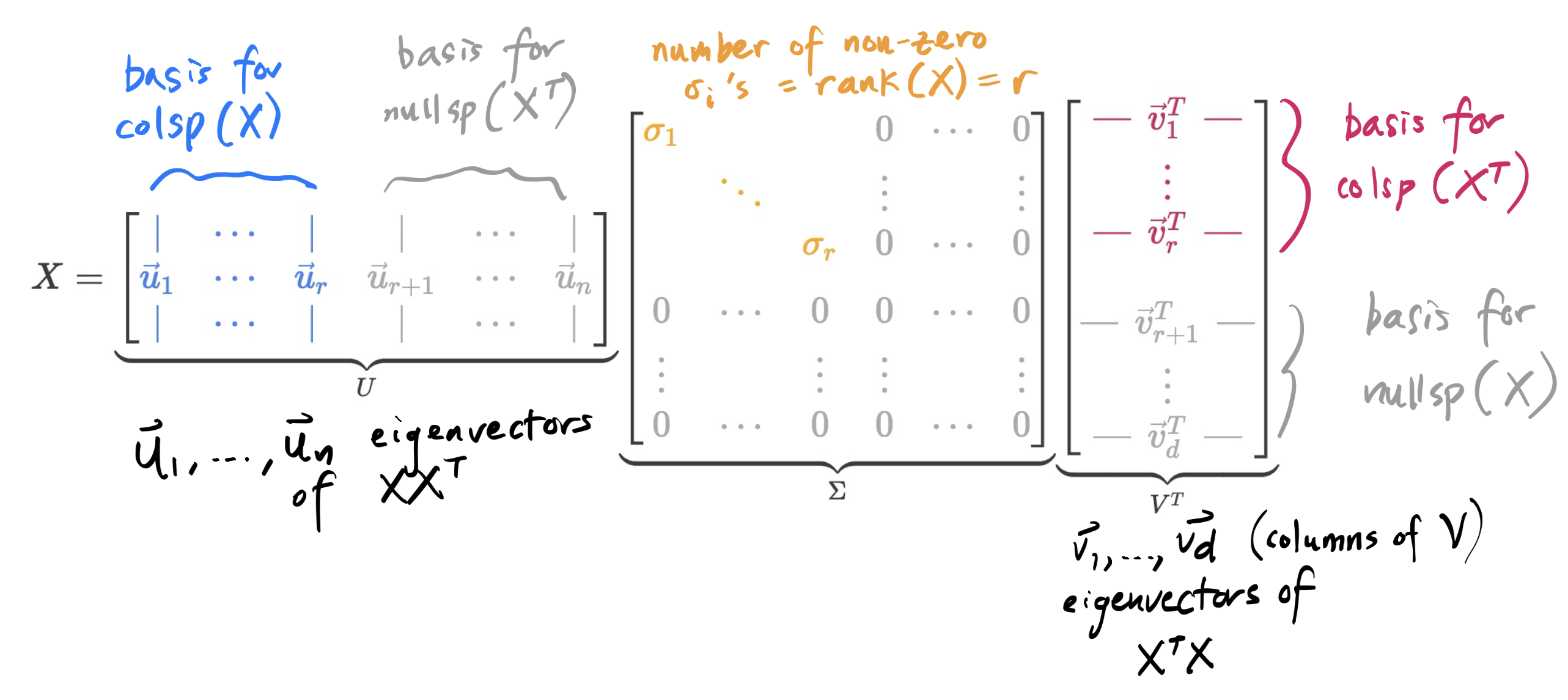
The version of the SVD we’ve constructed together is called the full SVD.
In the full SVD, U is n×n, Σ is n×d, and VT is d×d. If rank(X)=r, then
The first r columns of U are the left singular vectors of X and are a basis for colsp(X); the last n−r columns of U are a basis for nullsp(XT). Together, the columns of U span Rn.
The first r columns of V are the right singular vectors of X and are a basis for colsp(XT); the last d−r columns of V are a basis for nullsp(X). Together, the columns of V span Rd.
The full SVD is nice for proofs, but is a little... annoying to use in real applications, because it contains a lot of 0’s. The additional n−r columns of U and d−r columns of V are included to make U and V orthogonal matrices, but end up getting 0’d out when multiplied by the corresponding 0’s in Σ.
