In Chapter 8.1, we learned about the gradient, the equivalent of the derivative for vector-to-scalar functions. The big takeaway was that ∇f(x) describes the direction in which f is increasing the quickest, at the point x.
At the end of Chapter 8.1, we minimized
Rsq(w)=n1∥y−Xw∥2
by computing its gradient, setting it to 0, and solving for w∗, which gave us another way of deriving the normal equations.
So far, most of the empirical risk functions that we’ve minimized had closed-form solutions – that is, formulas for the optimal parameters w0∗,w1∗,... that we could find by hand using algebra.
But, soon we’ll encounter combinations of models and loss functions whose empirical risk functions that have some global minimum, but that global minimum isn’t described by a formula that we can write by hand. There was an example of such an empirical risk function from a previous homework; see if you can remember what it was!
As another example, the logistic regression model, used for predicting the probability of a binary event (e.g. whether or not a patient has a disease) makes predictions using
h(xi)=P(yi=1∣xi)=1+e−w⋅Aug(xi)1
Logistic regression typically uses the cross-entropy loss function,
Rce(w) is a vector-to-scalar function, and it has a gradient, ∇Rce(w). The issue is that the solutions to ∇Rce(w)=0 can’t be found by hand. But, ∇Rce(w) still means something – and we can use it to estimate w∗ without solving for it explicitly.
