If you’re reading this, you’ve chosen to take a course that explores the mathematical foundations of machine learning, with a particular focus on linear algebra. I’m not going to assume you know anything about machine learning or linear algebra. But, before I dive into any details, I do want to give you a sense of what machine learning actually is, and how recent advances like ChatGPT – which you almost certainly know something about – connect to what you’ll learn.
Motivation¶
Example: Handwritten Digit Recognition¶
Using your mouse, draw a ✍️ digit in the box below. As you draw, a model (source) will try and guess the digit you’re drawing, and describe how confident it is in its guess.
Draw a few different digits, and hit “clear” after each one. You’ll notice that the model isn’t perfect (for instance, it often confuses my 0s with 2s, 5s, 7s, and 9s, depending on where in the box I draw the 0), but it works reasonably well.
How did the model figure out how to identify digits, and why is it sometimes wrong?
If you were to implement such a model, one technique you could try is to hardcode a bunch of if-statements that check for certain patterns in the digit you drew. For example, you could check if the digit has a straight line in the middle, as that would make it likely to be a 1, 7, or 9; or if it has a closed loop, as that would make it likely to be a 0, 2, 4, 6, 8, or 9. But, this is very tedious, and requires you to have a deep understanding of the patterns that make up each digit. And if there were 100 possible digits instead of 10, this would be much more difficult.
The Machine Learning Way¶
Machine learning uses a different approach. Machine learning is about automatically learning patterns from data.
In the case of the digit recognition model, the creators of the model showed the model thousands of pictures of handwritten digits, along with the correct answer for each digit. These correct answers are called labels. The model then used this data to learn the patterns that make up each digit. This process, of having a model learn the patterns of the data so that we can use it to make predictions, is called training the model.
The specific dataset this model was trained on is called the MNIST database, a common dataset used to test and benchmark machine learning models.

A few of the images in the MNIST dataset.
I’m using the term “model” loosely here. One, I haven’t formally defined the term, and I also haven’t actually specified how the model makes its guesses. There are plenty of types of models that we could train for the purposes of digit recognition – neural networks are the most popular choice these days, but decision trees, support vector machines, logistic regression, and so on are all reasonable choices. More flexible models can learn more complex patterns, but come with the risk of overfitting to the training data; this is an idea we’ll discuss more in Chapter 1.2.
The MNIST database contains 70,000 images of handwritten digits, each of which is grayscale (no color) and 28x28 pixels. The dataset contains the true labels for each image – that is, the model is told that the first row above contains all 0s, the second row contains all 1s, and so on. If we wanted to instead build a model that could guess whether an image is of a cat, dog, or hamster, we’d need to show the model many labeled images of cats, dogs, and hamsters.
A Brief History¶
Machine learning – and more recently, artificial intelligence – are hot topics these days, and indeed, new breakthroughs appear every few months. But, the origins of the field are much, much older than you and me.
Linear regression, which I think of as the foundation of machine learning, was first used in the early 1800s by physicists Legendre and Gauss to predict the motions of bodies in the solar system. That’s the same Gauss behind the Gaussian distribution, i.e. normal distribution or bell curve, that is ubiquitous in statistics and that we’ll study in Chapter 6 of the course. (In particular, we’ll learn about how the normal distribution plays a role in machine learning.)
An early sketch by Gauss, when trying to determine the motion of the planet Ceres, for which he developed the method of least squares.
Regression was then given the name “regression” and further developed by Galton and Pearson in the late 1800s to predict the heights of children given the heights of their parents. Galton was the cousin of Charles Darwin and was the originator of the field of eugenics, which led to a dark period in history.
Neural networks, which power most of the advances you’ve heard of recently, were first developed by neuroscientists in the 1940s to model the behavior of neurons in the brain. For now, think of a neural network as a sophisticated type of model that can be trained on data to make predictions. The popularity of neural networks skyrocketed in the early 2010s, after they were shown to outperform traditional AI-but-not-neural-network-based models on tasks like image recognition. This improvement in performance was made possible by several factors, including new mathematical techniques but also the advent of GPUs that made it possible to train models on large datasets efficiently. (I’ll touch more on what a GPU is and why they’re relevant in Chapter 2.)
The physicists and statisticians of the 1800s did not think they were “doing” machine learning, as that term only came into use in the 1960s. To hear more about how machine learning and statistics are related fields, but with slightly different goals, read the famous Two Cultures paper by Leo Breiman. And if you want to know more about the history of statistics, machine learning, and computer science, this seminar course I taught at UC San Diego might be of interest to you.
Supervised Learning¶
There are several types of problems that we can use machine learning to solve. The taxonomy below shows some of them.

Source: Sam Lau
Supervised learning is the type of machine learning that we’ll spend most of our time on, and the digit recognition problem from above is an example of a supervised learning problem.