Remember that X=UΣVT is equivalent to XV=UΣ, which says that, for i=1,2,...,d,
Xvi=σiui
but when i>r, all this says is 0=0:
Xvi=0, since vr, vr+1, ..., vd are all in nullsp(X), and
The compact SVD throws away the 0’s in Σ and the corresponding columns in U and V. In the annotated figure above, it keeps only the first r columns inU, first r values inΣ, and first r rows inVT.
That is, the compact SVD says X=UrΣrVrT, where Ur is n×r, Σr is r×r, and VrT is r×d.
The full and compact SVDs are equivalent, in that X=UΣVT=UrΣrVrT. But the individual components are of different sizes:
Full SVD
Compact SVD
U
n×n
n×r
First r columns of U are basis for colsp(X)
Σ
n×d
r×r
Number of non-zero σi’s is r=rank(X)
VT
d×d
r×d
First r rows of VT are basis for colsp(XT)
Ur and Vr are no longer orthogonal matrices, since only square matrices can be orthogonal. However, their columns are still orthonormal, meaning UrTUr=Ir×r and VrTVr=Ir×r.
Each term σiuiviT is an outer product of ui and vi, scaled by σi. Outer products are rank-one matrices: each column of σiuiviT is a multiple of ui, and each row of it is a multiple of viT.
This outer product view of matrix multiplication is not one that we’ve emphasized a ton in this course, but it can be useful in certain contexts, as we’re about to see. To see how it works, let’s revisit our first example.
Since 15>3, the first outer product contributes more to X than the second one does.
We can think of the singular values as representing the importance of the corresponding singular vectors in representing X. Since we sort singular values in decreasing order, σ1≥σ2≥...≥σr>0, the first outer product is always the most important one, the second outer product is the second most important one, and so on.
Our most recent observation is that the SVD X=UΣVT allows us to write X as a sum of rank-one matrices, in decreasing order of importance.
X=most importantσ1u1v1T+second most importantσ2u2v2T+⋯+least importantσrurvrT
In many practical applications, the full matrix X can be too large to store or process. In such cases, we can produce a low-rank approximation of X by summing fewer than r of these rank-one matrices. In the example above, X was of rank 2, so a rank-1 approximation of X would just be the first outer product, σ1u1v1T, which is in blue above.
A common application of the SVD and low-rank approximations is to compress images. How so? Consider the following grayscale image of my (16 year old) dog, Junior.
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
# Load the image and convert to grayscale
img = Image.open('imgs/junior.jpeg').convert('L')
img_arr = np.rot90(np.array(img), k=3)
# Show the grayscale image
plt.figure(figsize=(4*1.5, 3*1.5))
plt.imshow(img_arr, cmap='gray')
plt.axis('off')
plt.show()
This image is 300 pixels wide and 400 pixels tall. Since the image is grayscale, each pixel’s intensity can be represented by a number between 0 and 255, where 0 is black and 255 is white. These intensities can be stored in a 400×300 matrix. The rank of this matrix is likely 300, since it’s extremely unlikely that any of the 300 columns of the image are exactly representable as a linear combination of other columns.
But, as the SVD reveals, the image can be approximated well by a rank-k matrix, for a k that is much smaller than 300. We build this low-rank approximation of the image by summing up k rank-one matrices.
rank k approximation of image=i=1∑kσiuiviT
A slider should appear below, allowing you to select a value of k and see the corresponding rank-k approximation of Junior.
