There’s an important operation on matrices that we haven’t discussed yet. Let me introduce it, and then walk through a few types of matrices that are important enough to be given names.
To illustrate, let’s start with our familiar matrix A:
A=⎣⎡320211−1−24900⎦⎤
The transpose of A is:
AT=⎣⎡3142190−102−20⎦⎤
Note that A∈R4×3 and AT∈R3×4.
Why would we ever need to do this? To illustrate, suppose u=⎣⎡u1u2u3u4⎦⎤, and that we’d like to compute the product ATu. (Note that u must be in R4 in order for ATu to be defined, unlike x∈R3 in the product Ax). Then:
This is a linear combination of the rows of A, where the weights are the components of u. Remember, the standard product Ax is a linear combination of the columns of A, so the transpose helps us if we want to compute a linear combination of the rows of A. (Equivalently, it helps us if we want to compute the dot product of the columns of A with u – see the linear combination interpretation section of Chapter 5.1.)
The transpose also gives us another way of expressing the dot product of two vectors. If u and v are two vectors in Rn, then uT is a row vector with 1 row and n columns. Multiplying uT by v results in a 1×1 matrix, which is just the scalar u⋅v.
The benefit of using the transpose to express the dot product is that it allows us to write the dot product of two vectors in terms of matrix multiplication, rather than being an entirely different type of operation. (In fact, as we’ve seen here, matrix multiplication is just a generalization of the dot product.)
There are other uses for the transpose, too, so it’s a useful tool to have in your toolbox.
The first three properties are relatively straightforward. The last property is a bit more subtle. Try and reason as to why it’s true on your own, then peek into the box below to verify your reasoning and to see an example.
Why is (AB)T=BTAT?
Let’s start with just (AB)T and reason our way from there. Define C=(AB)T. C is presumably the product of two matrices X and Y, we just don’t know what X and Y are. By the definition of matrix multiplication, we know that Cij is the dot product of the ith row of X and the jth column of Y. How can we express the product C=XY in terms of A and B?
Let’s work backwards. Since Cij=(AB)ijT=(AB)ji by the definition of the transpose, we know that:
Cij=(AB)ji=(row j of A)⋅(column i of B)=(column i of B)⋅(row j of A)
This is a little backwards relative to the definition of matrix multiplication, which says that:
Cij=(XY)ij=(row i of X)⋅(column j of Y)
In order for the two definitions of Cij to be consistent, we must have:
(column i of B)⋅(row j of A)=(row i of X)⋅(column j of Y)
Row i of X is the same as column i of B, if X=BT.
Column j of Y is the same as row j of A, if Y=AT.
Putting this together, we have:
C=(AB)T=BTAT
as we hoped!
To make things concrete, let’s consider two new matrices A and B:
Define x to be an array corresponding to the vector x=⎣⎡103⎦⎤.
Find the norm of the product Ax using np.linalg.norm.
Find the norm of the product Ax using the fact that ∥Ax∥2=xTATAx, and verify that you get the same answer.
Activity 1.2
Suppose M∈Rn×d is a matrix, v∈Rd is a vector, and s∈R is a scalar.
Determine whether each of the following quantities is a matrix, vector, scalar, or undefined. If the result is a matrix or vector, determine its dimensions.
Mv
vM
v2
MTM
MMT
vTMv
(sMv)⋅(sMv)
(svTMT)T
vTMTMv
vvT+MTM
∥v∥Mv+(vTMTMv)Mv
Activity 1.3
Let A=⎣⎡23−1141⎦⎤, B=[120123], and C=⎣⎡101011210−11−1⎦⎤.
Compute AB, then multiply the result by C.
Compute A, then multiply the result by BC. Do you get the same result as above? If so, what property of matrix multiplication guarantees this?
Determine a formula for (ABC)T, and verify that your result works. (Hint: Start with the fact that (AB)T=BTAT.)
Now, I’ll introduce several “special” types of matrices that will come in handy at various points throughout our journey.
Saying “the identity matrix” is a bit ambiguous, as there are infinitely many identity matrices – there’s a 1×1 identity matrix, a 2×2 identity matrix, a 3×3 identity matrix, and so on. Often, the dimension of the identity matrix is implied by context, and if not, we might provide it as a subscript, e.g. In for the n×n identity matrix.
Why is the identity matrix defined this way? It’s the matrix equivalent of the number 1 in scalar multiplication, also known as the multiplicative identity. If c is a scalar, then c⋅1=c and 1⋅c=c. (0 is known as the additive identity in scalar multiplication.)
Similarly, if A is squaren×n matrix and x∈Rn is a vector, then the n×n identity matrix I is the unique matrix that satisfies:
Ix=x for all x∈Rn.
IA=AI=A for all A∈Rn×n.
A good exercise is to verify that the identity matrix satisfies these properties.
