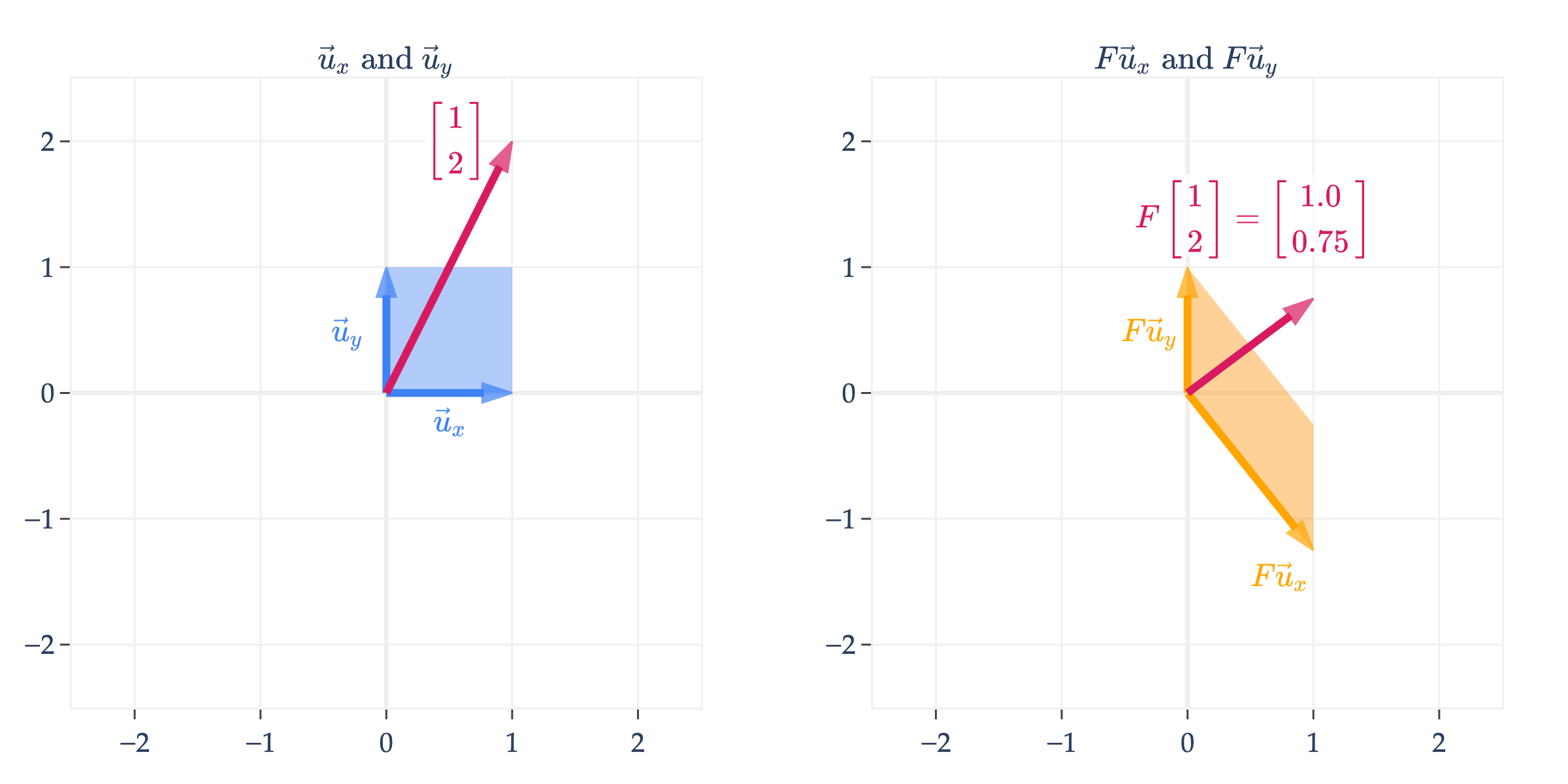Chapter 6.1 was a bit of a detour into the world of linear transformations. In theory, one could read Chapter 6.2 here without that knowledge, but the knowledge of linear transformations (in my mind) will help you better appreciate (and understand) the concept of a matrix inverse.
In “regular” addition and multiplication, you’re already familiar with the idea of an inverse. In addition, the inverse of a number a is another number a′ that satisfies
a+a′=a′+a=0
0 is the “identity” element in addition, since adding it to any number a doesn’t change the value of a. Of course, a′=−a, so −a is the additive inverse of a. Any number a has an additive inverse; for example, the additive inverse of 2 is -2, and the additive inverse of -2 is 2.