import numpy as np
import plotly.graph_objs as go
from PIL import Image
IMAGE_PATH = 'imgs/junior.jpeg'
# Load image (fallback to dummy if not found), rotate 90º clockwise, and resize to 3:4 aspect ratio (e.g., 300x400)
try:
img = Image.open(IMAGE_PATH).convert('L')
img = img.rotate(-90, expand=True) # Rotate 90º clockwise
img = img.resize((300, 400), Image.LANCZOS) # 3:4 aspect ratio (width, height)
img_arr = np.array(img)
except FileNotFoundError:
H, W = 400, 300 # 3:4 aspect ratio
img_arr = np.zeros((H, W), dtype=np.uint8)
for i in range(H):
for j in range(W):
img_arr[i, j] = 200 if ((i // 10) % 2 == (j // 10) % 2) else 50
# Compute SVD
U, S, VT = np.linalg.svd(img_arr.astype(float), full_matrices=False)
max_k = len(S)
def get_reconstruction(k):
k = max(1, min(k, len(S)))
Uk = U[:, :k]
Sk = S[:k]
VTk = VT[:k, :]
recon = Uk @ np.diag(Sk) @ VTk
return 255 - np.clip(recon, 0, 255).astype(np.uint8)
# k=1, k=31, k=61, k=91, ..., max allowed (up to len(S))
ks = list(range(1, 51))
if ks[-1] != max_k-1:
ks.append(max_k)
# Create frames (each frame is a Heatmap of the reconstructed image)
frames = []
for k in ks:
z = get_reconstruction(k)
frames.append(
go.Frame(
data=[
go.Heatmap(
z=z,
zmin=0,
zmax=255,
colorscale=[[0, "white"], [1, "black"]],
showscale=False
)
],
name=str(k)
)
)
# Initial trace uses k=1
initial_z = get_reconstruction(1)
initial_trace = go.Heatmap(z=initial_z, zmin=0, zmax=255, colorscale=[[0, "white"], [1, "black"]], showscale=False)
fig = go.Figure(
data=[initial_trace],
frames=frames
)
# Slider that calls animate on each frame
slider_steps = []
for k in ks:
step = {
"args": [
[str(k)], # frame name
{
"frame": {"duration": 0, "redraw": True},
"mode": "immediate",
"transition": {"duration": 0}
}
],
"label": str(k),
"method": "animate"
}
slider_steps.append(step)
sliders = [{
"active": 0,
"pad": {"t": 50},
"steps": slider_steps,
"currentvalue": {"prefix": "Rank k: ", "font": {"size": 14}}
}]
fig.update_layout(
sliders=sliders,
width=300, # width matches aspect ratio
height=480, # height matches aspect ratio
margin=dict(l=20, r=20, t=0, b=0),
font=dict(family="Avenir"),
)
# Hide axes
fig.update_xaxes(visible=False)
fig.update_yaxes(visible=False)
fig.update_yaxes(autorange="reversed")
fig.show()
Loading...
To store the full image, we need to store 400⋅300=120,000 numbers. But to store a rank-k approximation of the image, we only need to store (1+400+300)k=701k numbers – only the first k singular values, along with u1,u2,...,uk (each of which has 400 numbers), and v1,v2,...,vk (each of which has 300 numbers). If we’re satisfied with a rank-30 approximation, we only need to store 701⋅30=21,030 numbers, which is a compression of 21,030120,000≈5.7 times!
Notice: The signs of the columns of U and V are not uniquely determined by the SVD. For example, we could replace u1 with −u1 and v1 with −v1 to get the same matrix X. The values for U we found had flipped signs for columns 1, 2 relative to the values returned by np.linalg.svd.
The first column of numpy’s u is the negative of our first column of U.
Both second columns are the same.
The latter two columns are different. Why? There are infinitely many orthogonal bases for the null space of XT, which are what the last two columns of U represent. We just picked a different choice than numpy did.
All n×d matrices X have a singular value decomposition X=UΣVT, where U is n×n, Σ is n×d, and V is d×d.
The columns of U are orthonormal eigenvectors of XXT; these are called the left singular vectors of X.
The columns of V are orthonormal eigenvectors of XTX; these are called the right singular vectors of X.
Both XXT and XTX share the same non-zero eigenvalues; the singular values of X are the square roots of these eigenvalues.
The number of non-zero singular values is equal to the rank of X. It’s important that we sort the singular values in decreasing order, so that σ1≥σ2≥...≥σr>0, and place the singular vectors in the columns of U and V in the same order.
σi=λi
A typical recipe for computing the SVD is to:
Compute XTX. Place its eigenvectors in the columns of V, and place the square roots of its eigenvalues in the diagonal of Σ.
To find each ui, use Xvi=σiui, i.e. ui=σi1Xvi.
The above rule only works for σi>0. If σi=0, then the remaining ui’s must be eigenvectors of XXT for the eigenvalue 0, meaning they must lie in the nullspace of XT.
The SVD allows us to interpret the linear transformation of multiplying by X as a composition of a rotation by VT, a scaling/stretching by Σ, and a rotation by U.
The SVD X=UΣVT can be viewed as a sum of rank-one matrices:
X=i=1∑rσiuiviT
Each piece σiuiviT is a rank-one matrix, consisting of the outer product of ui and vi. This summation view can be used to compute a low-rank approximation of X by summing fewer than r of these rank-one matrices.