A symmetric matrix is such that row 1 is the same as column 1, row 2 is the same as column 2, and so on. We’ll see several applications of symmetric matrices later in the course – for example, they are easy to work with in multivariate calculus.
But, where do they come from? Data usually isn’t symmetric: if X is a matrix in which each row is a data point and each column is a feature, then usually X is very tall, and thus can’t be symmetric.
Here’s the key: for any n×d matrix X, XTX is a symmetric d×d matrix.We can verify this using the fact that (AB)T=BTAT.
(XTX)T=XT(XT)T=XTX
I think of XTX as the dot product matrix of X, because its entries are the dot products of the pairs of columns of X. For example, let
XTX contains the dot products of the columns of X with each other. For instance, -9 in position (1,2) is the dot product of
row 1 of XT, which is column 1 of X, with
column 2 of X
The elements along the diagonal of XTX – 13, 37, and 2 – are the dot products of the columns of X with themselves, meaning they are the squared norms of the columns.
Usually, diagonal matrices are square, like the examples below.
[1001],[2003],⎣⎡−π000150003⎦⎤
Notice that the diagonal is down and to the right – position (1, 1) is the first diagonal element, position (2, 2) is the second diagonal element, and so on.
Diagonal matrices don’t have to be square. We could also call the following a diagonal matrix.
[100200]
What is their significance? Let’s observe what happens when we multiply a diagonal matrix by a vector, as we did in Activity 4. of Chapter 5.1.
D⎣⎡−3000π0005⎦⎤x⎣⎡123⎦⎤=⎣⎡−32π15⎦⎤
What happened to x after being multiplied by D? Each component was stretched. Element 1 of x was stretched by -3, element 2 was stretched by π, and element 3 was stretched by 5. The 0’s in the off-diagonal elements allowed D to scale each component of xindependently.
For instance, ⎣⎡100240356⎦⎤ is upper triangular, and ⎣⎡124035006⎦⎤ is lower triangular. I’ll have more to say on these matrices later in the term; for now, I just want you to be aware of their existence.
The final category of matrix I want to introduce here is the orthogonal matrix. It’s the first type of matrix here whose defining property can’t be determined just by looking at the individual elements of the matrix; it involves some computation.
Let’s consider the matrix
A=⎣⎡2321−2123⎦⎤
It is orthogonal, because ATA and AAT are both equal to the 2×2 identity matrix. What does this really tell us? When I discussed symmetric matrices above, I said that ATA for any matrix A contains the dot products of the columns of A with each other. So, if
unit vectors, since the dot product of each column with itself is 1
orthogonal, since the dot product of each column with every other column is 0
Since AAT=I, too, this means that A’s rows are also unit vectors that are orthogonal to each other.
So, orthogonal matrices are matrices whose
columns are unit vectors
rows are unit vectors
