We now know that:
The mean is the constant prediction that minimizes mean squared error.
The median is the constant prediction that minimizes mean absolute error.
Let’s compare the behavior of the mean and median, and reason about how their differences in behavior are related to the differences in the loss functions used to derive them.
Outliers and Balance¶
Let’s consider our example dataset of 5 commute times, with a mean of 85 and median of 80:
Suppose 200 is added to the largest commute time:
The median is still 85, but the mean is now . This example illustrates the fact that the mean is sensitive to outliers, while the median is robust to outliers.
But why? I like to think of the mean and median as different “balance points” of a dataset, each satisfying a different “balance condition”.
| Summary Statistic | Minimizes | Balance Condition (comes from setting ) |
|---|---|---|
| Median | ||
| Mean |
In both cases, the “balance condition” comes from setting the derivative of empirical risk, , to 0. The logic for the median and mean absolute error is more fresh from this section, so let’s think in terms of the mean and mean squared error, from Chapter 1.2. There, we found that:
Setting this to 0 gave us the balance equation above.
In English, this is saying that the sum of deviations from each data point to the mean is 0. (“Deviation” just means "difference from the mean.) Or, in other words, the positive differences and negative differences cancel each other out at the mean, and the mean is the unique point where this happens.
Let me illustrate using our familiar small example dataset.
The mean is 80. Then:
Note that the negative deviations and positive deviations both total 27 in magnitude.
While the mean balances the positive and negative deviations, the median balances the number of points on either side, without regard to how far the values are from the median.
Here’s another perspective: the squared loss more heavily penalizes outliers, and so the resulting predictions “cater to” or are “pulled” towards these outliers.
We just derived the absolute-loss solution for the constant model; now we’ll compare it to squared loss and examine how the choice of loss changes what “best” means.
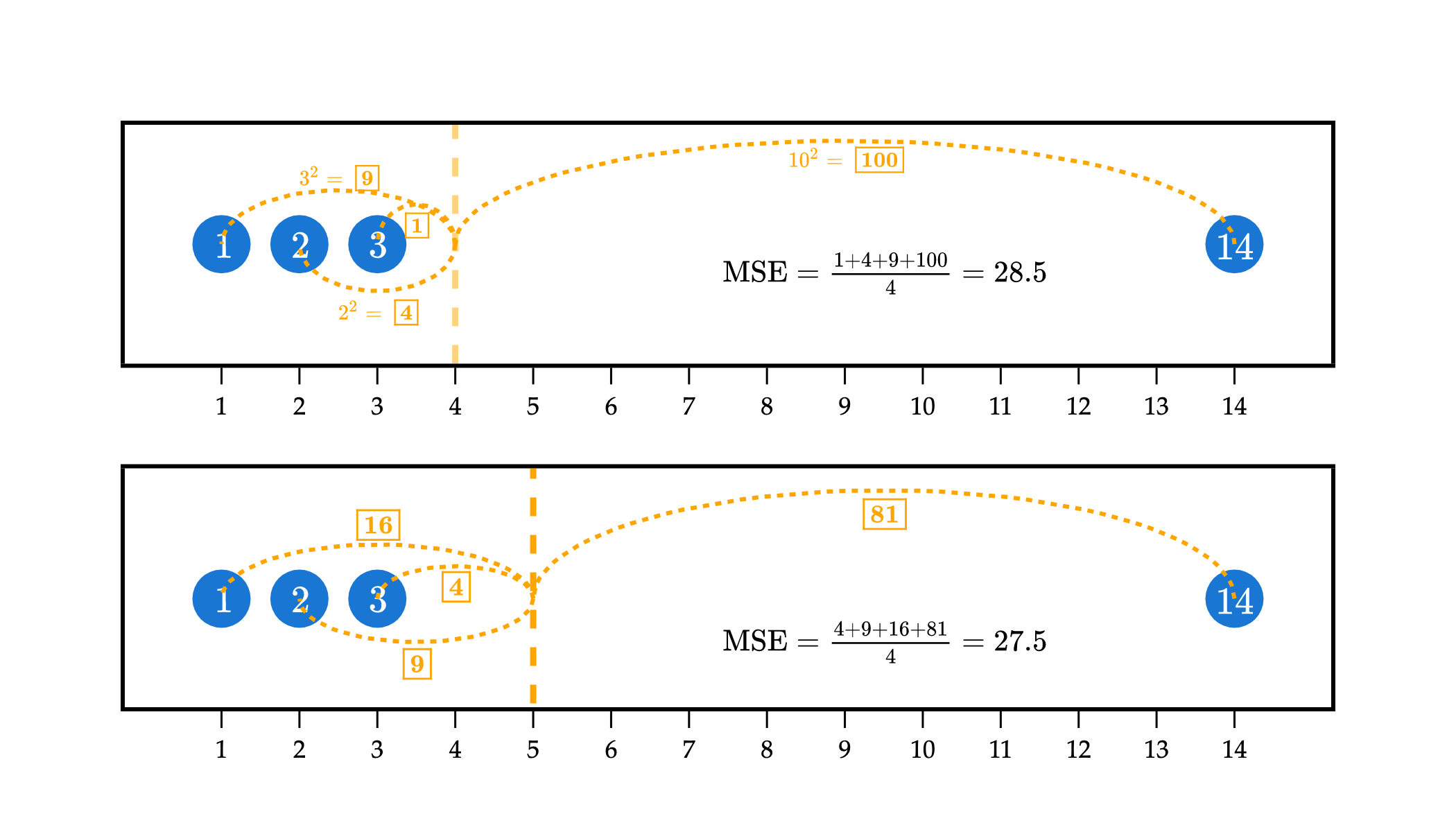