The “supervising” comes from having a correct answer (label) for each situation in the dataset; you can think of the computer as being “supervised” by the correct answers.
There are two types of supervised learning problems: classification and regression.
Classification¶
In a classification problem, the label is a category, i.e. a categorical variable, with a finite number of possible values.
| Example | Labels |
|---|---|
| Digit recognition | 0, 1, 2, 3, 4, 5, 6, 7, 8, or 9 |
| Email spam detection | “spam” or “not spam” |
| Image classification | “dog”, “cat”, “hamster”, or “zebra” |
| Medical diagnosis | “diabetes” or “no diabetes” |
| Risk assessment | “low risk”, “medium risk”, or “high risk” |
The email spam detection and medical diagnosis problems are binary classification problems, as there are only two possible labels. In binary classification problems, we typically represent the labels as 1 (spam, diabetes) and 0 (not spam, no diabetes).
As another example, suppose we have a dataset of penguins. For each penguin in the dataset, we know its bill length in millimeters, its body mass in grams, and its species, which is either Adelie, Chinstrap, or Gentoo. The dataset shown below reflects real data about real penguins in Antarctica; read more about the dataset here.
The boxed column contains the labels for each penguin. Think of this as the “” in “given , predict ”, or as the answer key.
We can use a scatter plot to visualize the relationship between body mass and bill length, with colors indicating the species.
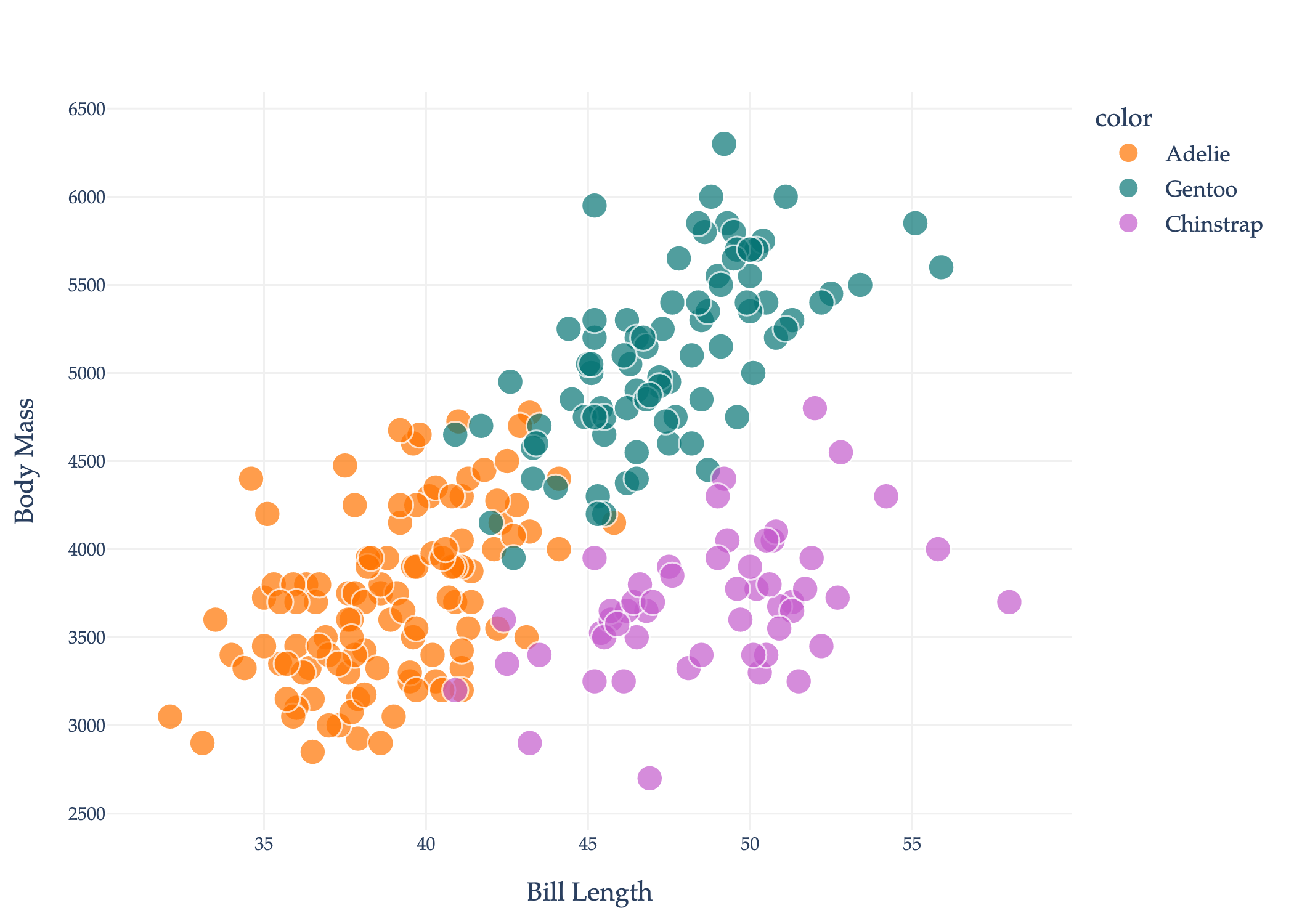
Fun fact: our local Detroit Zoo is home to Chinstrap and Gentoo penguins.
