This section can be thought of as a detour through the main storyline of the course. Chapter 7.1 is where I connect the idea of projecting onto the column space of to that of linear regression.
Instead, here I’ll introduce a new algorithm that can be used to turn a collection of vectors into a more convenient form, and see how this can make the act of projecting onto the column space of much easier.
Why Orthogonalize?¶
Recall, a set of vectors are orthonormal if they are both:
pairwise orthogonal, meaning for all , and
each vector is a unit vector, meaning for all
Orthonormal vectors (and matrices containing them) are convenient to work with. For example, if ’s columns are the vectors , then , the matrix containing the dot products of the columns of , is the identity matrix.
(I know that I promised to use superscripts like to denote columns of a matrix, but I have my reasons for doing it this way in this section.)
As we’ve seen in Chapter 6.3, when projecting onto the column space of , the matrix – and its inverse – plays a big role in finding the optimal coefficients to multiply each column of by. Most matrices, by default, don’t have orthonormal columns. But if they did, then some of these calculations would be much, much simpler!
So, the goal here is to learn how to turn a linearly independent set of vectors into an orthonormal set of vectors with the same span, i.e. how to “orthogonalize” a set of vectors.
The Algorithm¶
The algorithm that produces this orthonomal set of vectors is called the Gram-Schmidt process. It exploits the fact that when you project onto , the error vector
is orthogonal to .
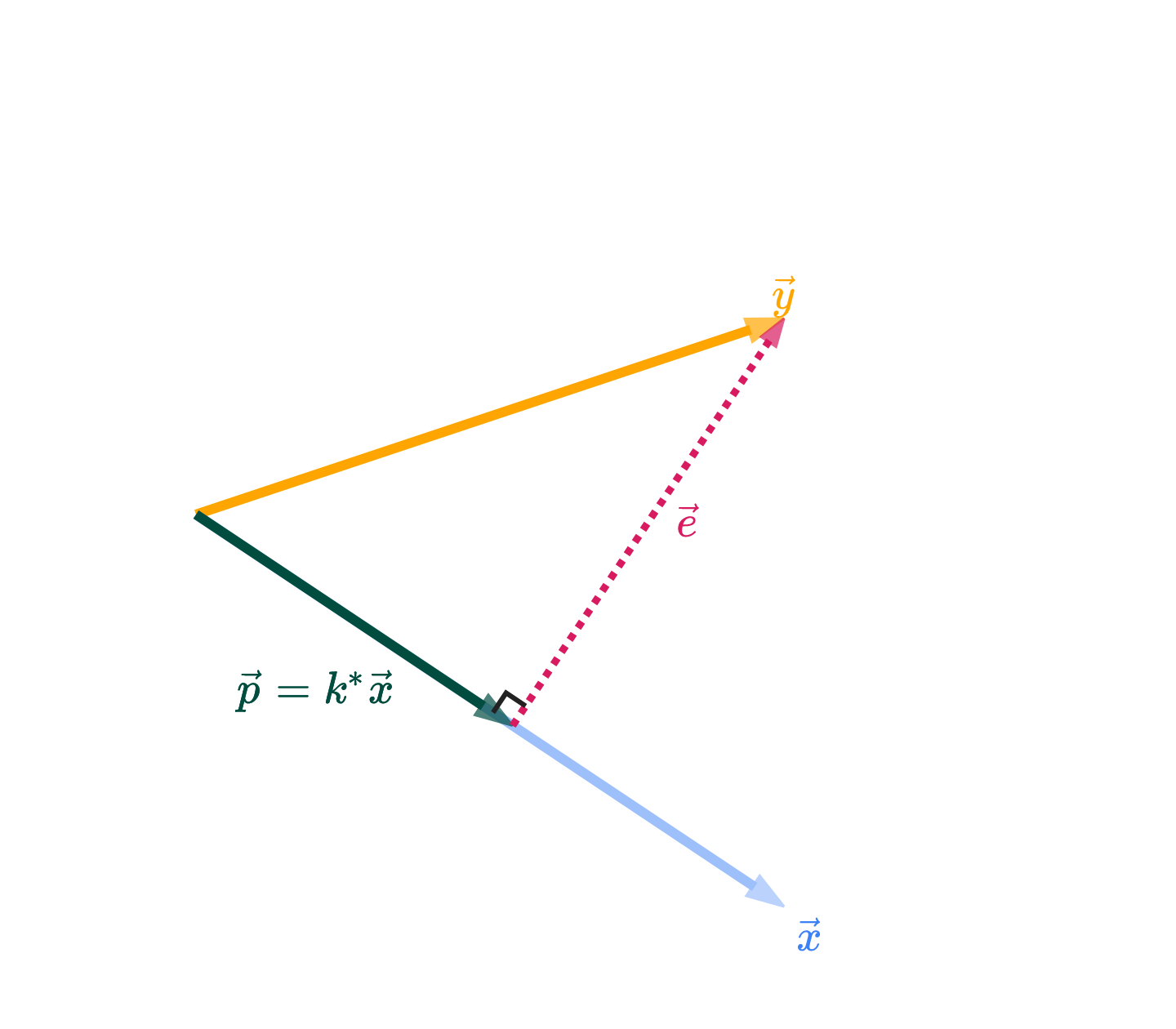
If you look in the figure above, the vectors and are orthogonal, and have the same span as and . The key takeaway is that if you’d like to “invent” vectors that are orthogonal to each other, you can construct them by iteratively projecting!
To illustrate how the algorithm works, let’s use as an example the vectors
These are three linearly independent vectors in , though they are not orthogonal. These vectors span some subspace . Our goal is to find an orthonormal set of vectors that spans the same . (In this case, is all of , but in general this process works even if .)
In what follows, let be the projection of onto , i.e. .
Iteration 1: Set .
In the first iteration, we simply take the first vector and copy it to . From now on, each new vector will be constructed to be orthogonal to all previously constructed ’s.