In the example above, the top plot visualizes the squared loss for the constant prediction of against the dataset 1, 2, 3, and 14. While it has relatively small squared losses to the three points on the left, it has a very large squared loss to the point at 14, of , which causes the mean squared error to be large.
In efforts to reduce the overall mean squared error, the optimal is pulled towards 14. has larger squared losses to the points at 1, 2, and 3 than did, but a much smaller squared loss to the point at 14, of . The “savings” from going from a squared loss of to more than makes up for the additional squared losses to the points at 1, 2, and 3.
In short: models that are fit using squared loss are strongly pulled towards outliers, in an effort to keep mean squared error low. Models fit using absolute loss don’t have this tendency.
To conclude, let me visualize the behavior of the mean and median with a larger dataset – the full dataset of commute times we first saw at the start of Chapter 1.2.
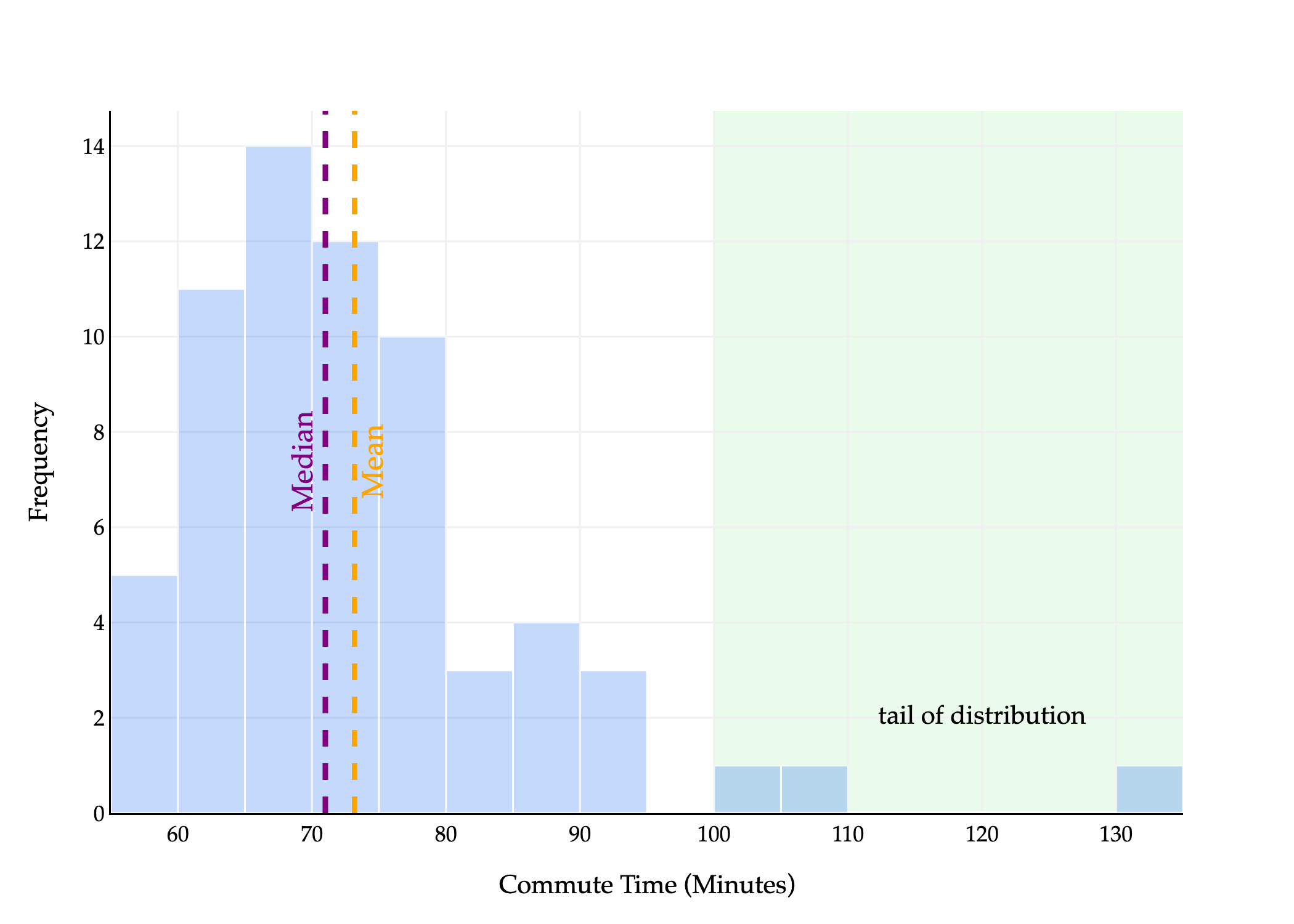
The median is the point at which half the values are below it and half are above it. In the histogram above, half of the area is to the left of the median and half is to the right.