Throughout this section, keep the following thought exercise in mind:
Suppose you’re at the top of a mountain 🏔️ and need to get to the bottom. And, perhaps it’s really cloudy ☁️, meaning you can only see a few feet around you. How would you get to the bottom?
There are some not-so-elegant techniques for minimizing f. For instance, we could evaluate f at dozens (or hundreds) of possible x’s, and pick the one that had the smallest output. But, that’s an inefficient way to go about things, especially as the number of input variables (i.e. the d in x∈Rd) increases.
Instead, we’ll use the fact that f is differentiable. Its derivative is
dxdf(x)=20x3−3x2−10x+2
Typically, to minimize f, we’d
Find dxdf(x).
Solve for the input x∗ such that dxdf(x∗)=0.
But, dxdf(x)=0 is a cubic equation, which is difficult to solve by hand (there is actually a “cubic formula”, the same way there’s a “quadratic formula”, but higher-degree polynomials don’t have similar formulas). What can we do with its derivative?
The key idea is that we’ll take an iterative approach. Suppose we start with an initial guess for x∗, say, x(0).
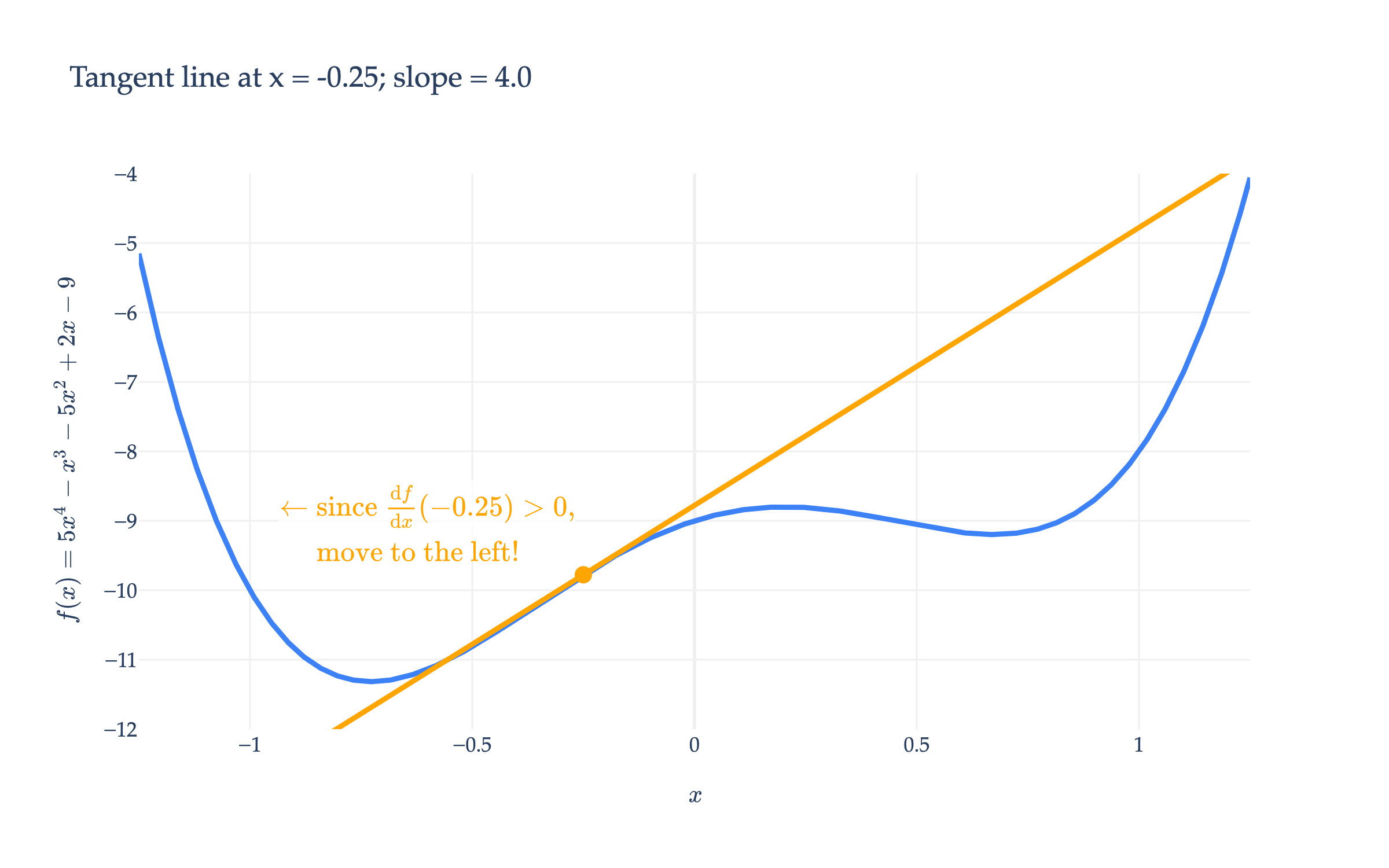
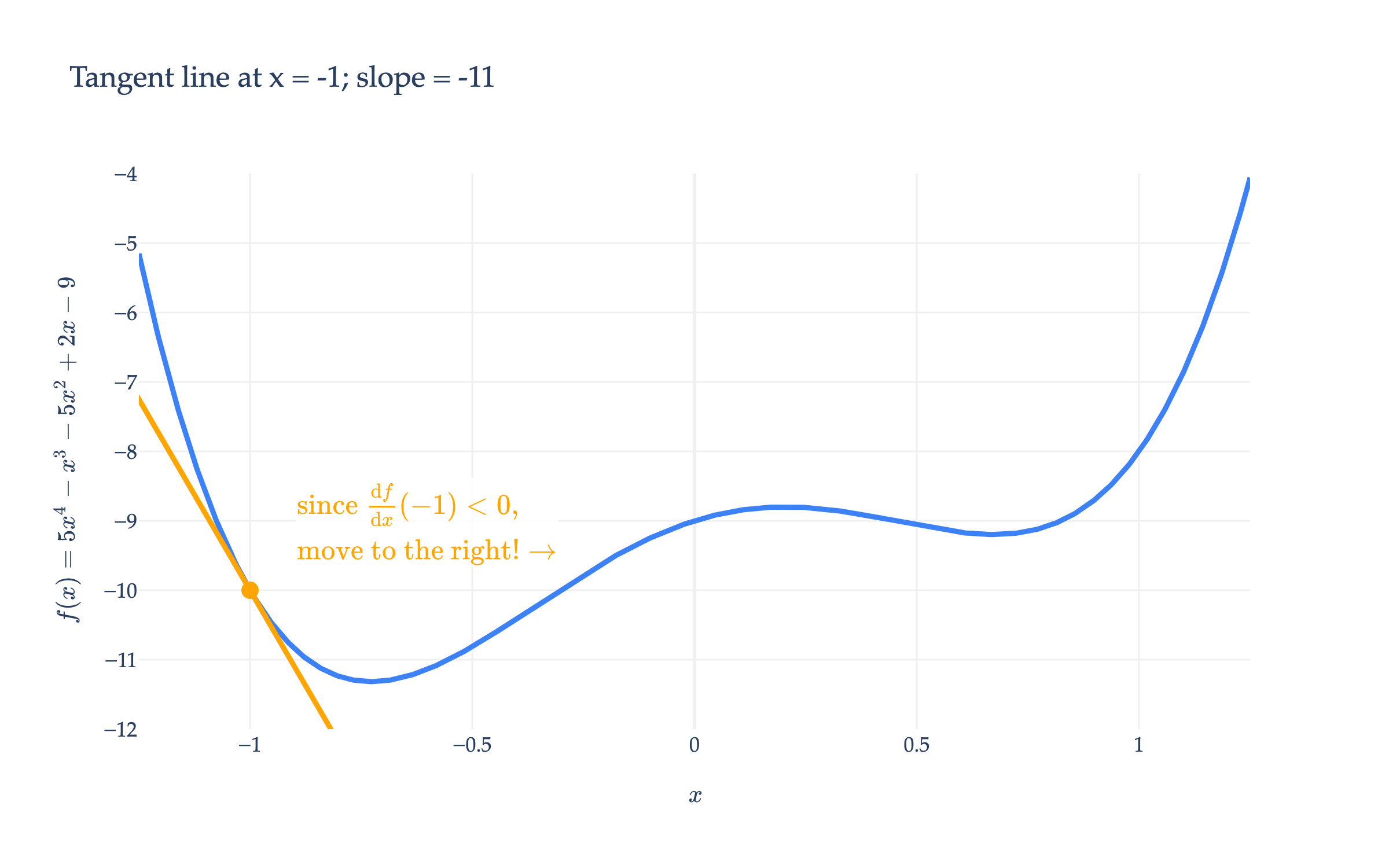
Case 1: If the derivative at x(0) is positive ⬆️, then f is increasing at x(0), which means to decrease f, we should move to the left of x(0).
