We’re almost ready to return to our original motivation for studying linear algebra, which was to perform linear regression using multiple input variables. This section outlines the final piece of the puzzle.
In Chapter 3.4, we introduced the approximation problem, which asked:
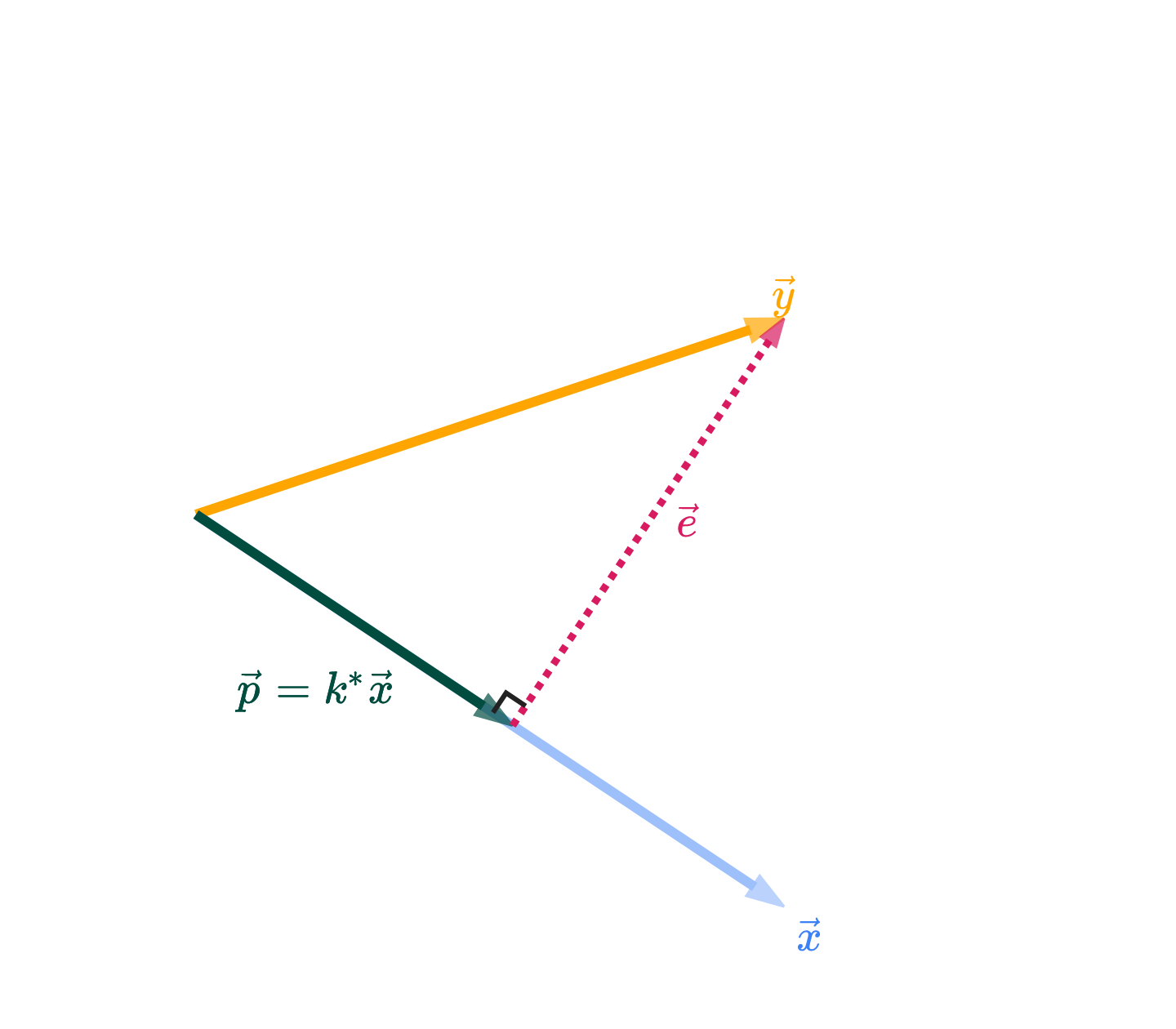
Among all vectors of the form kx, which one is closest to y?