In multiplication, the inverse of a number a is another number a′ that satisfies
a⋅a′=a′⋅a=1
1 is the “identity” element in multiplication, since multiplying it by any number a doesn’t change the value of a. Most numbers have a multiplicative inverse of a′=a1, but 0 does not!
0⋅a′=0
is not achieved by any a′.
When a multiplicative inverse exists, we can use it to solve equations like
2x=5
by multiplying both sides by the multiplicative inverse of 2, which is 21.
If A is an n×d matrix, its additive inverse is just −A, which comes from negating each element of A. That part is not all that interesting. What we’re more interested in is the multiplicative inverse of a matrix, which is just referred to as the inverse of the matrix.
Suppose A is some n×d matrix. We’d like to find an inverse, A′, such that when A is multiplied by A′in any order, the result is the identity element for matrix multiplication, I. Recall, the n×n identity matrix is a matrix with 1s on the diagonal (moving from the top left to the bottom right), and 0s everywhere else. The 3×3 identity matrix is
I3=⎣⎡100010001⎦⎤
I3x=x for any x∈R3, and BI3=I3B=B for any B∈R3×3.
If A is an n×d matrix, we’d need a single matrix A′ that satisfies
AA′=A′A=I
In AA′, A′ is the right inverse of A, and in A′A, A′ is the left inverse of A. Right now, we’re interested in finding matrices that have both a left and right inverse, that happen to be the same matrix.
In order to evaluate AA′, we’d need A′ to be of shape d×something, and in order to evaluate A′A, we’d need A′ to be of shape something else×n. The solution to these constraints is to have A′ be a d×n matrix (like AT).
If we try that, then
A′A has shape (d×n)⋅(n×d)=d×d
AA′ has shape (n×d)⋅(d×n)=n×n
but, we want A′A and AA′ to both be the same matrix, not just separate valid matrices. So, we need n=d, which requires A to be n×n, like its inverse.
For example, consider the 2×2 matrix
A=[2345]
It turns out that A does have an inverse! Its inverse, denoted by A−1, is
A−1=[−5/23/22−1]
Because A−1 is the matrix that satisfies both
AA−1=[2345][−5/23/22−1]=[1001]=I
and
A−1A=[−5/23/22−1][2345]=[1001]=I
numpy is good at finding inverses, when they exist.
import numpy as np
A = np.array([[2, 4],
[3, 5]])
np.linalg.inv(A)
array([[-2.5, 2. ],
[ 1.5, -1. ]])
# The top-left and bottom-right elements are 1s,
# and the top-right and bottom-left elements are 0s.
# 4.4408921e-16 is just 0, with some floating point error baked in.
A @ np.linalg.inv(A)
We’re told the matrix is singular, meaning that it’s not invertible.
The point of this section is to understand why some square matrices are invertible and others are not, and what the inverse of an invertible matrix really means.
There may be no solution, a unique solution, or infinitely many solutions for the vector x that satisfies the system, depending on rank(A) and whether b is in colsp(A).
If we assume A is square, i.e. n=d, then Ax=b is a system of n equations in n unknowns. If A is invertible (which, remember, only square matrices can be), then there is a unique solution to the system, and we can find it by multiplying both sides by A−1 on the left.
Ax=b⟹A−1Ax=A−1b⟹x=A−1b
x=A−1b is the unique solution to the system of equations, and we can find it without having to manually solve the system. Thinking back to the example above, we used numpy to find that the inverse of
A=[2345]
is
A−1=[−5/23/22−1]
We can use A−1 to solve the system
2x1+4x23x1+5x2=b1=b2
For any b1,b2∈R, the unique solution for x1 and x2 is
That said, as we’ll discuss at the bottom of this section, actually finding the inverse of a matrix is very computationally intensive, so usually we don’t actually compute A−1. Knowing that it exists, and understanding the properties it satisfies, is the important part.
Remember, the big goal of this section is to find the inverse of a square matrix A.
Since a square matrix A corresponds to a linear transformation, we can think of A−1 as “reversing” or “undoing” the transformation.
For example, if A scales vectors, A−1 should scale by the reciprocal, so that applying A and then A−1 returns the original vector.