Once we train a model to predict the species of penguins, we can use it to predict the species of new penguins who weren’t in our original dataset. All models for this task take the form of a function :
where can only output one of three things: Adelie, Chinstrap, or Gentoo.
The decision boundaries of two different models – that is, two different functions – are shown below. The regions are colored based on what the model would predict for a new penguin.
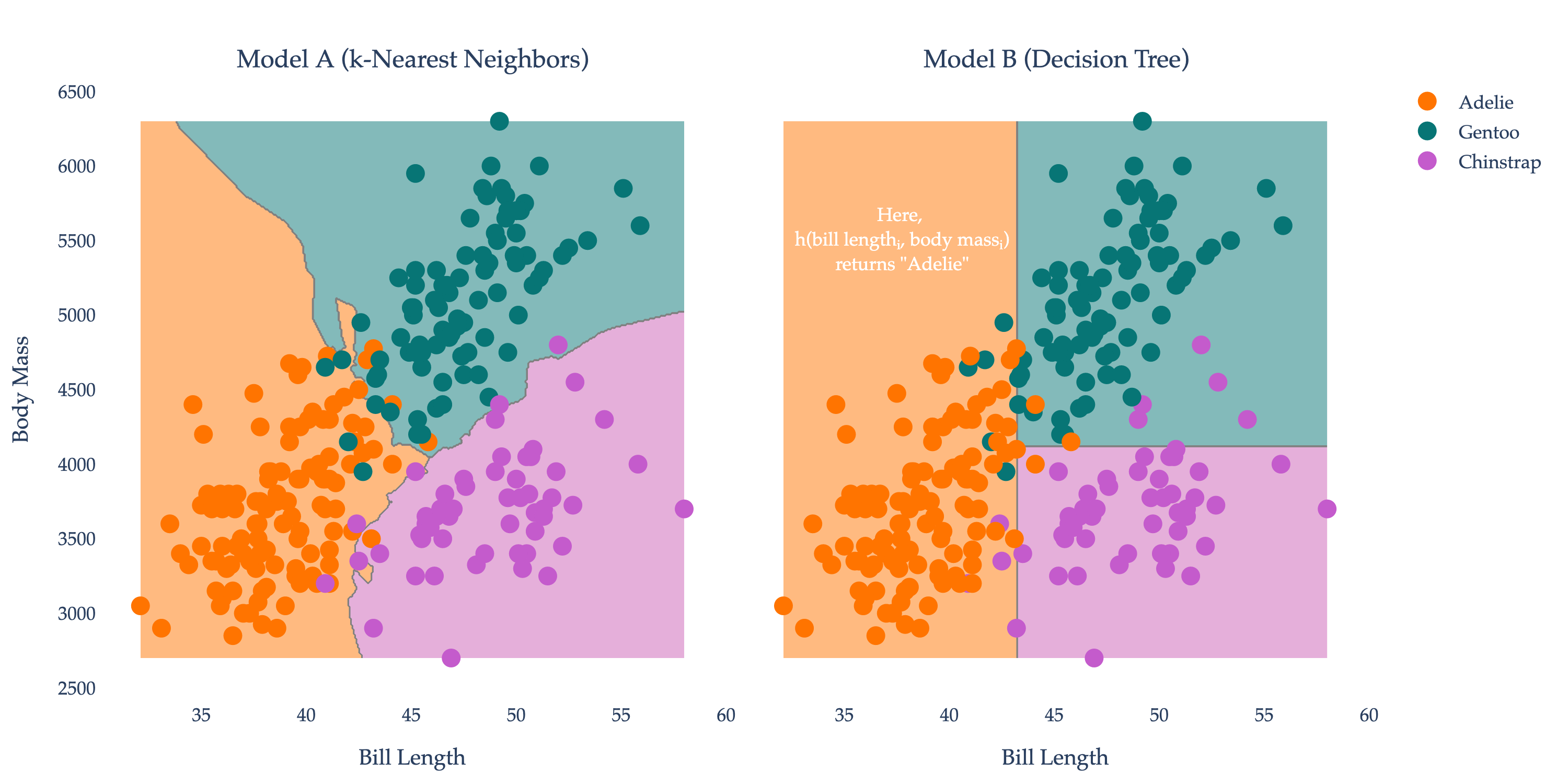
For instance, if some new penguin comes along with a bill length of 38 mm and a body mass of 6000 g, Model A would predict that it is a Gentoo penguin, while Model B would predict that it is an Adelie penguin. You can think of a model’s job as being to best separate the different species of penguins, based on the characteristics of the penguins it has access to. In order for a model to be useful, it needs to be able to make good predictions for new penguins, not just the penguins it already saw.
