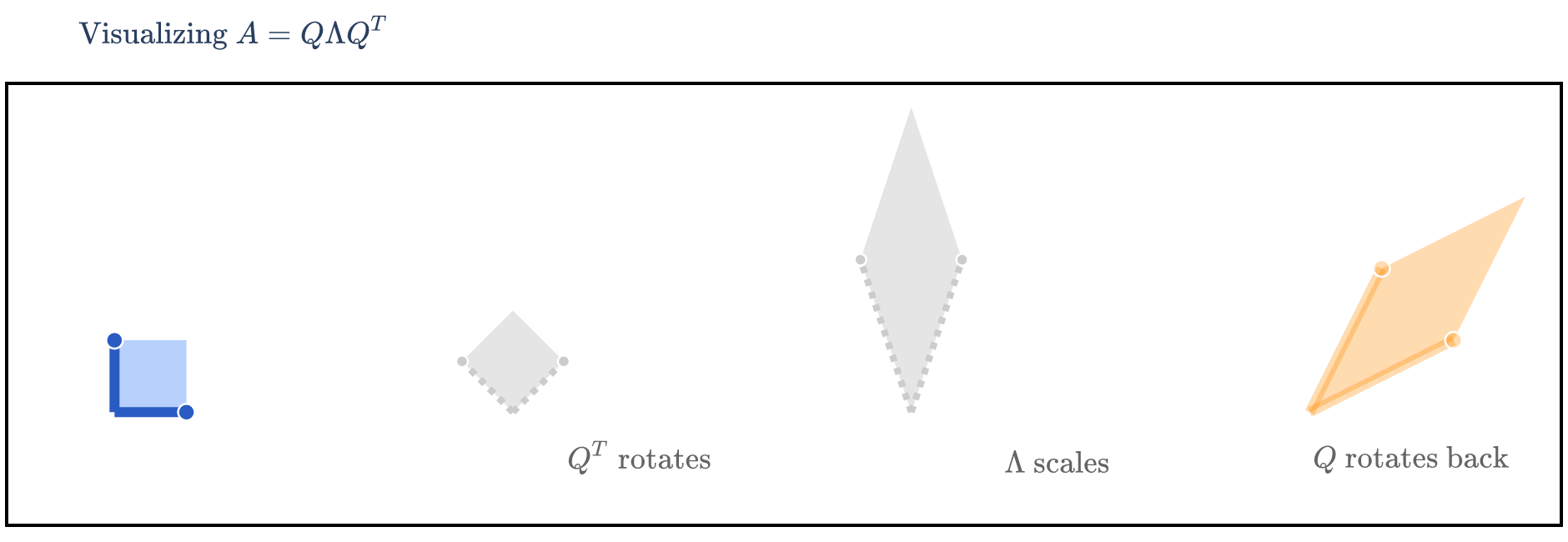
But, since A is symmetric, it can be diagonalized by an orthogonal matrix, A=QΛQT.
A=[1221]
has eigenvalues λ1=3 with eigenvector v1=[11] and λ2=−1 with eigenvector v2=[−11]. But, the vi’s I’ve written aren’t unit vectors, which they need to be in order for Q to be orthogonal. So, we normalize them to get q1=[2121] and q2=[−2121]. Placing these qi’s as columns of Q, we get
We’re visualizing how x turns into Ax, i.e. how x turns into QΛQTx. This means that we first need to consider the effect of QT on x, then the effect of Λ on that result, and finally the effect of Q on that result – that is, read the matrices from right to left.