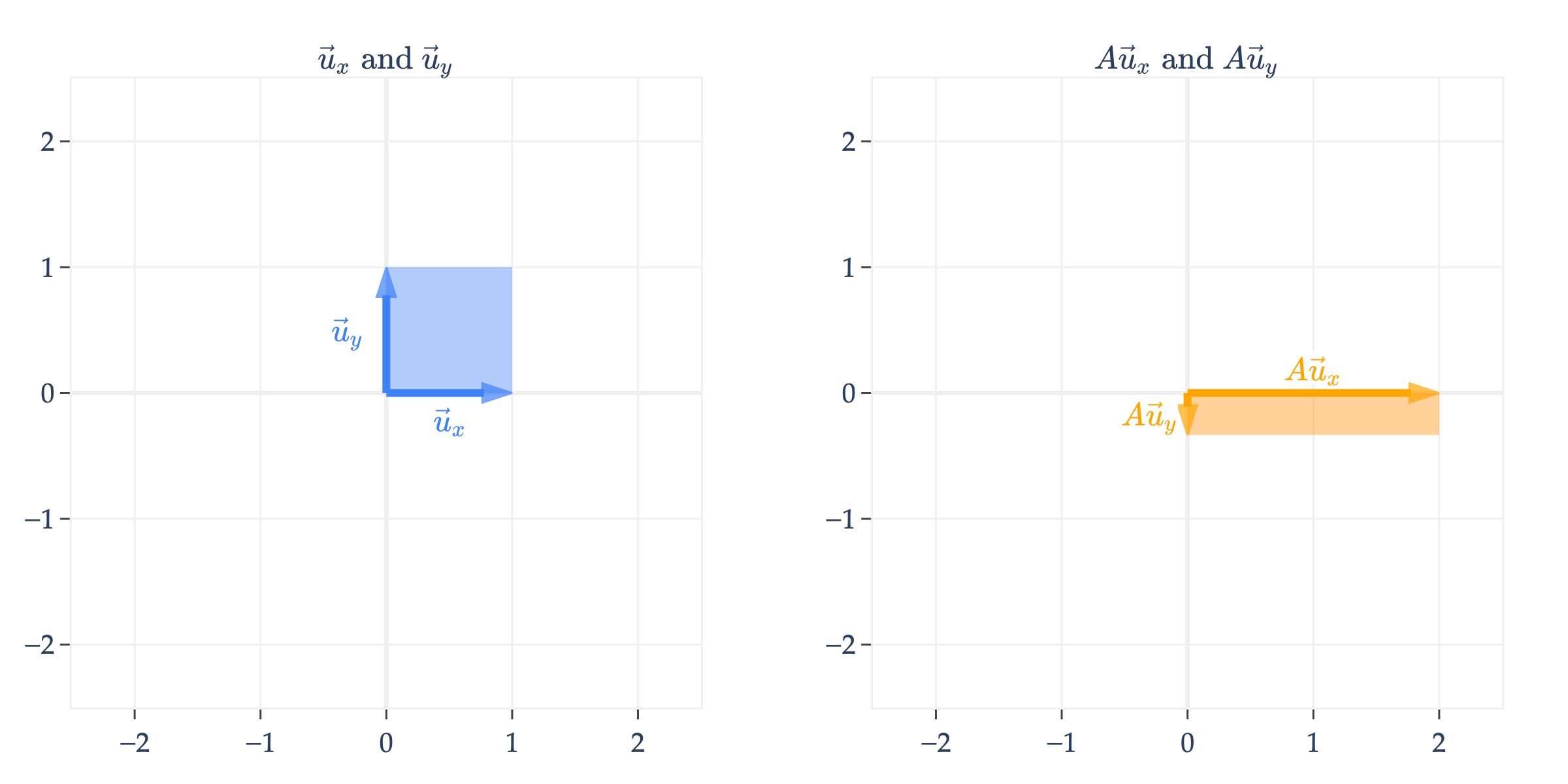
The simplest case involves a diagonal matrix, like
A=[200−1/3]
A = np.array([[2, 0], [0, -1/3]])
plot_unit_square_and_transform(A, name="A")
To undo the effect of A, we can apply the transformation
A−1=[1/200−3]
Many of the transformations we looked at involving 2×2 matrices are reversible, and hence the corresponding matrices are invertible. If the matrix rotates by θ, the inverse is a rotation by −θ. If the matrix shears by “dragging to the right”, the inverse is a shear by “dragging to the left”.
Another way of visualizing whether a transformation is reversible is whether given a vector on the right, there is exactly one corresponding vector on the left. By exactly one, I mean not 0, and not multiple.
Here, we visualize
F=[1−5/401]
Given any vector b of the form b=Fx, there is exactly one vector x that satisfies this equation.
