Overview¶
In Chapter 9 – which will last us the majority of the remainder of the semester – we’re going to introduce a new lens through which we can view the information stored in a matrix: through its eigenvalues and eigenvectors. As Gilbert Strang says in his book, eigenvalues and eigenvectors allow us to look into the “heart” of a matrix and see what it’s really doing.
Throughout this chapter, we’ll see how eigen-things can help us more deeply understand the topics we’ve already covered, like linear regression, the normal equations, gradient descent, and convexity.
The eigenvalues of the Hessian matrix (matrix of partial second derivatives) of a vector-to-scalar function will tell us whether or not the function is convex, i.e. they will give us a “second derivative test” for vector-to-scalar functions, which we haven’t yet seen.
Eigenvalues will explain why the matrix is always invertible, even if ’s columns aren’t linearly independent.
And eventually, in Chapter 10.4, we’ll use eigenvalues and eigenvectors to address the dimensionality reduction problem, first introduced in Chapter 1.1.
On top of all of that, eigenvalues and eigenvectors will unlock a new set of applications – those that involve some element of time. My favorite such example is Google’s PageRank algorithm. The algorithm, first published in 1998 by Sergey Brin and Larry Page (Google’s cofounders, the latter of whom is a Michigan alum), is used to rank pages on the internet based on their relative importance.
From the research paper linked above:
PageRank or PR(A) can be calculated using a simple iterative algorithm, and corresponds to the principal eigenvector of the normalized link matrix of the web.
We’ll make sense of the algorithm in Homework 10: just know that this is where we’re heading.
Introduction¶
Before we get started, keep in mind that everything we’re about to introduce only applies to square matrices. This was also true when we first studied invertibility, and for the same reason: we should think of eigenvalues and eigenvectors as properties of a linear transformation from to (that is, from a vector space to itself), not between vector spaces of different dimensions. Rectangular matrices will have their moment in Chapter 10.1.
This definition is a bit hard to parse when you first look at it. But here’s the intuitive interpretation.
“Eigen” is a German word meaning “own”, as in “one’s own”. So, an eigenvector is a vector who still points in its own direction when transformed by .
A First Example¶
Let’s start with a matrix:
I’ve chosen the numbers in to be small enough that we can roughly eyeball the eigenvectors. Here’s how I look at :
First, notice that both rows of sum to 3, meaning that
This tells me that is an eigenvector of with eigenvalue 3. But, is also an eigenvector of with the same eigenvalue, since
Indeed, if is an eigenvector of with eigenvalue , then so is for any non-zero scalar . So really, eigenvectors define directions.
Additionally, noticing that there’d be some symmetry if I took the difference of the entries in each row of , consider
This tells me that is an eigenvector of with eigenvalue -1.
So, has two eigenvalues, 3 and -1, and two corresponding eigenvectors, and . In general, an matrix has eigenvalues, but some of them may be the same, and some of them may not be real numbers. We’ll see how to systematically find these eigenvalues and eigenvectors in just a bit.
Visually, this means that lives on the same line as , which is also the line that and live on (for any non-zero scalar ). And, lives on the same line as .
But, if a vector isn’t already on one of the two aforementioned lines – like – then it will change directions when multiplied by , and it is not an eigenvector.