We now know the answer is the vector p, where
p=(x⋅xy⋅x)x
p is called the orthogonal projection of y onto x.
Note that I’ve used y and x here rather than u and v, just to make the notation more consistent with the notation we’ll use as we move back into the world of machine learning.
In our original look at the approximation problem, we were approximating y using a scalar multiple of just a single vector, x. The set of all scalar multiples of x, denoted by span({x}), is a line in Rn.
Key idea: instead of projecting onto the subspace spanned by just a single vector, how might we project onto the subspace spanned by multiple vectors?
Equipped with our understanding of linear independence, spans, subspaces, and column spaces, we’re ready to tackle a more advanced version of the approximation problem.
All three statements at the bottom of the box above are asking the exact same question; I’ve presented all three forms so that you see more clearly how the ideas of spans, column spaces, and matrix-vector multiplication fit together. I will tend to refer to the latter two versions of the problem the most. In what follows, suppose X is an n×d matrix whose columns x(1), x(2), ..., x(d) are the building blocks we want to approximate y with.
First, let’s get the trivial case out of the way. Ify∈colsp(X), then the vector in colsp(X) that is closest to y is just y itself. If that’s the case, there exists some w such that y=Xw exactly. This w is unique only if X's columns are linearly independent; otherwise, there will be infinitely many good w’s.
But, that’s not the case I’m really interested in. I care more about when y is not in colsp(X). (Remember, this is the case we’re interested in when we’re doing linear regression: usually, it’s not possible to make our predictions 100% correct, and we’ll have to settle for some error.)
Then what?
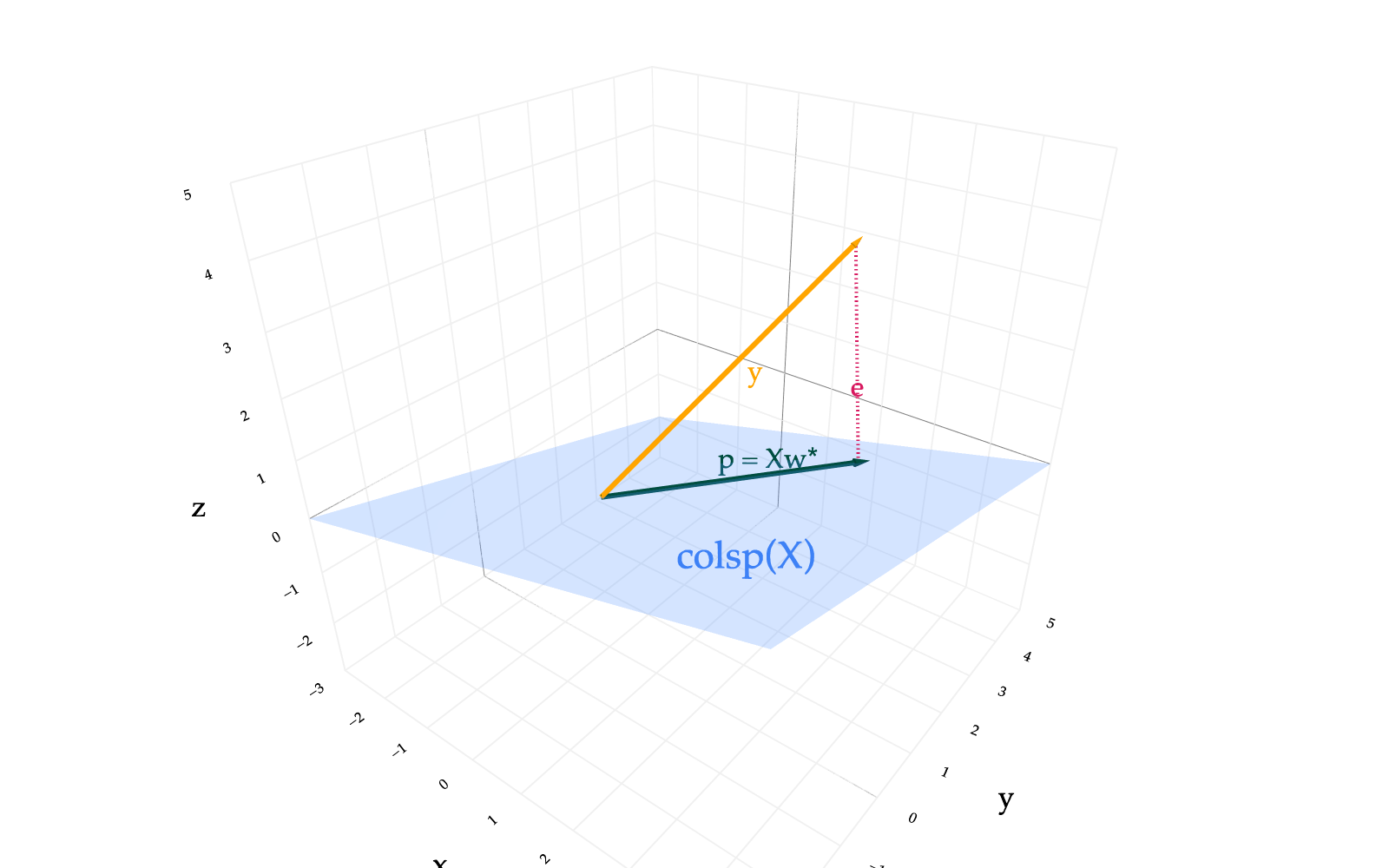
In general, colsp(X) is an r-dimensional subspace of Rn, where r=rank(X). In the diagram below, I’ve used a plane to represent colsp(X); just remember that X may have more than 3 rows or columns.
from utils import plot_vectors
import numpy as np
import plotly.graph_objects as go