F = np.array([[1, 0], [-5 / 4, 1]])
# The vector to highlight
vec = np.array([1, 2])
# Its transformed position as a vector (i.e. F @ vec)
vec_trans = F @ vec
# Plot the transformation and get the figure object
fig = plot_unit_square_and_transform(
F,
name="F",
vdeltay=-1.3,
vdeltax=0.3,
return_fig=True
)
# Use add_vectors_to_subplot to overlay the original and transformed vectors
add_vectors_to_subplot(
fig,
list_of_vecs=[vec],
start_points=[np.array([0, 0])],
colors=["#d81a60"],
labels=[fr"$\begin{{bmatrix}} {vec[0]} \\ {vec[1]} \end{{bmatrix}}$"],
row=1, col=1,
vdeltay=2.3
)
add_vectors_to_subplot(
fig,
list_of_vecs=[vec_trans],
start_points=[np.array([0, 0])],
colors=["#d81a60"],
labels=[fr"$F\begin{{bmatrix}} {vec[0]} \\ {vec[1]} \end{{bmatrix}} = \begin{{bmatrix}} {vec_trans[0]} \\ {vec_trans[1]} \end{{bmatrix}}$"],
row=1, col=2,
vdeltay=1.3
)
fig.show(renderer='png', scale=3)
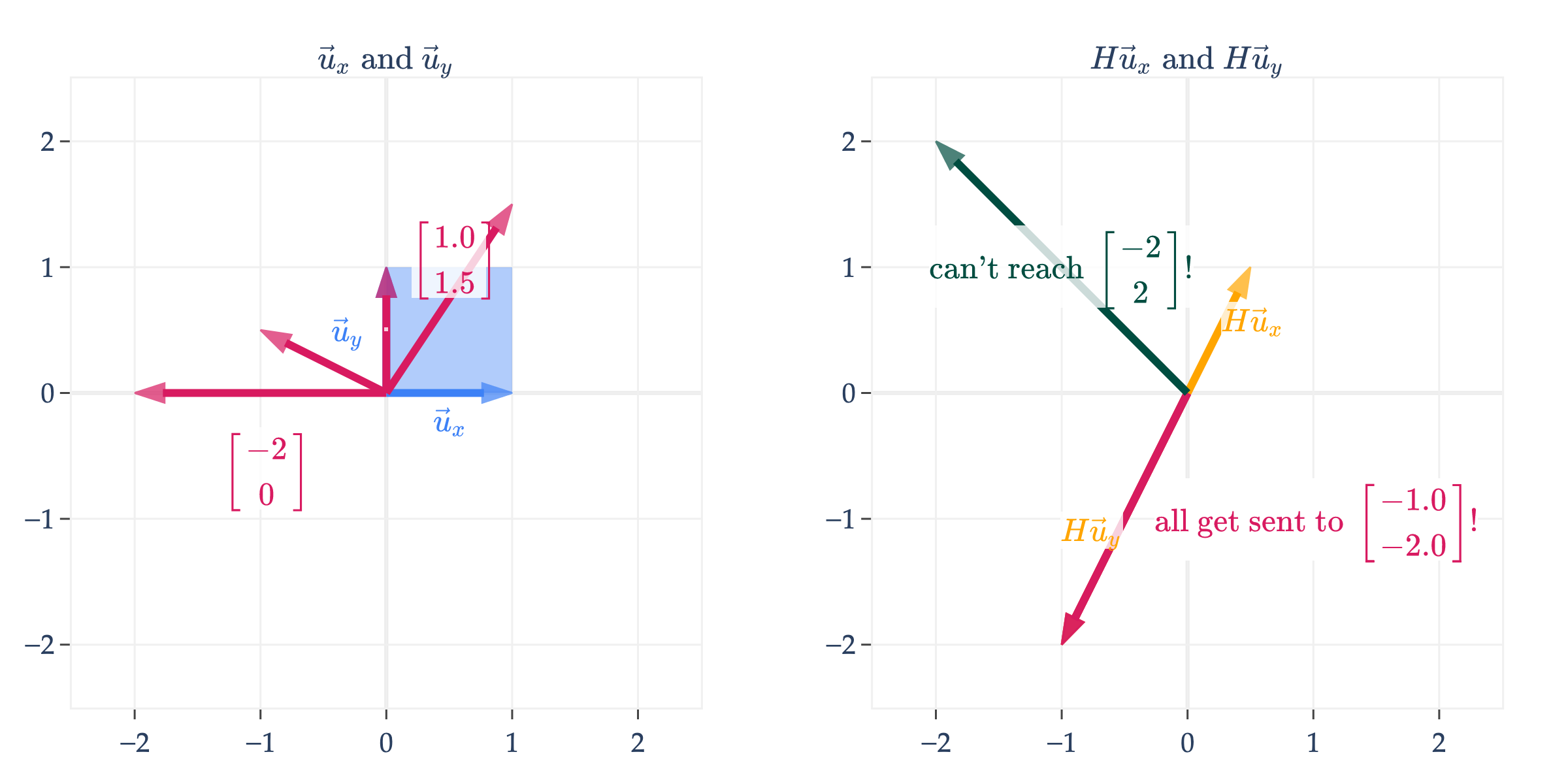
On the other hand, if we look at
H=[1/21−1−2]
the same does not hold true. Given any vector b∈colsp(H) on the right, there are infinitely many vectors x such that Hx=b. The vectors in pink on the left are all sent to the same vector on the right,⎣⎡−1−2⎦⎤.