The mean is the point at which the sum of deviations from each value to the mean is 0. Another interpretation: if you placed this histogram on a playground see-saw, the mean would be the point at which the see-saw is balanced. Wikipedia has a good illustration of this general idea.
We say the distribution above is right-skewed or right-tailed because the tail is on the right side of the distribution. (This is counterintuitive to me, because most of the data is on the left of the distribution.)
In general, the mean is pulled in the direction of the tail of a distribution:
If a distribution is symmetric, i.e. has roughly the same-shaped tail on the left and right, the mean and median are similar.
If a distribution is right-skewed, the mean is pulled to the right of the median, i.e. .
If a distribution is left-skewed, the mean is pulled to the left of the median, i.e. .
This explains why in the histogram above, and equivalently, in the scatter plot below.
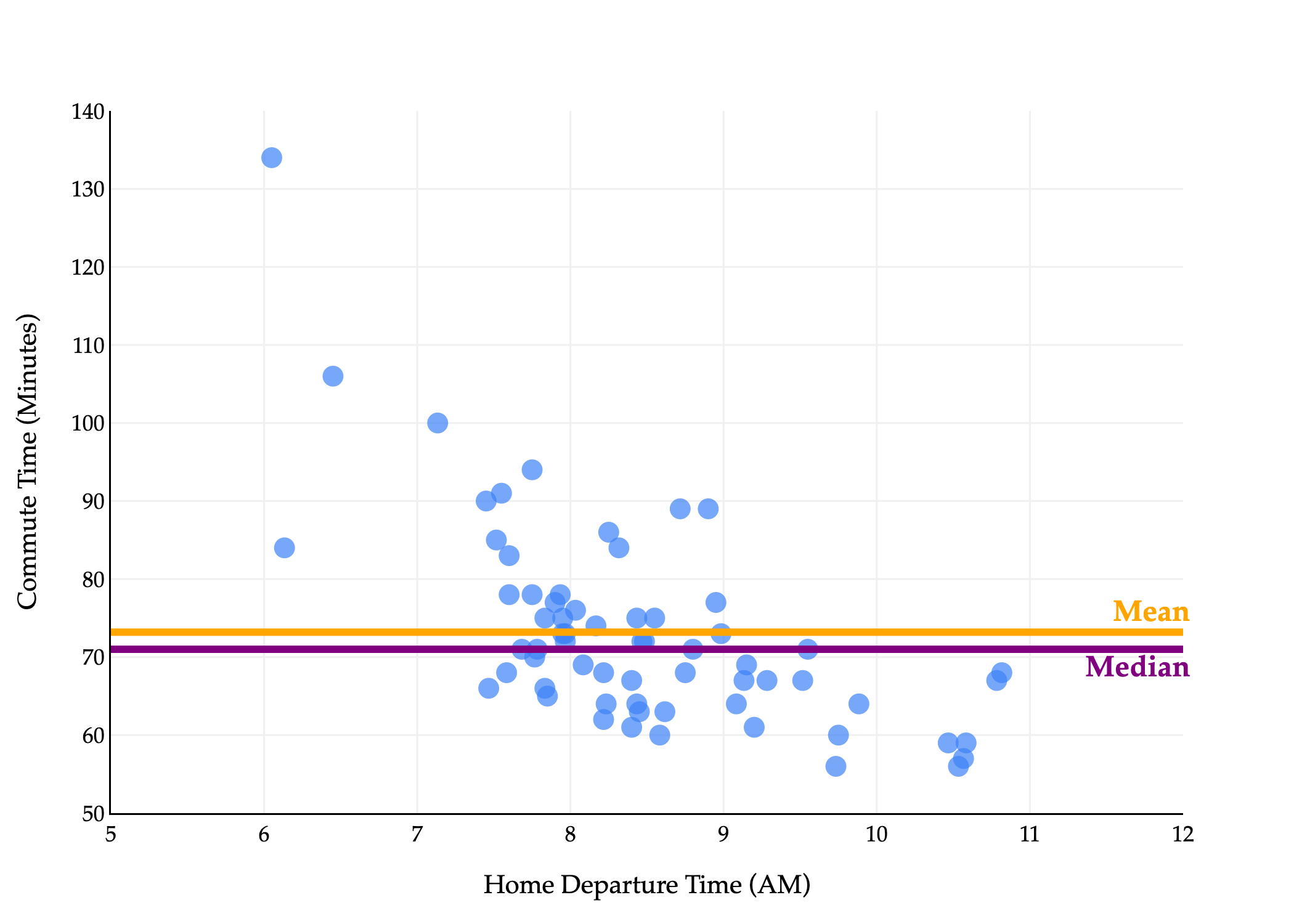
Many common distributions in the real world are right-skewed, including incomes and net worths, and in such cases, the mean doesn’t tell the full story.
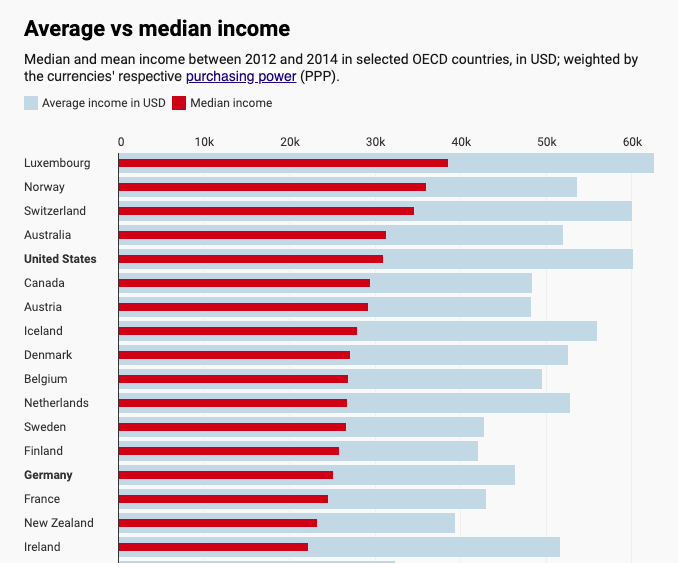
Mean (average) and median incomes for several countries (source).