y = np.array([1, 3, 2]) * 1.5
v1 = (1, 0, 0.25)
v2 = np.array([2, 2, 0]) * 0.5
def create_base_fig(show_spanners=True):
# Define the vectors
v3 = (-3.5 * v1[0] + 4 * v2[0], -3.5 * v1[1] + 4 * v2[1], -3.5 * v1[2] + 4 * v2[2]) # v3 is v1 + v2, which is on the plane spanned by v1 and v2
# Plot the vectors using plot_vectors function
vectors = [
(tuple(y), "orange", "y"),
(v1, "#3d81f6", "x⁽¹⁾"),
(tuple(-v2), "#3d81f6", "x⁽²⁾"),
(v3, "#3d81f6", "x⁽³⁾")
]
if not show_spanners:
vectors = [vectors[0]]
fig = plot_vectors(vectors, show_axis_labels=True, vdeltaz=5, vdeltax=1)
# Make the plane look more rectangular by using a smaller, symmetric range for s and t
plane_extent = 20 # controls the "size" of the rectangle
num_points = 3 # fewer points for a cleaner rectangle
s_range = np.linspace(-plane_extent, plane_extent, num_points)
t_range = np.linspace(-plane_extent, plane_extent, num_points)
s_grid, t_grid = np.meshgrid(s_range, t_range)
plane_x = s_grid * v1[0] + t_grid * v2[0]
plane_y = s_grid * v1[1] + t_grid * v2[1]
plane_z = s_grid * v1[2] + t_grid * v2[2]
fig.add_trace(go.Surface(
x=plane_x,
y=plane_y,
z=plane_z,
opacity=0.8,
colorscale=[[0, 'rgba(61,129,246,0.3)'], [1, 'rgba(61,129,246,0.3)']],
showscale=False,
))
# Annotate the plane with "colsp(X)"
# Move the annotation "down" the plane by choosing negative s and t values
label_s = 0.3
label_t = 0.9
label_x = label_s * v1[0] + label_t * v2[0]
label_y_coord = label_s * v1[1] + label_t * v2[1] - 2
label_z = label_s * v1[2] + label_t * v2[2]
fig.add_trace(go.Scatter3d(
x=[4],
y=[-2],
z=[2], # small offset above the plane for visibility
mode="text",
text=[r"colsp(X)"],
textposition="middle center",
textfont=dict(size=22, color="#3d81f6"),
showlegend=False
))
# Set equal ranges for all axes to make grid boxes square
axis_range = [-3, 5] # Same range for all axes
fig.update_layout(
scene_camera=dict(
eye=dict(x=1, y=-1.3, z=1)
),
scene=dict(
xaxis=dict(
range=axis_range,
dtick=1,
),
yaxis=dict(
range=axis_range,
dtick=1,
),
zaxis=dict(
range=axis_range,
dtick=1,
),
aspectmode="cube",
aspectratio=dict(x=1, y=1, z=1), # Explicitly set 1:1:1 ratio
),
)
return fig
create_base_fig().show()
Loading...