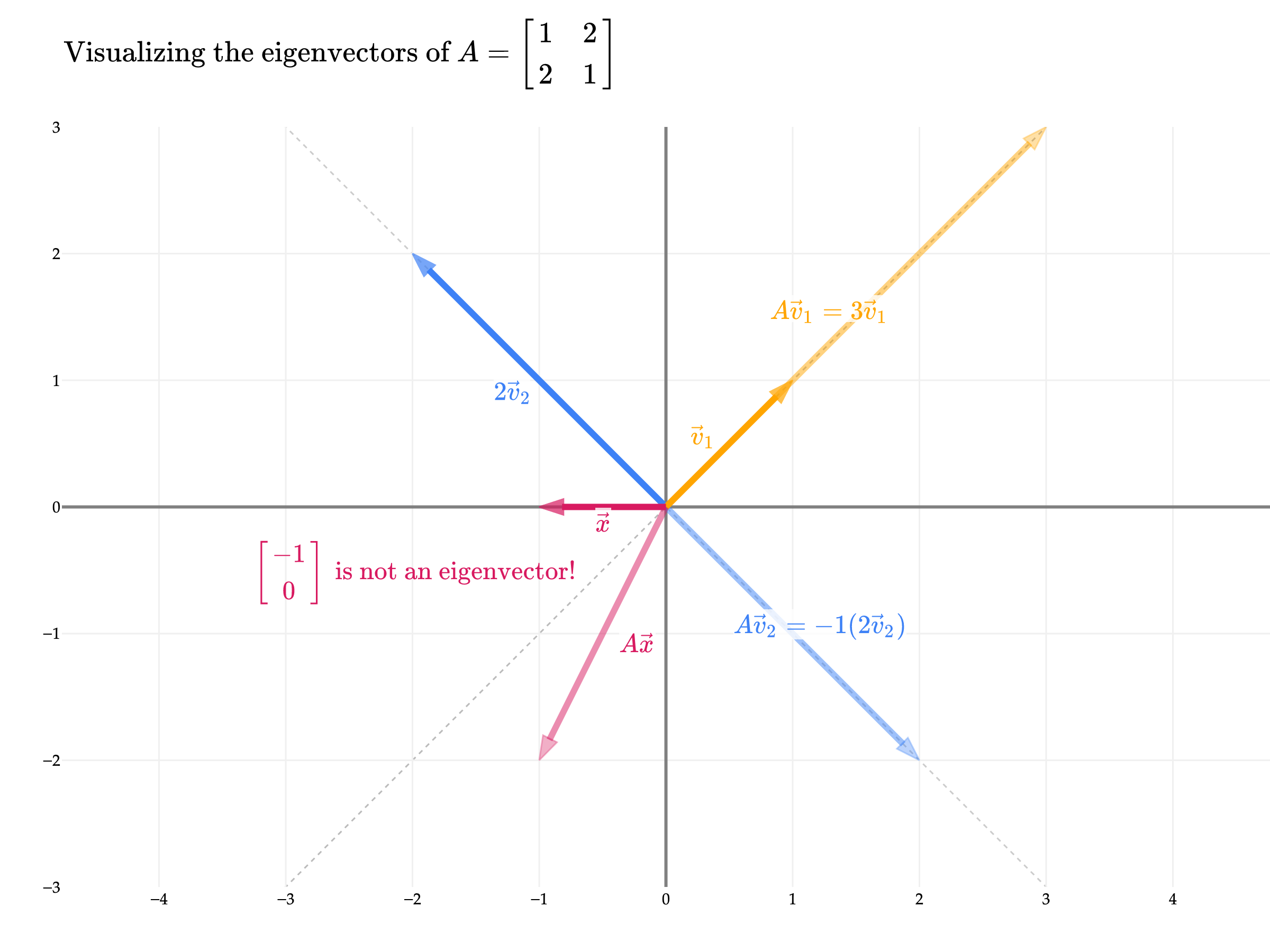
Just to be 100% clear, I’ve used instead of above just to illustrate the fact that eigenvectors are only defined up to a scalar multiple; is just as good as an eigenvector as is, and both correspond to the same eigenvalue, .
You might notice that the two eigenvectors of corresponding to the two different eigenvalues are orthogonal in the example above. This is not true in general for any matrix, but there’s a specific reason it’s true for : it’s symmetric. I’ll elaborate more on this idea in Chapter 9.5, but for now, just remember that symmetric matrices have orthogonal eigenvectors.
Finding Eigenvalues using numpy¶
Just to show you another example, consider
Its eigenvalues and eigenvectors aren’t particularly nice, and since we don’t yet have a way to find them by hand, now is as good as a time as any to use numpy:
B = np.array([[2, 5],
[1, 0]])
np.linalg.eig(B)EigResult(eigenvalues=array([ 3.44948974, -1.44948974]), eigenvectors=array([[ 0.96045535, -0.82311938],
[ 0.27843404, 0.56786837]]))So, has eigenvalues of and . Note that the eigenvectors are the columns of the matrix returned, not the rows!