import numpy as np
import plotly.graph_objects as go
from plotly.subplots import make_subplots
def plot_unit_square_diag_process(
Q,
Lambda,
square_color="rgba(61,129,246,0.37)", # blue for first subplot
qt_color="rgba(255,140,0,0.31)", # orange for last
lqt_color=None,
qlqt_color=None,
sq_border_color="rgba(255,255,255,0)",
show_arrows=True,
xaxis_range=[-1.5, 3.5],
yaxis_range=[1, 1],
title="",
return_fig=False,
show_labels=True,
names=None, # list of 4 subplot titles
vector_colors=None,
vector_label_color="#222"
):
# Colors for parallelograms
fill_colors = [square_color, "rgba(180,180,180,0.35)", "rgba(180,180,180,0.35)", qt_color]
# Arrows: 1st panel = blue, 2/3 = gray, 4th = orange
BLUE = "#2a5bc2"
ORANGE = qt_color if qt_color else "#ff8c00"
GRAY = "#cccccc"
arrow_colors = [BLUE, GRAY, GRAY, ORANGE]
# Step labels for bottom right corner (not the first)
step_labels = ["", r"$$Q^T \text{ rotates}$$", r"$$\Lambda \text{ scales}$$", r"$$Q \text{ rotates back}$$"]
I = np.eye(2)
M_list = [
I, # original unit square
Q.T, # first rotation/reflection
Lambda @ Q.T, # scaling in new basis
Q @ Lambda @ Q.T # rotate back
]
if not names:
names = [
r"Unit square",
r"$Q^T$",
r"$\Lambda Q^T$",
r"$Q\Lambda Q^T$"
]
square = np.array([
[0, 0], [1, 0], [1, 1], [0, 1], [0, 0]
])
u_x = np.array([1, 0])
u_y = np.array([0, 1])
fig = make_subplots(rows=1, cols=4,
subplot_titles=names,
horizontal_spacing=0.025) # bring plots closer
# Remove grid, ticks, numbers, and boxes completely
axis_style = dict(
showgrid=False,
zeroline=False,
showline=False,
mirror=False,
showticklabels=False,
ticks="",
)
for j in range(4):
fig.update_xaxes(range=xaxis_range, constrain="domain", **axis_style, row=1, col=j+1)
fig.update_yaxes(range=yaxis_range, scaleanchor=f"x{j+1}", **axis_style, row=1, col=j+1)
for j, M in enumerate(M_list):
tr_square = (M @ square.T).T
# Parallelogram
fig.add_trace(
go.Scatter(
x=tr_square[:,0], y=tr_square[:,1],
fill="toself",
fillcolor=fill_colors[j],
line=dict(color=sq_border_color, width=2 if j==0 else 1),
name="Parallelogram",
showlegend=False
),
row=1, col=j+1)
# Draw basis arrows for original and final panels, gray hidden arrows for intermediates
if show_arrows:
ux_t = M @ u_x
uy_t = M @ u_y
arrowwidth = 6 if j in [0,3] else 4
arrowdot = 10 if j in [0,3] else 7
vcolor = arrow_colors[j]
# Draw for u_x, u_y
for v, lbl in [(ux_t, r"$\vec u_x$"), (uy_t, r"$\vec u_y$")]:
# Main arrow line
fig.add_trace(go.Scatter(
x=[0, v[0]], y=[0, v[1]],
mode="lines",
line=dict(color=vcolor, width=arrowwidth, dash="solid" if j in [0,3] else "dot"),
showlegend=False,
hoverinfo="skip"
), row=1, col=j+1)
# Arrowhead as dot
fig.add_trace(go.Scatter(
x=[v[0]], y=[v[1]],
mode="markers",
marker=dict(size=arrowdot, color=vcolor, line=dict(width=1.2, color='white')),
showlegend=False,
hoverinfo="skip"
), row=1, col=j+1)
# Only draw labels on blue and orange panels, or always if desired
if show_labels and j in [0, 3]:
shift = 0.17 * (v / (np.linalg.norm(v)+1e-8))
fig.add_annotation(
text=lbl,
x=v[0] + shift[0], y=v[1] + shift[1],
font=dict(size=16, color=vector_label_color),
showarrow=False,
xanchor="left", yanchor="bottom",
row=1, col=j+1
)
# Add step label in bottom right corner for panels 1,2,3 (not 0)
if step_labels[j]:
xr = xaxis_range if isinstance(xaxis_range[0], (int, float)) else xaxis_range[j]
yr = yaxis_range if isinstance(yaxis_range[0], (int, float)) else yaxis_range[j]
x_pos = xr[0] + 0.86*(xr[1] - xr[0])
y_pos = yr[0] + 0.13*(yr[1] - yr[0]) - 2
fig.add_annotation(
text=step_labels[j],
x=x_pos, y=y_pos,
font=dict(size=20, color="rgba(100,100,100,0.85)", family="Palatino, serif"),
showarrow=False,
xanchor='right', yanchor='bottom',
row=1, col=j+1
)