Remember that colsp(X) is the set of linear combinations of X's columns, so it’s the set of all vectors that can be written as Xw, where w∈Rd.
Let’s consider two possible vectors of the form Xw, and look at their corresponding error vectors, e=y−Xw. I won’t draw the columns of X, since those would clutter up the picture.
def plot_vectors_with_errors(vectors_list, base_fig=None, notation="0"):
"""
Takes a list of vectors and draws each one in #004d40 with a dotted error line in #d81a60.
Parameters:
-----------
vectors_list : list of array-like
List of vectors to plot. Each vector should be a 3D point/vector.
base_fig : plotly.graph_objects.Figure, optional
Base figure to build upon. If None, creates a new base figure using create_base_fig().
Returns:
--------
fig : plotly.graph_objects.Figure
The figure with vectors and error lines added.
"""
fig = create_base_fig(show_spanners=False)
# Get y vector from create_base_fig (defined the same way)
y = np.array([1, 3, 2]) * 1.5
for i, vec in enumerate(vectors_list):
vec = np.array(vec)
# Draw the vector in #004d40
fig.add_trace(go.Scatter3d(
x=[0, vec[0]],
y=[0, vec[1]],
z=[0, vec[2]],
mode='lines',
line=dict(color='#004d40', width=6),
showlegend=False
))
# Add arrowhead for the vector
fig.add_trace(go.Cone(
x=[vec[0]],
y=[vec[1]],
z=[vec[2]],
u=[vec[0]],
v=[vec[1]],
w=[vec[2]],
colorscale=[[0, '#004d40'], [1, '#004d40']],
showscale=False,
sizemode="absolute",
sizeref=0.3,
showlegend=False
))
# Draw the error line (dotted) from vec to y in #d81a60
fig.add_trace(go.Scatter3d(
x=[vec[0], y[0]],
y=[vec[1], y[1]],
z=[vec[2], y[2]],
mode='lines',
line=dict(color='#d81a60', width=4, dash='dash'),
showlegend=False
))
# Annotate the vectors and error lines
if i == 0:
# Annotate the vector as Xw₀
fig.add_trace(go.Scatter3d(
x=[1], y=[3], z=[-0.5],
mode='text',
text=["p\u2080 = Xw\u2080"] if notation == "0" else ["p = Xw*"], # \u2080 is Unicode subscript zero
textposition="middle center",
textfont=dict(color='#004d40', size=16),
showlegend=False
))
# Annotate the error as e₀
mid_error = (vec + y) / 2
fig.add_trace(go.Scatter3d(
x=[mid_error[0]],
y=[mid_error[1]],
z=[mid_error[2]],
mode='text',
text=["e\u2080"] if notation == "0" else ["e"],
textposition="bottom center",
textfont=dict(color='#d81a60', size=16),
showlegend=False
))
else:
# Annotate the vector as Xw'
fig.add_trace(go.Scatter3d(
x=[2], y=[-1], z=[1],
mode='text',
text=["p' = Xw'"],
textposition="middle center",
textfont=dict(color='#004d40', size=16),
showlegend=False
))
# Annotate the error as e'
mid_error = (vec + y) / 2
fig.add_trace(go.Scatter3d(
x=[mid_error[0]],
y=[mid_error[1]],
z=[mid_error[2]],
mode='text',
text=["e'"],
textposition="bottom center",
textfont=dict(color='#d81a60', size=16),
showlegend=False
))
return fig
fig = create_base_fig()
# y = np.array([1, 3, 2]) * 1.5
# v1 = (1, 0, 0.25)
# v2 = np.array([2, 2, 0]) * 0.5
X = np.vstack([v1, v2]).T
w = np.linalg.inv(X.T @ X) @ X.T @ y
# w = [-1.333, 3.6667]
p = X @ w
other_p = X @ np.array([2, 1])
test_vectors = [p, other_p]
# Plot vectors with errors
fig = plot_vectors_with_errors(test_vectors, fig)
fig.show()
Loading...