columns are orthogonal to each other
rows are orthogonal to each other
If a collection of vectors are all unit vectors and orthogonal, we may call that collection orthonormal. So, an orthogonal matrix has orthonormal columns and orthonormal rows.
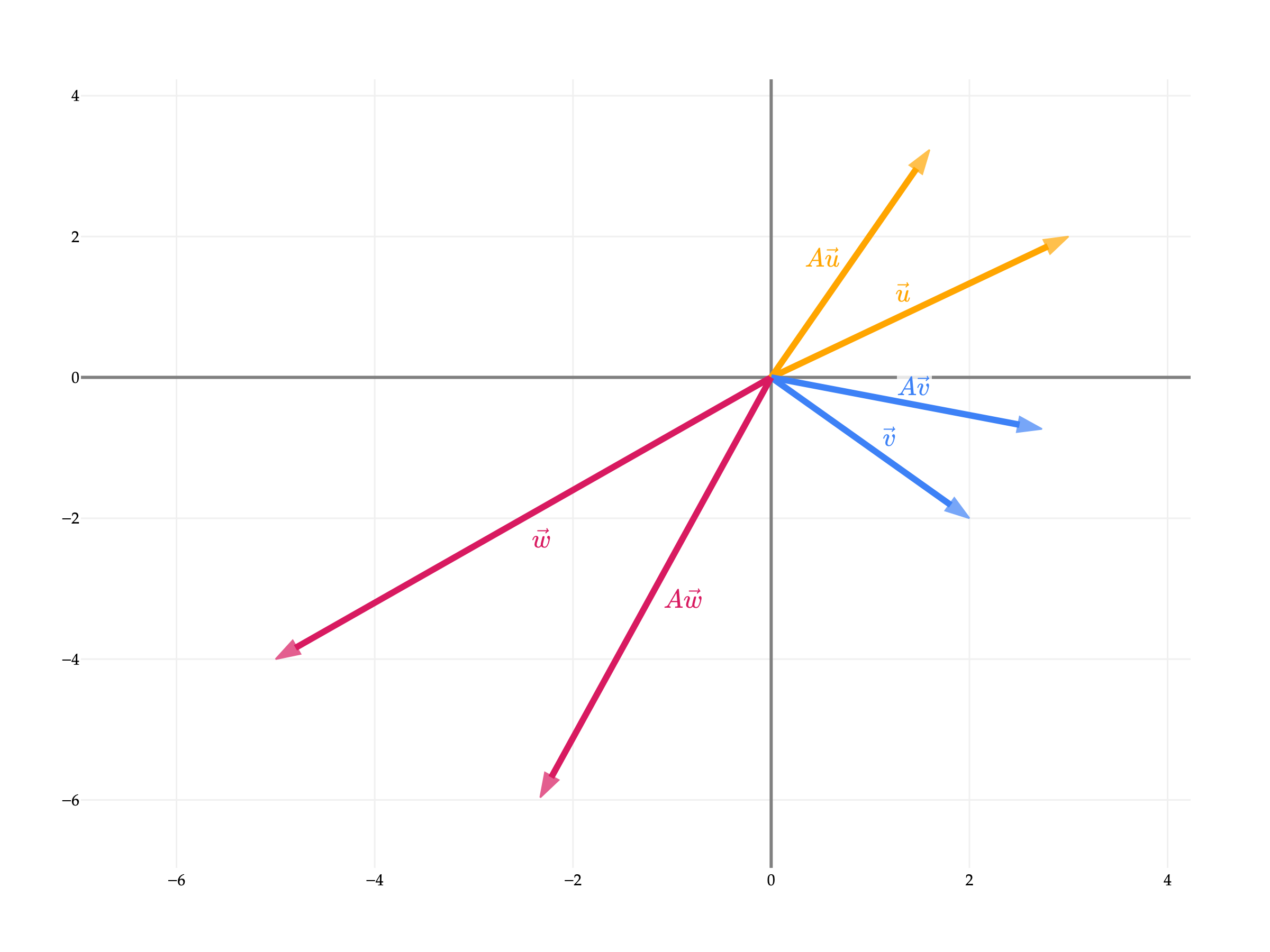
Let’s preview some ideas from Chapter 6.1, let’s visualize six vectors in R2.
u=[32] and Au
v=[2−2] and Av
w=[−5−4] and Aw
What do you notice about the vectors Au, Av, and Aw? and how they relate to u, v, and w?
from utils import plot_vectors
import numpy as np
A = np.array([[np.cos(np.pi/6), -np.sin(np.pi/6)], [np.sin(np.pi/6), np.cos(np.pi/6)]])
u = np.array([3, 2])
v = np.array([2, -2])
w = np.array([-5, -4])
Au = A @ u
Av = A @ v
Aw = A @ w
fig = plot_vectors([(tuple(u), 'orange', r'$\vec u$'),
(tuple(v), '#3d81f6', r'$\vec v$'),
(tuple(w), '#d81a60', r'$\vec w$'),
(tuple(Au), 'orange', r'$A \vec u$'),
(tuple(Av), '#3d81f6', r'$A \vec v$'),
(tuple(Aw), '#d81a60', r'$A \vec w$')], vdeltay=0.3)
fig.show(scale=3, renderer='png')
A corresponds to a rotation, since it rotates vectors by a certain angle (in this case, 6π radians, or 30∘) but doesn’t change their length. Why 6π? More on that in Chapter 6.1.
A question we can answer now: why does multiplying an x by A preserve its length? Let’s prove this, using the fact that ∥v∥2=v⋅v, which is also equal to vTv using our knowledge of the transpose operator.
∥Ax∥2=(Ax)T(Ax)=xTATAx=xTIx=xTx=∥x∥2
The length of Ax is the same as the length of x, because ATA=I! So, multiplying a vector by an orthogonal matrix preserves its length, and thus the only thing that could change is its direction.
Orthogonal matrices perform a rotation, which is a type of linear transformation. There exist plenty of different types of linear transformations, like reflections, sheers, and projections (which sound familiar). These will all become familiar in Chapter 6.1.
All I wanted to show you for now is that matrix multiplication may look like a bunch of random number crunching, but there’s a lot of meaning baked in.
The last thing I’ll note on orthogonal matrices is that just because a matrix satisfies ATA=I, it doesn’t mean that it is orthogonal: it just means that its columns are orthonormal. A may not even be square, which is a prerequisite for a matrix to be orthogonal. For instance,
Suppose A is an n×d matrix whose columns are orthogonal to each other, though not necessarily orthonormal. What type of matrix is ATA?
Solution
ATA is a diagonal matrix. Recall, ATA contains the dot products of the columns of A with each other. The diagonal elements are the dot products of the columns with themselves, which are the squared norms of the columns. The off-diagonal elements (i.e. the elements of ATA where i=j) are the dot products of the columns with each other, which are 0 because the columns are orthogonal. Since the columns aren’t necessarily orthonormal, the diagonal elements are not necessarily 1.