When we move to more sophisticated models with (many) more parameters, the optimal parameter values won’t be as easily interpretable as the mean and median of our data, but the effects of our choice of loss function will still be felt in the predictions we make.
Beyond Absolute and Squared Loss¶
You may have noticed that the absolute loss and squared loss functions both look relatively similar:
Both of these loss functions are special cases of a more general class of loss functions, known as loss functions. For any , define the loss as follows:
Suppose we continue to use the constant model, . Then, the corresponding empirical risk for loss is:
We’ve studied, in depth, the minimizers of for (the median) and (the mean). What about when , or , or ? What happens as ?
Let me be a bit less abstract. Suppose we have . Then, we’re looking for the constant prediction that minimizes the following:
Note that I dropped the absolute value, because is always non-negative, since 6 is an even number.
To find here, we need to take the derivative of with respect to and set it equal to 0.
Setting the above to 0 gives us a new balance condition: . The minimizer of was the point at which the balance condition was satisfied; equivalently, the minimizer of is the point at which the balance condition is satisfied. You’ll notice that the degree of the differences in the balance condition is one lower than the degree of the differences in the loss function --- this comes from the power rule of differentiation.
At what point does ? It’s challenging to determine the value by hand, but the computer can approximate solutions for us, as you’ll see in Lab 2.
Below, you’ll find a computer-generated graph where:
The -axis is .
The -axis represents the value of that minimizes , for the dataset
that we saw earlier. Note the maximum value in our dataset is 292.
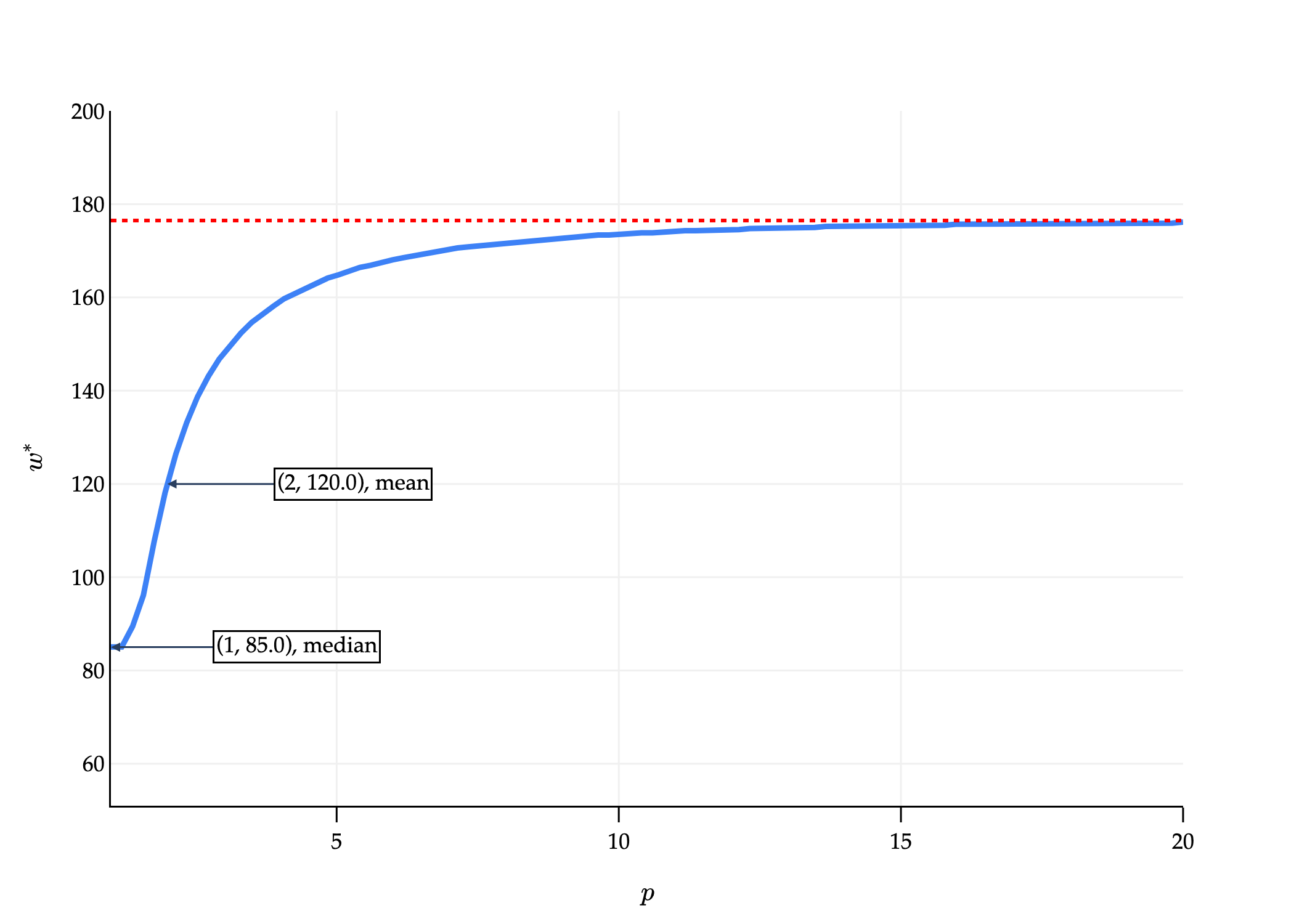
As , approaches some value.