# --- Add box around the entire figure ---
# We'll do this using a rectangle shape spanning the whole figure/plot coords.
# Use xref/yref 'paper' so it covers all subplots, with margin fudge.
fig.add_shape(
type="rect",
xref="paper",
yref="paper",
x0=0, y0=0,
x1=1, y1=1,
line=dict(color="black", width=2),
fillcolor='rgba(0,0,0,0)',
layer="above"
)
fig.update_layout(
font=dict(family="Palatino, serif", size=16),
plot_bgcolor="white",
paper_bgcolor="white",
# Whitespace reduced: smaller margins, smaller overall width
margin=dict(l=4, r=4, t=50, b=10),
width=940, height=325,
title=title
)
if return_fig:
return fig
fig.show(renderer='png', scale=2)
# Example usage:
A = np.array([[1, 2], [2, 1]])
eigvals, eigvecs = np.linalg.eigh(A)
Q = eigvecs
Lambda = np.diag(eigvals)
plot_unit_square_diag_process(
Q,
Lambda,
square_color="rgba(61,129,246,0.37)",
qt_color="rgba(255,140,0,0.31)",
# No need for lqt_color, qlqt_color; color ramp is used!
sq_border_color="rgba(255, 255, 255, 0)",
xaxis_range=[-1.5, 3.5],
yaxis_range=[1, 2],
title=r'$$\text{Visualizing } A = Q \Lambda Q^T$$',
show_labels=False,
names=[''] * 4
)
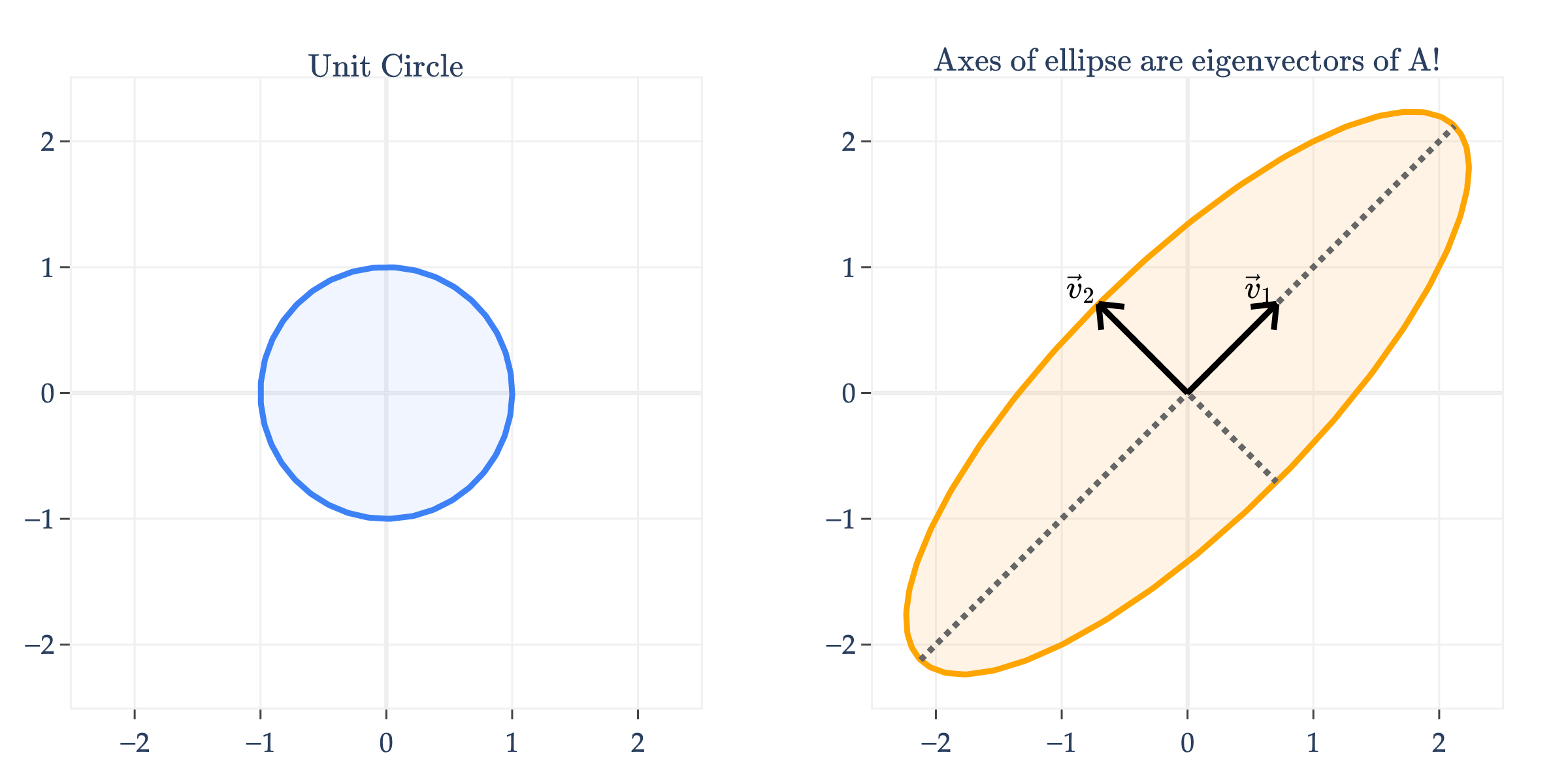
Another way of visualizing the linear transformation of a symmetric matrix is to consider its effect on the unit circle, not the unit square. Below, I’ll apply A=[1221] to the unit circle.
import numpy as np
import plotly.graph_objects as go
from plotly.subplots import make_subplots
def plot_unit_circle_and_transform(S, name="Matrix", show_eig=True, return_fig=False):
# Generate unit circle points
theta = np.linspace(0, 2 * np.pi, 300)
circle = np.vstack((np.cos(theta), np.sin(theta))).T
# Transformed circle (ellipse)
ellipse = (S @ circle.T).T
# Compute real eigenvalues and eigenvectors (for drawing axes)
try:
eigvals, eigvecs = np.linalg.eig(S)
except np.linalg.LinAlgError:
eigvals, eigvecs = None, None
# Only retain real-valued eigenvectors for the plot
real_mask = np.abs(np.imag(eigvals)) < 1e-8
real_eigvecs = np.real(eigvecs[:, real_mask])
real_eigvals = np.real(eigvals[real_mask])
# Normalize eigenvectors for plotting (unit)
if real_eigvecs.shape[1] > 0:
eigvec_norms = np.linalg.norm(real_eigvecs, axis=0)