H = np.array([[1 / 2, -1], [1, -2]])
# Points to highlight
pts = [np.array([0, 1]), np.array([1, 1.5]), np.array([-1, 0.5]), np.array([-2, 0])]
# Their transformed positions
pts_trans = [H @ pt for pt in pts]
# Plot the transformation and get the figure object
fig = plot_unit_square_and_transform(
H,
name="H",
return_fig=True
)
# Use add_vectors_to_subplot to overlay the original points on the left (input) subplot
add_vectors_to_subplot(
fig,
list_of_vecs=pts,
start_points=[np.array([0, 0]) for _ in pts],
colors=["#d81a60"] * len(pts),
labels=[
fr"$\begin{{bmatrix}} {pt[0]} \\ {pt[1]} \end{{bmatrix}}$" if i in [3, 1] else ""
for i, pt in enumerate(pts)
],
row=1, col=1,
vdeltay=0.6
)
# Use add_vectors_to_subplot to overlay the transformed points on the right (output) subplot
# We want to show that all points get sent to the same output
labels_right = [
fr"$\text{{all get sent to }} \begin{{bmatrix}} {pt_t[0]} \\ {pt_t[1]} \end{{bmatrix}}!$"
for pt_t in pts_trans
]
add_vectors_to_subplot(
fig,
list_of_vecs=pts_trans,
start_points=[np.array([0, 0]) for _ in pts_trans],
colors=["rgba(216, 26, 96, 0.7)"] * len(pts_trans),
labels=labels_right,
row=1, col=2,
vdeltay=0,
vdeltax=1.7
)
# Show a point that can't be reached
add_vectors_to_subplot(
fig,
list_of_vecs=[np.array([-2, 2])],
start_points=[np.array([0, 0])],
colors=["#004d40"],
labels=[r"$\text{can't reach } \begin{bmatrix} -2 \\ 2 \end{bmatrix}!$"],
row=1, col=2,
vdeltay=0
)
fig.show(renderer='png', scale=3)
And, there are no vectors on the left that get sent to ⎣⎡−22⎦⎤ on the right. Any vector in R2 that isn’t on the line spanned by [−1−2] is unreachable.
You may recall the following key ideas from discrete math:
A function is invertible if and only if it is both one-to-one (injective) and onto (surjective).
A function is one-to-one if and only if no two inputs get sent to the same output, i.e. f(x1)=f(x2) implies x1=x2.
A function is onto if every element of the codomain is an output of the function, i.e. for every y∈Y, there exists an x∈X such that f(x)=y.
The transformation represented by H is neither one-to-one (because [01] and [11.5] get sent to the same point) nor onto (because [−20] isn’t mapped to by any vector in R2).
In order for a linear transformation to be invertible, it must be both one-to-one and onto, i.e. it must be a bijection. Again, don’t worry if these terms seem foreign: I’ve provided them here to help build connections to other courses if you’ve taken them. If not, the rest of my coverage should still be sufficient.
The big idea I’m trying to get across is that an n×n matrix A is invertible if and only if the corresponding linear transformation can be “undone”. In other words:
If the visual intuition from earlier didn’t make this clear, here’s another concrete example. Consider
A=⎣⎡111222001⎦⎤
rank(A)=2, since A’s first two columns are scalar multiples of one another. Let’s consider two possible b’s, each depicting a different case.
b=⎣⎡333⎦⎤. This b is in colsp(A). The issue with A is that there are infinitely many linear combinations of the columns of A that equal this b.
The properties in the box above are sometimes together called the invertible matrix theorem. This is not an exhaustive list, either, and we’ll see other equivalent properties as time goes on.