Remember that at a minimum (or maximum), the derivative is 0 (if it exists), and gradually approaches 0, at least for the types of functions we’ll consider. So, if the derivative at our current guess is large, we must be far away from a minimum, and should take a larger step than if the derivative is small (which must mean we’re close to the minimum already).
This intuition is the basic idea behind gradient descent. The fact that “gradient” is in the name implies that it’s typically used for minimizing vector-to-scalar functions f:Rd→R, which we will use it for shortly. I just figured a scalar-to-scalar example would help build intuition.
Gradient descent is a numerical method for finding the input to a function f that minimizes the function. Ultimately, that’s what this is about: minimizing functions.
A numerical method is a technique for approximating the solution to a mathematical problem, often by using the computer. Since it only involves first (partial) derivatives, it’s called a first-order method; numerical methods that use second (partial) derivatives are called second-order methods.
Gradient descent is the workhorse of machine learning. As I stated earlier, it’s used to minimize empirical risk, R(w), in the general case, where it can’t be minimized by hand. (In the first few examples we’ll see, we’ll use gradient descent to minimize arbitrary functions of the form f(x), but in Chapter 8.4 we’ll return to minimizing empirical risk functions specifically.) This is especially true for state-of-the-art models, like neural networks and transformers, which have billions of parameters. So, when you hear about companies spending billions of dollars on training models, they’re spending money to run gradient descent on their oceans of data and models with billions of parameters.