eigvecs_dir = real_eigvecs / eigvec_norms
else:
eigvecs_dir = np.zeros((2,0))
# Set up figure
fig = make_subplots(
rows=1, cols=2,
subplot_titles=(r"$$\text{Unit Circle}$$", fr"$$\text{{Axes of ellipse are eigenvectors of A!}}$$"),
horizontal_spacing=0.08
)
# Common axis settings: [-2.5,2.5] for each
axis_style = dict(
showgrid=True,
gridcolor="#f0f0f0",
zeroline=False,
showline=True,
linecolor="#f0f0f0",
mirror=True,
ticks="outside",
showticklabels=True,
tickfont=dict(family="Palatino, serif", size=14),
)
# Apply axes settings to both; but you'll hide eigen-directions for left below
for i in [1, 2]:
fig.update_xaxes(
range=[-2.5, 2.5],
constrain="domain",
dtick=1,
**axis_style,
row=1, col=i
)
fig.update_yaxes(
range=[-2.5, 2.5],
scaleanchor=f"x{i}",
dtick=1,
**axis_style,
row=1, col=i
)
# Grid zero lines under all objects
for i in [1,2]:
fig.add_shape(
type="line",
x0=-2.5, x1=2.5, y0=0, y1=0,
line=dict(color="rgba(170,170,170,0.25)", width=2, dash="solid"),
row=1, col=i,
layer="below"
)
fig.add_shape(
type="line",
x0=0, x1=0, y0=-2.5, y1=2.5,
line=dict(color="rgba(170,170,170,0.25)", width=2, dash="solid"),
row=1, col=i,
layer="below"
)
# Left: unit circle (blue)
fig.add_trace(
go.Scatter(
x=circle[:,0], y=circle[:,1],
line=dict(color="#3d81f6", width=3),
fill="toself",
fillcolor="rgba(61,129,246,0.08)",
name="Unit Circle",
showlegend=False
),
row=1, col=1
)
# Right: transformed circle (ellipse, orange)
fig.add_trace(
go.Scatter(
x=ellipse[:,0], y=ellipse[:,1],
line=dict(color="orange", width=3),
fill="toself",
fillcolor="rgba(255,140,0,0.10)",
name="Transformed Circle",
showlegend=False
),
row=1, col=2
)
# Plot dotted lines for the (real) eigenvector directions
# Only show eigenvector axes on right plot, and make them longer and #333 gray
scale_left = 2.2 # keeps left here for compat but don't plot axes on left
scale_right_1 = 3 # extend axes more on right plot
scale_right_m1 = 1
eig_axis_color = "#666"
if show_eig and eigvecs_dir.shape[1] > 0:
for i in range(eigvecs_dir.shape[1]):
scale_right = scale_right_1 if i == 0 else scale_right_m1
v = eigvecs_dir[:,i]
# OMIT left side axes (ellipses axes, i.e. do NOT plot on left)
# Show extended axes just on right (further and gray)
for sign in [+1, -1]:
# Only on right plot (ellipse)
v_trans = S @ v
v_trans_norm = np.linalg.norm(v_trans)
if v_trans_norm > 1e-10:
v_trans_unit = v_trans / v_trans_norm
fig.add_trace(
go.Scatter(
x=[-scale_right * v_trans_unit[0], scale_right * v_trans_unit[0]],
y=[-scale_right * v_trans_unit[1], scale_right * v_trans_unit[1]],
mode="lines",
line=dict(color=eig_axis_color, width=3, dash="dot"),
name="Transformed Eigenvector",
hoverinfo="skip",
showlegend=False
),
row=1, col=2
)
# ---- Draw [1,1] and [-1,1] as black arrows on top of BOTH plots ----
arrow_vectors = [np.array([1, 1]) / np.sqrt(2), np.array([-1, 1]) / np.sqrt(2)]
arrow_colors = ['black', 'black']
arrow_names = [r"$[1, 1]$", r"$[-1, 1]$"]
arrow_length = 1 # scale for display
for col in [2]:
for idx, vec in enumerate(arrow_vectors):
# Normalize for direction
v = vec
x0, y0 = 0, 0
x1, y1 = arrow_length * v[0], arrow_length * v[1]
fig.add_trace(
go.Scatter(
x=[x0, x1],
y=[y0, y1],
mode="lines+markers",
line=dict(color=arrow_colors[idx], width=3),
marker=dict(size=1),
showlegend=False,
hoverinfo="skip"
),
row=1, col=col
)
# Custom arrowhead using add_shape for nice head
fig.add_shape(
type="line",
x0=x1-0.16*v[0]-0.13*v[1], y0=y1-0.16*v[1]+0.13*v[0], x1=x1, y1=y1,
line=dict(color=arrow_colors[idx], width=3),
row=1, col=col,
layer="above"
)
fig.add_shape(
type="line",
x0=x1-0.16*v[0]+0.13*v[1], y0=y1-0.16*v[1]-0.13*v[0], x1=x1, y1=y1,
line=dict(color=arrow_colors[idx], width=3),
row=1, col=col,
layer="above"
)
# Optionally add annotation at tip for column 1
# Only show for one arrow to not clutter
if col == 2:
fig.add_annotation(
x=x1, y=y1,
text=fr"$$\vec v_{{{idx+1}}}$$",
showarrow=False,
font=dict(color='black', size=16),
row=1, col=col,
yanchor="bottom",
xanchor="right"
)
fig.update_layout(
font=dict(family="Palatino, serif", size=16),
plot_bgcolor="white",
paper_bgcolor="white",
margin=dict(l=20, r=20, t=40, b=20),
width=800, height=400,
)
if return_fig:
return fig
fig.show(renderer='png', scale=3)
# Example usage:
A = np.array([[1, 2], [2, 1]])
plot_unit_circle_and_transform(A, name="A")
Notice that A transformed the unit circle into an ellipse. What’s more, the axes of the ellipse are the eigenvector directions of A!