As was the case with the determinant, the general formula for the inverse of a matrix is only convenient for 2×2 matrices.
You could solve for this formula by hand, by finding scalars e, f, g, and h such that
A[acbd][egfh]=[1001]
Note that the formula above involves division by ad−bc. If ad−bc=0, then A is not invertible, but ad−bc is just the determinant of A! This should give you a bit more confidence in the equivalence of the statements “A is invertible” and “det(A)=0”.
Let’s test out the 2×2 formula on some examples. If
For matrices larger than 2×2, the calculation of the inverse is not as straightforward; there’s no simple formula. In the 3×3 case, we’d need to find 9 scalars cij such that
This involves solving a system of 3 equations in 3 unknowns, 3 times – one per column of the identity matrix. One such system is
3c11+7c21+c31−2c11+5c214c11+2c21=1=0=0
You can quickly see how this becomes a pain to solve by hand. Instead, we can use one of two strategies:
Using row reduction, also known as Gaussian elimination, which is an efficient method for solving systems of linear equations without needing to write out each equation explicitly. Row reduction can be used to both find the rank and inverse of a matrix, among other things. More traditional linear algebra courses spend a considerable amount of time on this concept, though I’ve intentionally avoided it in this course to instead spend time on conceptual ideas most relevant to machine learning. That said, you’ll get some practice with it in a future homework.
Using a pre-built function in numpy that does the row reduction for us.
At the end of this section, I give you some advice on how to (and not to) compute the inverse of a matrix in code.
Suppose A and B are both invertible n×n matrices. Is AB invertible? If so, what is its inverse?
Suppose A=BC, and A, B, and C are all invertible n×n matrices. What is the inverse of B?
If A, B, and AB are all n×n matrices, and AB is invertible, must A and B both be invertible?
In general, if AB is invertible, must A and B both be invertible?
Solutions
If A and B are both invertible n×n matrices, then AB is indeed invertible, with inverse
(AB)−1=B−1A−1
To confirm, we should check that B−1A−1 is both the left inverse of AB, meaning B−1A−1AB=I, and that it is the right inverse of AB, meaning ABB−1A−1=I.
B−1IA−1AB=B−1B=I
ABB−1A−1=AA−1=I
Since we know that A, B, and C are all invertible,
A=BC⟹AA−1=BCA−1⟹I=BCA−1
This tells us that CA−1 is the inverse of B, since multiplying B by it gets us back to I. (For square matrices, it doesn’t matter whether we multiply on the left or right; the inverse is the same and is unique.)
If A, B, and AB are all n×n matrices, and AB is invertible, then A and B must individually be invertible, too. One way to argue about this is using facts about determinants. Earlier, we learned
det(AB)=det(A)det(B)
If AB is invertible, det(AB)=0, but that must mean det(A)det(B)=0 too, and so neither det(A) nor det(B) can be 0 either, meaning A and B are both invertible.
In general, if AB is invertible, but we don’t know anything about the shapes of A and B, it’s not necessarily true that A and B are individually invertible, because they may not be square! Consider
AB=A[300200]B⎣⎡300020⎦⎤=[9004]
AB is an invertible 2×2 matrix, but neither A nor B are individually invertible, since neither is square.
Suppose X is an n×d matrix. Note that X is not square, and so it is not invertible. However, XTX is a square matrix, and so it is possible that it is invertible.
Explain why XTX is invertible if and only if X’s columns are linearly independent.
The only way for XTX to be invertible is if rank(XTX)=d. But, rank(XTX)=d if and only if rank(X)=d, which happens when all d of X’s columns are linearly independent.