Activity 1¶
Activity 1
As , what value does approach, and why?
Solution
As , approaches:
Intuitively, as , we’re minimizing the worst-case distance to any point in the dataset, i.e. the maximum distance to any point in the dataset. To keep the maximum distance as small as possible, we need to be directly in between the two extreme points of the dataset. Think of this as a “tug-of-war” between the minimum and maximum values of the dataset.
On the other extreme end, let me introduce yet another loss function, 0-1 loss:
The corresponding empirical risk, for the constant model , is:
This is the sum of 0s and 1s, divided by . A 1 is added to the sum each time . So, in other words, is:
To minimize empirical risk, we want the number of points not equal to to be as small as possible. So, is the mode (i.e. most frequent value) of the dataset. If all values in the dataset are unique, they all minimize average 0-1 loss. This is not a useful loss function for regression, since our predictions are drawn from the continuous set of real numbers, but is useful for classification.
Center and Spread¶
Prior to taking EECS 245, you knew about the mean, median, and mode of a dataset. What you now know is that each one of these summary statistics comes from minimizing empirical risk (i.e. average loss) for a different loss function. All three measure the center of the dataset in some way.
| Loss | Minimizer of Empirical Risk | Always Unique? | Robust to Outliers? | Empirical Risk Differentiable? |
|---|---|---|---|---|
| mean | yes ✅ | no ❌ | yes ✅ | |
| median | no ❌ | yes ✅ | no ❌ | |
| midrange | yes ✅ | no ❌ | no ❌ | |
| mode | no ❌ | no ❌ | no ❌ |
So far, we’ve focused on finding model parameters that minimize empirical risk. But, we never stopped to think about what the minimum empirical risk itself is! Consider the empirical risk for squared loss and the constant model:
is minimized when is the mean, which I’ll denote with . What happens if I plug back into ?
This is the variance of the dataset ! The variance is nothing but the average squared deviation of each value from the mean of the dataset.
This gives context to the -axis value of the vertex of the parabola we saw in Chapter 1.2.