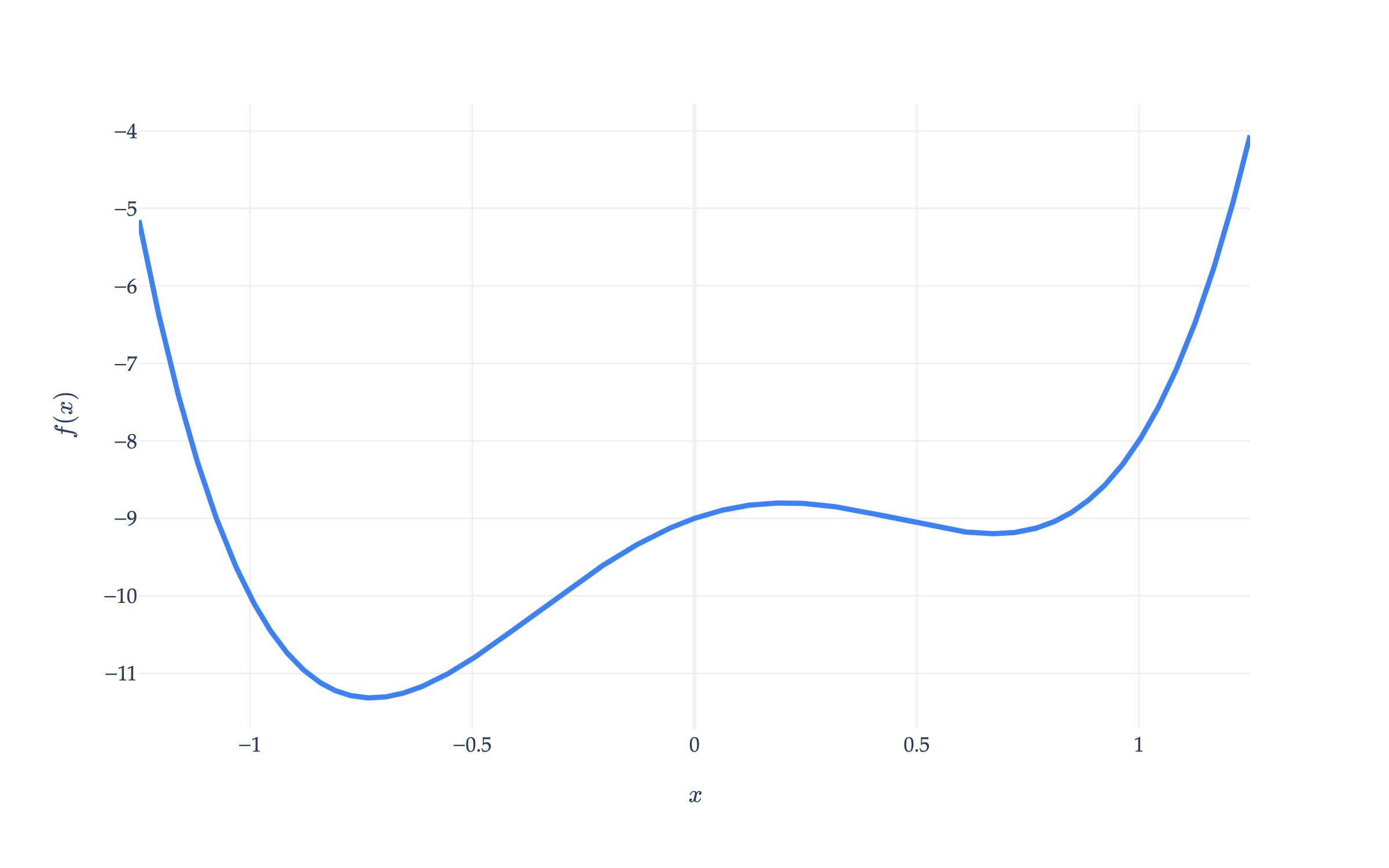
To get a feel for how it works, let’s implement gradient descent ourselves on the scalar-to-scalar function we looked at earlier,
f(x)=5x4−x3−5x2+2x−9,dxdf(x)=20x3−3x2−10x+2
For scalar-to-scalar functions, we can replace the gradient with the derivative, and the update rule becomes
x(t+1)=x(t)−αdxdf(x(t))
Let’s start with an initial guess of x(0)=0 and a learning rate of α=0.01.
def df(x):
return 20 * (x**3) - 3 * (x**2) - 10 * x + 2
def minimize_f(x0, alpha, tol=0.0001):
x = x0 # Initial guess
t = 0 # Iteration counter (just for tracking)
while np.abs(df(x)) > tol:
# The core logic is in this one line
x = x - alpha * df(x)
# Everything below is for us to track the progress of the algorithm
t += 1
if t % 10 == 0:
print(f't = {t}: x = {x}, df/dx = {df(x)}')
print(f"Converged in {t} iterations")
minimize_f(x0=0, alpha=0.01)
t = 10: x = -0.3019961066782706, df/dx = 4.195505266352445
t = 20: x = -0.6539833552473451, df/dx = 1.6626527284020556
t = 30: x = -0.7227462183452047, df/dx = 0.10967130332536357
t = 40: x = -0.7267760078170167, df/dx = 0.005439315124045052
t = 50: x = -0.7269745284952817, df/dx = 0.0002654471448240159
Converged in 54 iterations
With our initial guess of x(0)=0 and a learning rate of α=0.01, the algorithm converges to x∗≈−0.727 in 54 iterations.
Let’s visualize the execution of the algorithm on this f(x), with several different choices of initial guess and learning rate. In each animation, click the “▶️ Start animation” button to see the algorithm in action. (If the algorithm stops somewhere that isn’t a minimum, it’s because I set them to only show 50 iterations.)