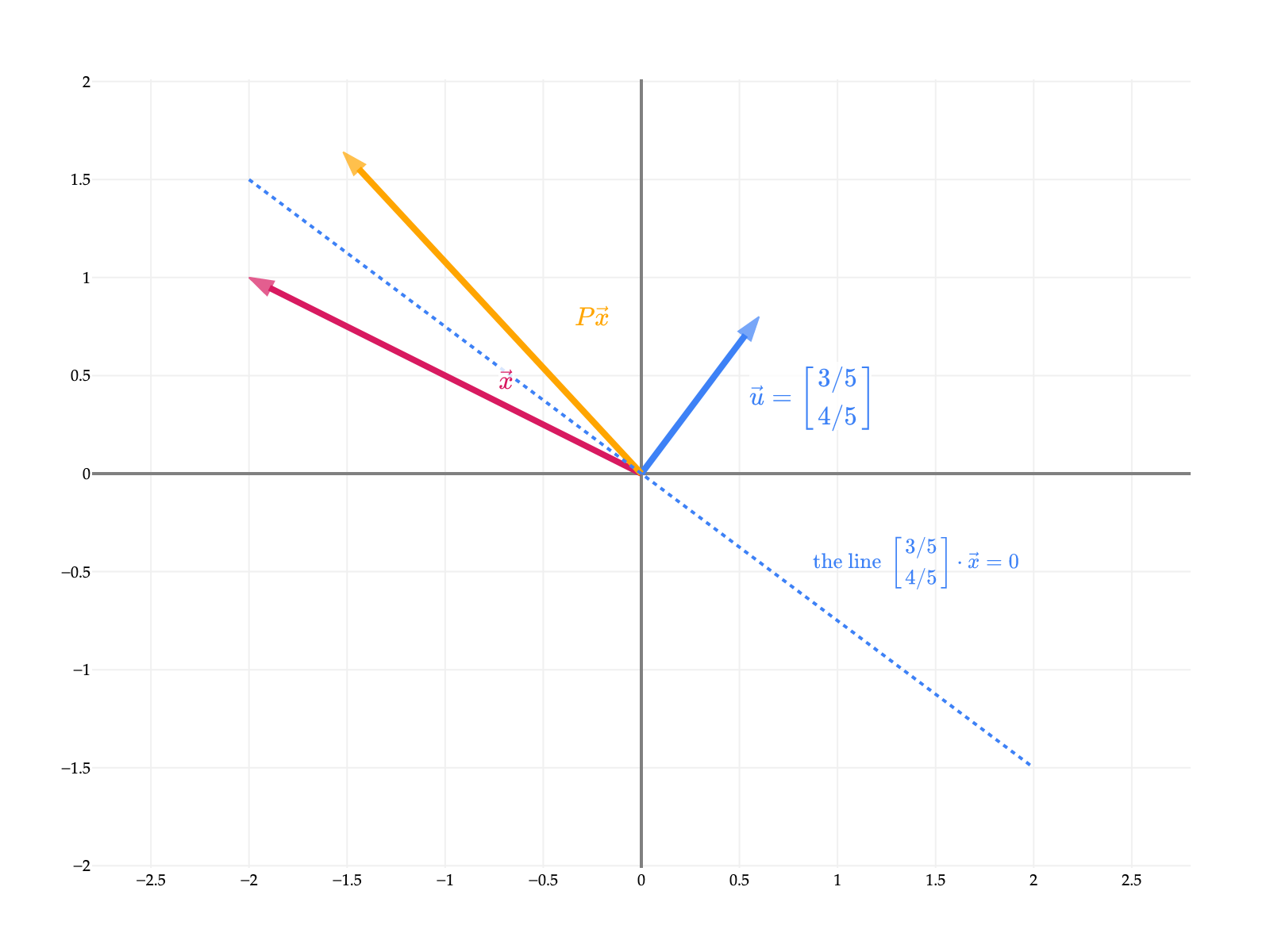
since cos(−θ)=cos(θ) and sin(−θ)=−sin(θ). In English, if Q corresponds to rotating by θ in the counterclockwise direction, QT corresponds to rotating by −θ in the counterclockwise direction, i.e. by θ in the opposite direction.
This means that P’s inverse is just PT, since we multipled P by PT to get I. This also means that PPT=I too, since a square matrix’s inverse is unique and can be multiplied on either side to get I. So, P is indeed orthogonal.
Note that in the final step above, the −4uuT and 4uuT cancelled out. But, the -4 came from −2−2, while the 4 came from (−2)⋅(−2). All of this is to say that if we changed the -2 to some other number in the definition of the Householder matrix, we’d no longer have PTP=I, because -2 is the only non-zero solution to −(c+c)=c⋅c.
As mentioned above, P is invertible: P−1=PT. But, implicitly we also showed that PT=P, meaning P is symmetric:
PT=(I−2uuT)T=I−2uuT=P
So, P is both orthogonal and symmetric! This means that P2=I, or i.e. P=P−1.
Intuitively, P involves reflecting across a line, so PTP=P2 involves reflecting twice, which is the same as doing nothing, and the inverse of P is the same as P itself.
Prove that if A2 is invertible, then A is invertible. Do so in three different ways:
By constructing A’s inverse directly.
By arguing about the null spaces of A2 and A.
By using the determinant.
Solution
Solution 1: By direct construction
One way to prove that A is invertible is to find its inverse. Since A2 is invertible, there must exist some matrix B such that
A2B=I,BA2=I
Note that the inclusion of both orders is important, since in general, order matters for matrix multiplication. Writing A2=AA in the first equation gives us
A(AB)=I
This tells us that AB is the inverse of A, so A is invertible.