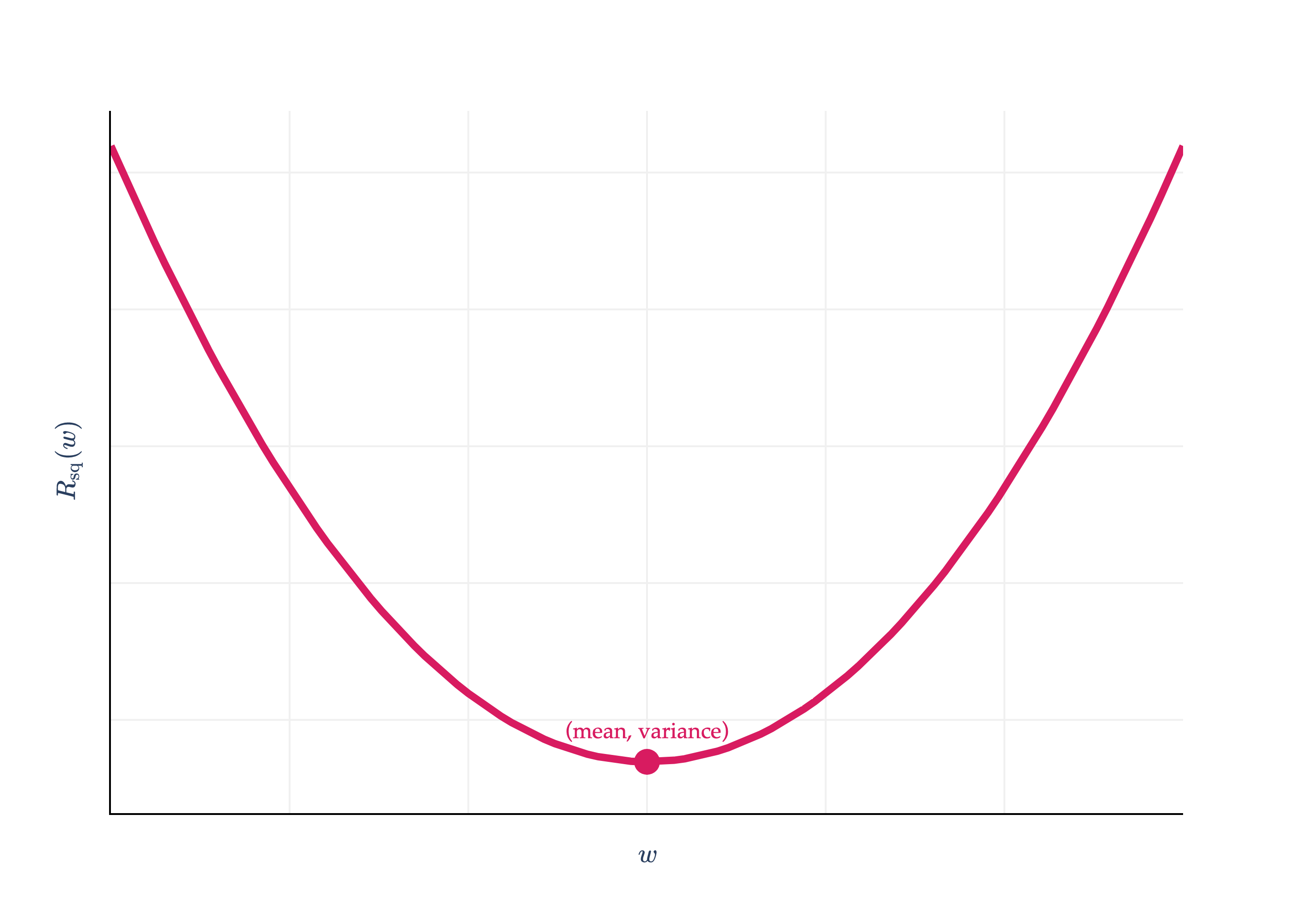
Practically speaking, this gives us a nice “worst-case” mean squared error of any regression model on a dataset. If we learn how to build a sophisticated regression model, and its mean squared error is somehow greater than the variance of the dataset, we know that we’re doing something wrong, since we could do better just by predicting the mean!
The units of the variance are the square of the units of the -values. So, if the ’s represent commute times in minutes, the variance is in . This makes it a bit difficult to interpret. So, we typically take the square root of the variance, which gives us the standard deviation, :
The standard deviation has the same units as the -values themselves, so it’s a more interpretable measure of spread.