Our problem boils down to finding the w that minimizes the norm of the error vector. Since it’s a bit easier to work with squared norms (remember that ∥x∥2=x⋅x), we’ll minimize the squared norm of the error vector instead; this is an equivalent problem, since the norm is non-negative to begin with.
which w minimizes this?∥e∥2=∥y−Xw∥2
Think of ∥y−Xw∥2 as a function of w only; X and y should be thought of as fixed. This is a least squares problem: we’re looking for the w that minimizes the sum of squared errors between y and Xw.
There are two ways we’ll minimize this function of w:
Using a geometric argument, as we did in the single vector case.
Using calculus. This is more involved than before, since the input variable is a vector, not a scalar, but it can be done, as we’ll see in Chapter 8.
Let’s focus on the geometric argument. What does our intuition tell us? Extending the single vector case, we expect the vector in colsp(X) that is closest to y to be the orthogonal projection of y onto colsp(X): that is, its error should be orthogonal to colsp(X).
We could see this intuitively in the visual above. wo was chosen to make eo orthogonal to colsp(X), meaning that eo is orthogonal to every vector in colsp(X). (The subscript “o” stands for “orthogonal”.) w′ was some other arbitrary vector, leading e′ to not be orthogonal to colsp(X). Clearly eo is shorter than e′.
To prove that the optimal choice of w comes from making the error vector orthogonal to colsp(X), you could use the same argument as in the single vector case: if you consider two vectors, wo with an orthogonal error vector eo, and w′ with an error vector e′ that is not orthogonal to colsp(X), then we can draw a right triangle with e′ as the hypotenuse and eo as one of the legs, making
∥e′∥2>∥eo∥2
This is such an important idea that I want to redraw the picture above with just the orthogonal projection. Note that I’ve replaced wo with w∗ to indicate that this is the optimal choice of w.
fig = create_base_fig()
# y = np.array([1, 3, 2]) * 1.5
# v1 = (1, 0, 0.25)
# v2 = np.array([2, 2, 0]) * 0.5
X = np.vstack([v1, v2]).T
w = np.linalg.inv(X.T @ X) @ X.T @ y
# w = [-1.333, 3.6667]
p = X @ w
test_vectors = [p]
# Plot vectors with errors and draw a right angle between p and e
fig = plot_vectors_with_errors(test_vectors, fig, notation='*')
fig.show(renderer='png', scale=2)
A Proof that the Orthogonal Error Vector is the Shortest¶
In office hours, a student asked for more justification that the shortest possible error vector is one that’s orthogonal to the column space of X, especially because it’s hard to visualize what orthogonality looks like in higher dimensions. Remember, all it means for two vectors to be orthogonal is that their dot product is 0.
Given that, let’s assume only that
wo is chosen so that eo=y−Xwo is orthogonal to colsp(X), and
w′ is any other choice of w, with a corresponding error vector e′=y−Xw′.
Just with these facts alone, we can show that eo is the shortest possible error vector. To do so, let’s start by considering the (squared) magnitude of e′:
∥e′∥2=∥y−Xw′∥2=seems arbitrary, but it’s a legal operation that brings woback in∥y−Xw′+Xwo−Xwo∥2=∥‘‘a"y−Xwo+‘‘b"X(wo−w′)∥2=∥a+b∥2=∥a∥2+∥b∥2+2a⋅b∥y−Xwo∥2+∥X(wo−w′)∥2+2(y−Xwo)⋅X(wo−w′)=∥eo∥2+∥X(wo−w′)∥2+0, because eo is orthogonal to the columns of X2eo⋅X(wo−w′)=∥eo∥2+∥X(wo−w′)∥2≥∥eo∥2
So, no matter what choice of w′ we make, the magnitude of e′ can’t be smaller than the magnitude of eo. This means that the error vector that is orthogonal to the column space of X is the shortest possible error vector.