If we used the second equation instead, we’d have
(BA)A=I
So, we’d call AB the right inverse of A (since it’s the inverse that multiplies on the right) and BA the left inverse. A general fact is that if A has both a left and right inverse, they must be the same, meaning that AB must be equal to BA here (remember this is not true in general for arbitrary matrices A and B). A quick proof of this is
BA=BAI=BA(AAB)=BAAAB=(BAA)AB=IAB=AB
So, in short, A−1=AB=BA, and since we’ve found A’s inverse, A must be invertible.
Solution 2: The null space perspective
Let’s argue by contradiction. Suppose A2 is invertible, but A is not. This would imply that A2 null space is just the zero vector, 0, while A’s null space is not just 0. Suppose x is some vector \textbf{other than 0} in nullsp(A), meaning that
Ax=0
But, left-multiplying both sides by A gives us
A(Ax)=A0⟹A2x=0
This tells us that x is in the null space of A2, since A2x=0. But, this contradicts our assumption that A2 is invertible, because the only vector in the null space of an invertible matrix is the zero vector. So, our original assumption that A is not invertible must be false, and A must be invertible.
Solution 3: The determinant perspective
A fact from Chapter 6.1 is that if A and B are two n×n matrices, then
det(A)det(B)=det(AB)
So,
det(A2)=det(A⋅A)=det(A)⋅det(A)=det(A)2
But, we also know that invertible matrices have non-zero determinants, so we’re given that det(A2)=0. But, since det(A2)=det(A)2, this implies that det(A)2=0, and so det(A)=0 too, and so A is invertible.
If A⎣⎡31−1⎦⎤=⎣⎡943⎦⎤ and A⎣⎡402⎦⎤=⎣⎡000⎦⎤, is A invertible?
Solution
No, A is not invertible. This is because its columns are linearly dependent, or equivalently, it has a non-trivial null space. This comes from the fact that
A⎣⎡402⎦⎤=0
which means that ⎣⎡402⎦⎤ is in the null space of A.
is a system of n equations in n unknowns. One of the big (conceptual) usages of the inverse is to solve such a system, as I mentioned at the start of this section. If A is invertible, then we can solve for x by multiplying both sides on the left by A−1:
Ax=b⟹A−1Ax=A−1b⟹x=A−1b
A−1 has encoded within it the solution to Ax=b, no matter what b is. This makes A−1 very powerful. But, that power doesn’t come for free: in practice, finding A−1 is less efficient and more prone to floating point errors than solving the one system of n equations in n unknowns directly for the specific b we care about.
Solving Ax=b involves solving just one system of n equations in n unknowns.
Finding A−1 involves solving a system of n equations in n unknowns, n times! Each system has the same coefficient matrix A but a different right-hand side b, corresponding to the columns of the identity matrix (which are the standard basis vectors in Rn).
The more floating point operations we need to do, the more error is introduced into the final results.
Let’s run an experiment. Suppose we’d like to find the solution to the system
x1+x2x1+1.000000001x2=7=7.000000004
This corresponds to Ax=b, with
A=[1111.000000001],b=[77.000000004]
Here, we can eyeball the solution as being x=[34]. How close to this “true” x do each of the following techniques get?
Option 1: Using np.linalg.inv
As we saw at the start of the section, np.linalg.inv(A) finds the inverse of A, assuming it exists. The following cell finds the solution to Ax=b by first computing A−1, and then A−1b=x.
# Prevents unnecessary rounding.
np.set_printoptions(precision=16, suppress=True)
A = np.array([[1, 1],
[1, 1.000000001]])
b = np.array([[7],
[7.000000004]])
x_inv = np.linalg.inv(A) @ b
x_inv
The following cell solves the same problem as the previous cell, but rather than asking for the inverse of A, it asks for the solution to Ax=b, which doesn’t inherently require inverting A.
x_solve = np.linalg.solve(A, b)
x_solve
array([[3.],
[4.]])
This small example already illustrates the big idea: inverting can introduce more numerical error than is necessary. If we cast the problem more abstractly, consider the matrix
A=[1111+ϵ]
where ϵ is a small constant, e.g. ϵ=0.000000001 in the example above. The inverse of A is
A−1=1(1+ϵ)−1⋅11[1+ϵ−1−11]=ϵ1[1+ϵ−1−11]
The closer ϵ is to 0, the larger ϵ1 becomes, making any floating point errors all the more costly.