Iteration 2: Set .
is the same as the error vector from projecting onto , which we know is orthogonal to .
Even without actually calculating , we can see that it, by definition, must be orthogonal to .
With that understanding in mind, let’s evaluate explicitly.
Iteration 3: Set .
When constructed this way, is orthogonal to both and . Think of it this way: is a plane in ; after projecting onto this plane, the remaining part of that is orthogonal to the plane is . If that doesn’t make sense, execute and using the same general steps I followed in Iteration 2.
If there were more ’s, we’d continue this process, each time constructing a new that is orthogonal to all previously constructed ’s by “subtracting off” the parts we’ve already accounted for through the earlier ’s.
Now, are orthogonal to one another, but they are not yet unit vectors. To make them unit vectors, we simply need to divide each by its length.
Now, the vectors are orthonormal to one another, and they span the same subspace as the vectors !
A quick note on signs: you could multiply any of the ’s by -1 without changing the span of the collection, so if using a computer to compute the ’s, you might see them come out with different signs.
Notice above that in the top and in the bottom are parallel, it’s just that is a unit vector. The three ’s in the top figure are linearly independent but not orthogonal; the three ’s in the bottom figure are, however, orthonormal.
Gram-Schmidt and Projection¶
In general, we’re presumed to have a vector that we’d like to approximate as a linear combination of matrix ’s columns. Generally, ’s columns are not orthonormal – they may not even be linearly independent.
If we:
Remove the linearly dependent columns from
Use the Gram-Schmidt process to orthonormalize the remaining columns, and store them in the columns of
Then, the matrix that results has the same column space as , but solving the normal equations for and is much simpler.
Our problem now is slightly different: we’re trying to find the best linear combination of the columns of (not the columns of ) that approximates , i.e. we’re projecting onto the column space of . If we adjust our objective to this goal, then the best – the one that minimizes – satisfies
But, as I showed you at the start of this section, so this just reduces to
That’s it! No inversion required: we can compute with just a single matrix-vector multiplication.