Initial guess = 0, step size = 0.01
def minimizing_animation(x0, alpha):
play_button = {'label': '▶️ Start animation', 'method': 'animate', 'args': [None]}
stop_button = dict(label='⏯️ Stop animation', method='animate', visible = True,
args=[(), {'frame': {'duration': 0, 'redraw': False}, 'mode': 'next', 'fromcurrent': True}])
x = x0
xs = []
dfxs = []
for t in range(50):
xs.append(x)
dfxs.append(df(x))
x = x - alpha * df(x)
fig = draw_f()
# Extract layout and background from fig to preserve styling
base_layout = fig.layout
grad_anim = go.Figure(
data=[
fig.data[0],
go.Scatter(
x=[xs[0]], y=[f(xs[0])],
marker={'size': 20, 'color': 'orange'}, showlegend=False
)
],
frames=[
go.Frame(
data=[
fig.data[0],
go.Scatter(
x=[xs[t]], y=[f(xs[t])],
marker={'size': 20, 'color': 'orange'}, showlegend=False
)
]
)
for t in range(50)
],
layout=go.Layout(
updatemenus=[dict(
type="buttons",
buttons=[play_button, stop_button])],
# title=fr'$\text{{Gradient Descent on }} f(x) = 5x^4 - x^3 - 5x^2 + 2x - 9 \\ \text{{Initial Guess = }} x^{{(0)}} = \mathbf{{{x0}}}; \:\:\:\: \text{{Step Size = }} \alpha = \mathbf{{{alpha}}}$',
xaxis=base_layout.xaxis,
yaxis=base_layout.yaxis,
template=base_layout.template if 'template' in base_layout else None,
plot_bgcolor=base_layout.plot_bgcolor if 'plot_bgcolor' in base_layout else "#fff",
paper_bgcolor=base_layout.paper_bgcolor if 'paper_bgcolor' in base_layout else "#fff",
font=base_layout.font if 'font' in base_layout else None,
xaxis_title='𝑥',
yaxis_title='f(𝑥)',
margin=dict(t=0) # Set top margin negative
)
)
grad_anim.update_layout(width=700, height=400)
return grad_anim
minimizing_animation(x0=0, alpha=0.01)
Loading...
The algorithm converges to the true global minimum, but it takes a while.
What if we choose a different initial guess?
Initial guess = 1.1, step size = 0.01
minimizing_animation(x0=1.1, alpha=0.01)
Loading...
Uh oh: the algorithm gets trapped in a local minimum that isn’t the global minimum! From its perspective, local and global minima are the same, in that they have derivatives of 0. Gradient descent doesn’t seem well-suited for functions with multiple local minima.
What if we try a different step size?
Initial guess = 1.1, step size = 0.1
minimizing_animation(x0=1.1, alpha=0.1)
Loading...
At first, seemingly by luck, the algorithm jumps over to the neighborhood of the global minimum. But our step size appears to be too large, causing the algorithm to keep jumping back and forth across the global minimum.
The choice of step size is critical. In future courses, you may encounter some theoretical results that give you insight on how to choose the step size, but in practice, we often just try different step sizes and see what works. Another technique is to choose a decaying learning rate, in which the value of α decreases over time.
Note that I’ve chosen a function f:R2→R, since the resulting function exists in three dimensions, which is the largest space we can visualize. If f took in vectors with 3, or 4, or more components, we couldn’t visualize how gradient descent operations on it.
That said, we’ll visualize f(x) in two ways: as a surface and as a contour plot. (Remember, you should think of the latter as a “birds-eye view” of the former.)
This is the type of function that gradient descent is often used on in practice: functions with multiple (remember, billions! of) input variables, often with local minima.
We can see that f(x) has a global minimum around x∗≈[−0.60]. But, computers don’t have eyes, and instead need to rely on gradient descent. Recall, gradient descent updates are given by
Just to make sure we’re 100% on the same page, even though we have a formula for f’s gradient, the reason we’re using gradient descent is that it is impossible to solve for the vector x∗ where ∇f(x∗)=0 by hand: the algebra doesn’t work.
x(t) converged to a local minimum, of which there are many in this function. Also, notice that this step size (α=0.1) worked here even though a step size that large caused the earlier polynomial example to diverge. There is no universal best step size.
Remember not to rely too heavily on visual intuition, since practical examples will take us into higher dimensions, where we can’t visualize. But I think both the surface and contour plots are helpful.
Given an initial guess of x(0)=[00] and a step size of α=31, perform two iterations of gradient descent. What is x(2)?
It seems that the ability for gradient descent to converge on the global minimum depends on lots of factors:
The existence of “traps” – that is, local minima that aren’t the global minimum.
The step size, α.
The initial guess.
If there are no local minima, then gradient descent will converge to the global minimum, given a sufficiently small step size. The type of function that has no local minima is called convex. Intuitively, a convex function has a “bowl-like” shape, as you have seen in calculus. In Chapter 8.5, we’ll study the idea of convexity in more detail.