This is really just the same proof as in Chapter 3.4, where we argued that eo, X(wo−w′), and e′ form a right triangle, where e′ is the hypotenuse.
We’ve come to the conclusion that in order to find the w that minimizes
∥e∥2=∥y−Xw∥2
we need to find the w that makes the error vector e=y−Xw orthogonal to colsp(X). colsp(X) is the set of all linear combinations of X's columns. So, if we can find an e that is orthogonal to every column of X, then it must be orthogonal to any of their linear combinations, too.
To see why, take any vector in colsp(X). It has the form a1x(1)+a2x(2)+…+adx(d). Then
So checking orthogonality against the columns of X is enough to guarantee orthogonality against everything in colsp(X).
So, we’re looking for a e=y−Xw that satisfies
x(1)⋅(y−Xw)x(2)⋅(y−Xw)x(d)⋅(y−Xw)=0=0⋮=0
As you might have guessed, there’s an easier way to write these d equations simultaneously. Above, we’re taking the dot product of y−Xw with each of the columns of X. We’ve learned that Av contains the dot products of v with the rows of A. So how do we get the dot products of y−Xw with the columns of X? Transpose it!
So, if we want y−Xw to be orthogonal to each of the columns of X, then we need XT(y−Xw)=0 (note that this is the vector 0∈Rd, not the scalar 0.) Another way of saying this is that we need the error vector to be in the left null space of X, i.e. e∈null(XT).
XTeXT(y−Xw)XTy−XTXwXTXw=0=0=0=XTy
The final equation above is called the normal equation. “Normal” means “orthogonal”. Sometimes it’s called the normal equations to reference the fact that it’s a system of d equations and d unknowns, where the unknowns are components of w (w1,w2,…,wd.) I myself will use the terms “normal equation” and “normal equations” interchangeably.
Note that XTXw=XTy looks a lot like Xw=y, with added factors of XT on the left. Remember that if y is in colsp(X), then Xw=y has a solution, but that’s usualy not the case, hence why we’re attempting to approximate y with a linear combination of X’s columns.
Is there a unique vector w that satisfies the normal equation? That depends on whether XTX is invertible. XTX is a d×d matrix with the same rank as the n×d matrix X, as we proved in Chapter 5.4.
rank(XTX)=rank(X)
So, XTX is invertible if and only if rank(X)=d, meaning all of X’s columns are linearly independent. In that case, the best choice of w is the unique vector
w∗=(XTX)−1XTy
w∗ has a star on it, denoting that it is the best choice of w. I don’t ask you to memorize much (you get to bring a notes sheet into your exams, after all), but this equation is perhaps the most important of the semester! It might even look familiar: back in the single vector case in Chapter 3.4, the optimal coefficient on x was x⋅xx⋅y=xTxxTy, which looks similar to the one above. The difference is that here, XTX is a matrix, not a scalar. (But, if X is just a matrix with a single column, then XTX is just the dot product of X with itself, which is a scalar, and the boxed formula above reduces to the formula from Chapter 3.4.)
What if XTXisn’t invertible? Then, there are infinitely many w∗'s that satisfy the normal equation,
XTXw=XTy
It’s not immediately obvious what it means for there to be infinitely many solutions to the normal equation; I’ll explore this idea in Chapter 6.4.
First, let’s start with a straightforward example. Let
X=⎣⎡1210011−1⎦⎤,y=⎣⎡1045⎦⎤
The vector in colsp(X) that is closest to y is the vector Xw∗, where w∗ is the solution to the normal equations,
XTXw∗=XTy
The first step is to compute XTX, which is a 2×2 matrix of dot products of the columns of X.