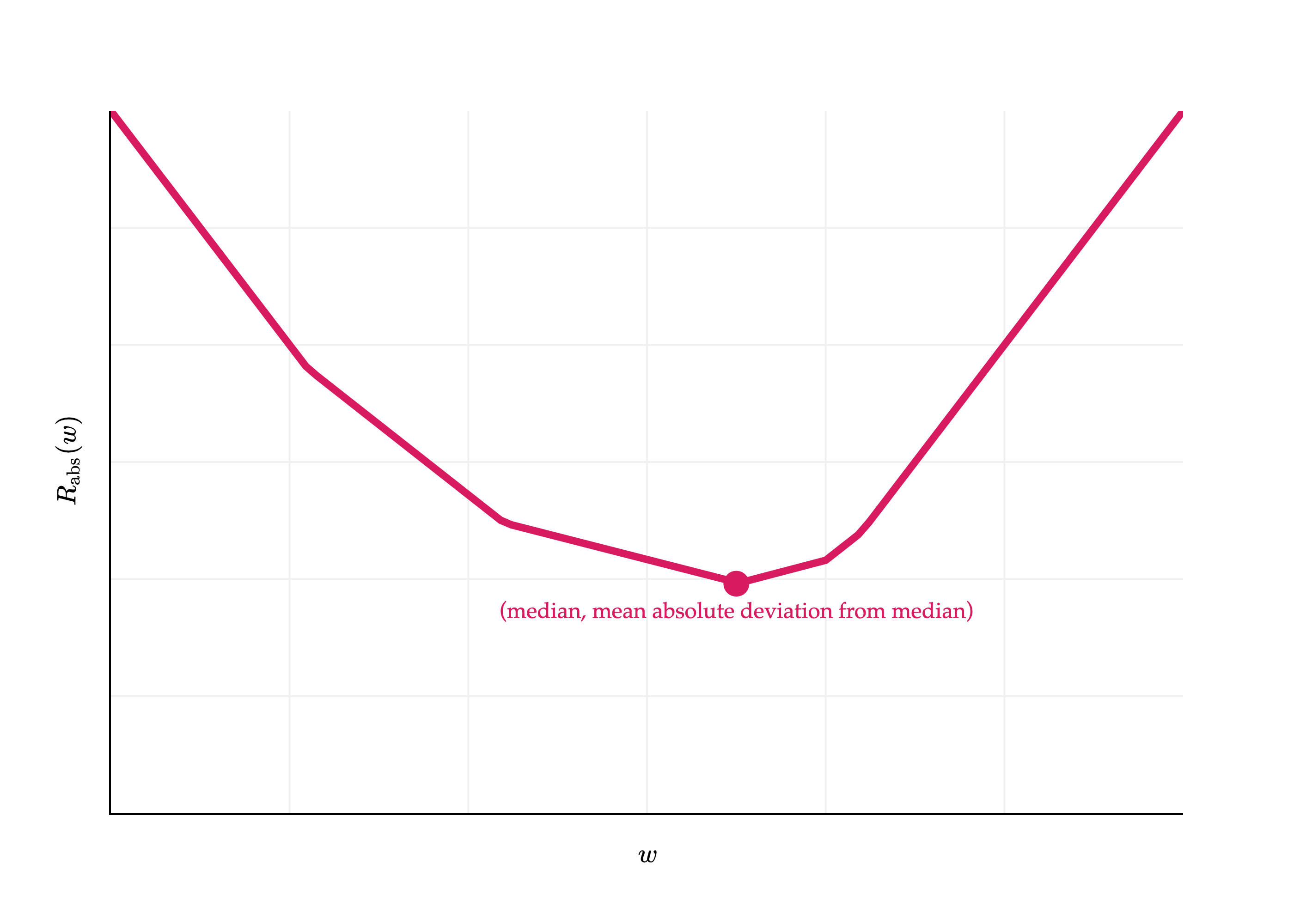
How does this work in the context of absolute loss?
Plugging in into gives us:
I’ll admit, this result doesn’t have a special name. It is the mean absolute deviation from the median. And, like the variance and standard deviation, it measures roughly how far spread out the data is from its center. Its units are the same as the -values themselves (since there’s no squaring involved).
Activity 2¶
Activity 2
Consider the dataset:
Compute the following:
The variance.
The mean squared error of the median.
The mean absolute deviation from the median.
The mean absolute deviation from the mean.
What do you notice about the results to (1) and (2)? What about the results to (3) and (4)?
In the real-world, be careful when you hear the term “mean absolute deviation”, as sometimes it’s used to refer to the median absolute deviation from the mean, not the median as above.
Activity 3¶
Activity 3
What is the value of for the constant model and 0-1 loss? How does it measure the spread of the data?
To reiterate, in practice, our models will have many, many more parameters than just one, as is the case for the constant model. But, by deeply studying the effects of choosing squared loss vs. absolute loss vs. other loss functions in the context of the constant model, we can develop a better intuition for how to choose loss functions in more complex situations.