Why is one axis longer than the other? As you might have guessed, the longer axis – the one in the direction of the eigenvector v1=[11] – corresponds to the larger eigenvalue. Remember that A has λ1=3 and λ2=−1, so the “up and to the right” axis is three times longer than the “down and to the right” axis, defined by v2=[1−1].
To see why this happens, consult the solutions to Lab 11, Activity 6b to try and derive it. It has to do with the expression ∑i=1nλiyi2’s in that derivation. What are the λi’s and where did the yi’s come from?
I will keep this section brief; this is mostly meant to be a reference for a specific definition that you used in Lab 11 and will use in Homework 10.
What does this have anything to do with the diagonalization of a matrix? We just spent a significant amount of time talking about the special properties of symmetric matrices, and positive semidefinite matrices are a subset of symmetric matrices, so the properties implied by the spectral theorem also apply to positive semidefinite matrices.
Positive semidefinite matrices appear in the context of minimizing quadratic forms, f(x)=xTAx. You’ve toyed around with this in Lab 11, but also note that in Chapter 4.1 we saw the most important quadratic form of all: the mean-squared error!
this involves a quadratic formRsq(w)=n1∥y−Xw∥2
If we know all of the eigenvalues of A in xTAx are non-negative, then we know that xTAx≥0 for all x, meaning that the quadratic form has a global minimum. This is why, as discussed in Lab 11, the quadratic form xTAx is convex if and only if A is positive semidefinite.
The fact that having non-negative eigenvalues implies the first definition of positive semidefiniteness is not immediately obvious, but is exactly what we proved in Lab 11, Activity 6.
A positive definite matrix is one in which xTAx>0 for all x=0, i.e. where all eigenvalues are positive, not just non-negative (0 is no longer an option).
The eigenvalue decomposition of a matrix A is a decomposition of the form
A=VΛV−1
where V is a matrix containing the eigenvectors of A as columns, and Λ is a diagonal matrix of eigenvalues in the same order. Only diagonalizable matrices can be decomposed in this way.
The algebraic multiplicity of an eigenvalue λi is the number of times λi appears as a root of the characteristic polynomial of A.
The geometric multiplicity of λ is the dimension of the eigenspace of λ, i.e. dim(nullsp(A−λI)).
The n×n matrix is diagonalizable if and only if any of these equivalent conditions are true:
A has n linearly independent eigenvectors.
For every eigenvalue λi, GM(λi)=AM(λi).
A has n distinct eigenvalues.
When A is diagonalizable, it has an eigenvalue decomposition, A=VΛV−1.
If A is a symmetric matrix, then the spectral theorem tells us that A can be diagonalized by an orthogonal matrix Q such that
A=QΛQT
and that all of A’s eigenvalues are guaranteed to be real.
What’s next? There’s the question of how any of this relates to real data. Real data comes in rectangular matrices, not square matrices. And even it were square, how does any of this enlighten us?