XTX=[6333]
XTX is invertible, so we can solve for w∗ uniquely. Remember that in practice, we’d ask Python to solve np.linalg.solve(X.T @ X, X.T @ y), but here XTX is small enough that we can invert it by hand.
The magic is in the interpretation of the numbers in w∗, 2 and −37. These are the coefficients of the columns of X in the linear combination that is closest to y. Meaning,
The first example above is the most concrete. The examples that follow will build our understanding of how orthogonal projections really work. Then, Chapter 6.4 will explore what happens when there are infinitely many solutions to the normal equation, and introduce the idea of the projection matrix.
Find the point on the plane 6x−3y+2z=0 that is closest to the point (1,1,1).
Solution
At first, this doesn’t seem like a projection problem, but it is. The plane
6x−3y+2z=0
is a 2-dimensional subspace of R3, meaning it can be described as the span of two non-collinear vectors. So, all we need to do is find some matrix X with those two vectors as columns, and then use the formula we derived above to project y=⎣⎡111⎦⎤ onto colsp(X). The fact that we said “point” instead of “vector” doesn’t change the problem: in settings like these, points and vectors are equivalent.
Two vectors that lie in the plane (but point in different directions) are ⎣⎡120⎦⎤ and ⎣⎡10−3⎦⎤. There’s nothing special about these two vectors, other than that they have relatively small integer components. Let’s use them as columns of X:
X=⎣⎡12010−3⎦⎤
Now, to formulate the normal equations, XTXw∗=XTy, we need to compute XTX and XTy.
XTX=[11200−3]⎣⎡12010−3⎦⎤=[51110]
XTy=[11200−3]⎣⎡111⎦⎤=[3−2]
So, the normal equations are
[51110]w∗[w0∗w1∗]=[3−2]
We could use w∗=(XTX)−1XTy, but often it’s easier to solve the system directly.
5w0∗+w1∗w0∗+10w1∗=3=−2
Solving this system gives us w0∗=4932 and w1∗=−4913. (Sorry, I know the numbers aren’t pretty in this example. But that’s what happens in the real world.)
Now that we’ve solved for w∗=[4932−4913], the projection of y onto colsp(X) - which is the point on the plane that’s closest to y - is
Find the orthogonal projection of y=⎣⎡132−1⎦⎤ onto colsp(X), where X=⎣⎡1210011−1⎦⎤.
Solution
First, notice that y is just the sum of the two columns of colsp(X). So intuitively, because y is already in the column space of X, the projection is just y itself.
The condition ZTeZ=[00] gives us some relationships involving e1,e2,e3,e4, but not enough to guarantee that the components sum to 0.
Key takeaway: Remember that XTeX=[00] implies that eX is orthogonal to any linear combination of the columns of X. So, if you can create a column of all 1’s using a linear combination of X’s columns, then the components of eX will sum to 0, no matter which vector y you choose to project onto colsp(X).
This may seem like a small algebraic fact, but it will be very important when we return to regression in Chapter 7.1. There, our matrix X will usually contain a column of all 1s, because our regression model will usually include an intercept term. When that happens, the error vector being orthogonal to the columns of X guarantees that the components of the error vector sum to 0. In other words, our fit regression model will satisfy a concrete constraint: the positive and negative errors must balance out overall.
Usually, our data doesn’t come to us with orthogonal columns. But, using the Gram-Schmidt process introduced to you in Homework 8 and Chapter 6.5 (coming soon), you can convert a set of linearly independent vectors into an orthogonal set with the same span, allowing you to leverage that QTQ=I and simplify the projection process.
Key takeaway: Orthonormal vectors are very easy to work with!
In general, X is not a square matrix, so it can’t be invertible!
If X is square and invertible, then the steps above are valid. But, if X is a square and invertible n×n matrix, then colsp(X)=Rn, meaning that any y in Rn can be written as a linear combination of X’s columns, meaning that y is already in colsp(X), and there is no projection error (or need to do a projection in the first place).
Don’t stop here: keep reading Chapter 6.4 to see what happens when there are infinitely many solutions to the normal equation. It also contains a great summary of the ideas in Chapter 6.3, too.