eigvals, eigvecs = np.linalg.eig(B)
for i in range(eigvecs.shape[1]):
print(f"Eigenvector {i+1}: {eigvecs[:, i]}")
print(f"Eigenvalue {i+1}: {eigvals[i]}")
print()Eigenvector 1: [0.96045535 0.27843404]
Eigenvalue 1: 3.4494897427831783
Eigenvector 2: [-0.82311938 0.56786837]
Eigenvalue 2: -1.449489742783178
eigvecs is a matrix where each column is an eigenvector of . For now, call this matrix . Below, I calculate , which contains the dot products of all pairs of eigenvectors of . The diagonal of this matrix contains the dot products of each eigenvector with itself; since these are 1, this tells us that the returned eigenvectors are unit vectors. This was a design decision by the implementors of np.linalg.eig – remember that we can scale an eigenvector by any non-zero scalar and it is still an eigenvector. The off-diagonal entries of -0.632 tell us that the two eigenvectors are not orthogonal.
eigvecs.T @ eigvecsarray([[ 1. , -0.63245553],
[-0.63245553, 1. ]])Let’s take a look at the directions of the eigenvectors for .
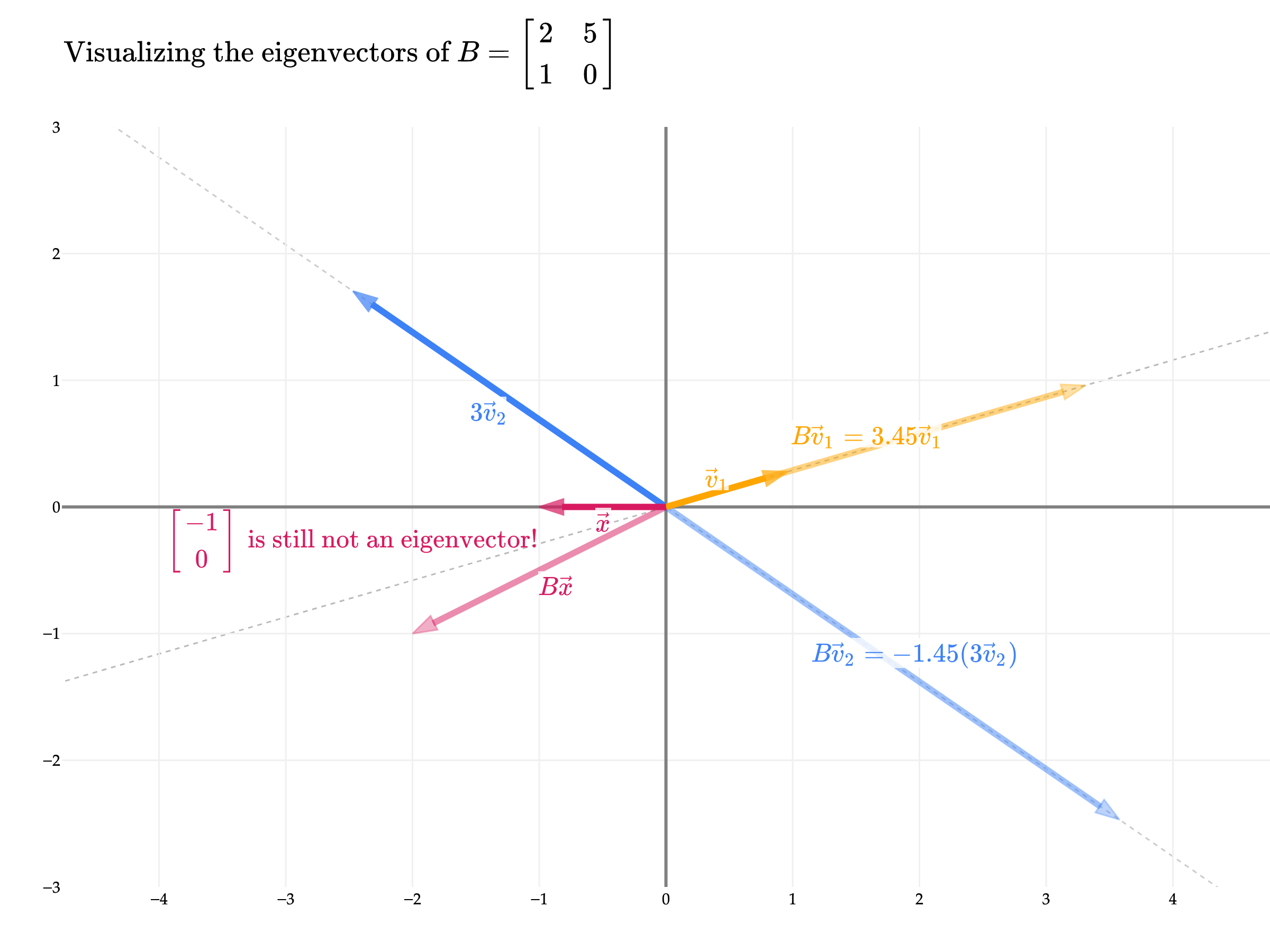
While the eigenvectors of are not orthogonal, they are still linearly independent and span all of . This was also the case in the example above. The fact that the eigenvectors of an matrix are linearly independent and span all of is also not guaranteed to be true, though it’s a desirable property. The class of matrices that have this property are called diagonalizable, which are the focus of Chapter 9.4.
Let’s consider a few more examples, each of which is meant to highlight a different key property of eigenvalues and eigenvectors.
Example: Matrix Powers¶
Let be the matrix from the first example above. What are the eigenvalues and eigenvectors of ? Find them manually. You should notice the property below.
Solution
Similar to the original example, ’s rows both sum to the same number, 9, meaning that
We can do the same thing with :
So the eigenvalues of are 9 and 1, and their respective eigenvectors are and .
But, these are the same two eigenvectors that has, and the corresponding eigenvalues are the squares of ’s eigenvalues, since and . Is this true more generally? Yes!
If is an eigenvalue of with eigenvector , then is an eigenvalue of with the same eigenvector . (Click to see the proof.)
A quick proof: suppose . Then,
This logic can be extended to , then , and so on. (If you are familiar with induction from EECS 203, you can think of this as an inductive proof.)
Note that the converse of this statement is not necessarily true, meaning it’s possible for to have an eigenvector that is not an eigenvector of . For example, if corresponds to a rotation by 90º degrees (or radians), then corresponds to a rotation by 180º degrees (or radians). No vector lies on the same line after rotation by 90º degrees, but all vectors lie on the same line after rotation by 180º degrees. So, in this example, has plenty of eigenvectors that does not have.
Example: Non-Invertible Matrices¶
Let . Notice that . has an eigenvalue of 13 with eigenvector – verify that this is the case. Does it have another eigenvalue? What is the corresponding eigenvector?
Solution
Since , has a non-trivial null space, and any vector in the null space will get sent to 0 times itself when multiplied by . Since , the null space of is spanned by the vector . So,
can’t be an eigenvector, but 0 is a perfectly good eigenvalue.
Our intuition tells us that should have another eigenvalue, since it’s a matrix. It happens to be 13, corresponding to the eigenvector . In Chapter 9.2: The Characteristic Polynomial, we’ll see how to find this eigenvalue-eigenvector pair without guesswork.
0 is an eigenvalue of if and only if is not invertible. (Click to see more details.)
If is invertible, then the only solution to is the trivial solution where is the zero vector itself. But, we defined eigenvectors to be non-zero vectors. So, 0 can’t be an eigenvalue of an invertible matrix. If is not invertible, then has a non-trivial null space, and any non-zero vector in the null space is an eigenvector corresponding to the eigenvalue 0.
Example: The Identity Matrix¶
What are the eigenvalues and eigenvectors of ?
Solution
The identity matrix multiplied by any vector returns that same vector back, meaning that all vectors in are eigenvectors of , all with eigenvalue 1.
This is the first example we’ve seen so far where there exist multiple “lines” or “directions” of eigenvectors for a single eigenvalue. The vectors and are both eigenvectors of with eigenvalue 1 but they don’t lie on the same line. We will study this idea – of having multiple eigenvector directions for a single eigenvalue – more precisely in Chapter 9.4.
A question on your mind might be, how do we find the eigenvalues of a generic matrix, when they aren’t easy to eyeball? Keep reading! The bottom of Chapter 9.2 also has a great summary of the key ideas from this section.