I’ve provided comprehensive examples of classification problems above, mostly because most of our semester will involve regression, not classification, and I want to make sure you’re familiar with the broad landscape of machine learning.
Regression¶
In a regression problem, the label is a continuous variable, i.e. a numerical variable that can take on any real number.
| Example | Labels |
|---|---|
| Commute time prediction | Times in minutes (82, 63.1256, -4, etc.) |
| House price prediction | Prices in dollars |
| Temperature prediction | Degrees in Fahrenheit |
The first problem mentioned, commute time prediction, is the one we’ll begin studying in Chapter 1.2; we’ll revisit it throughout the semester. Training a model will involve finding a useful function such that:
In the context of the penguin example, what might a regression problem look like? One possibility is to predict the body mass of a penguin given its bill length, i.e. to find a function such that:
Three possible functions are shown below. Each function’s predictions are shown in orange.
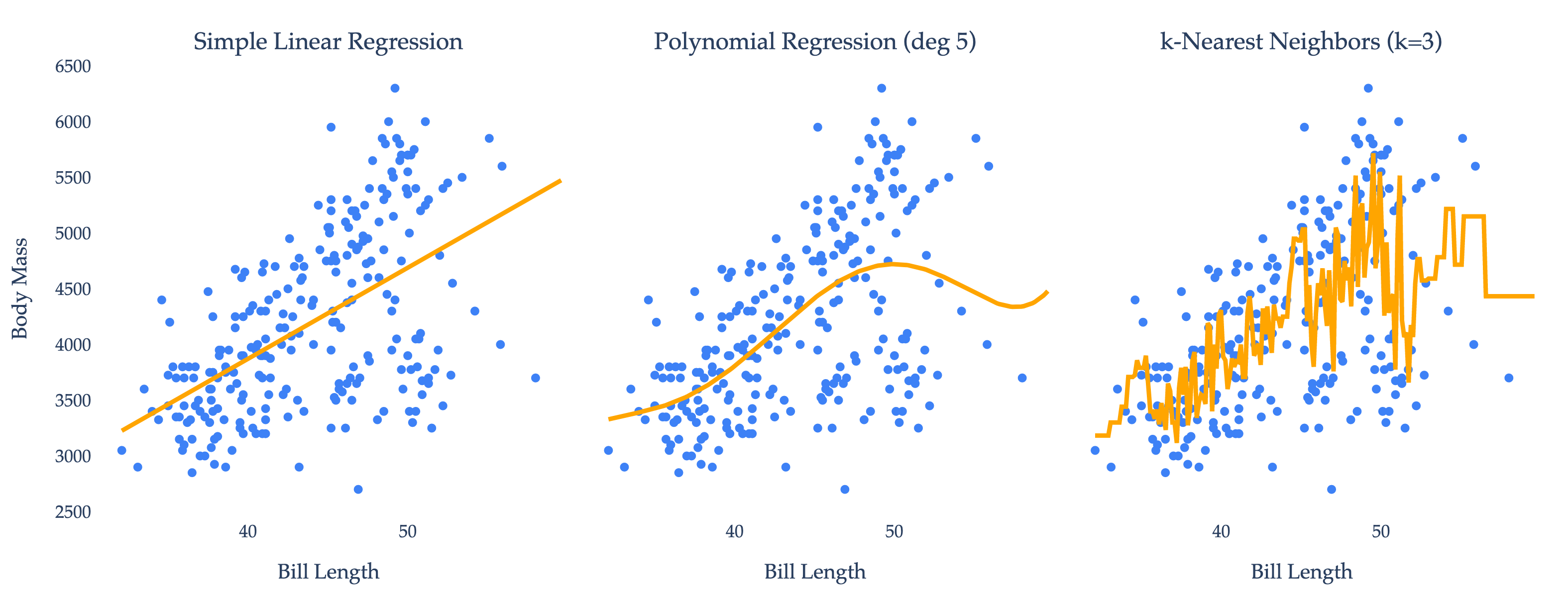
In Chapter 1.2, we’ll learn how to find models that make good predictions, starting with (a simpler version of) the simple linear regression model from above.
Activity 1
Identify whether each of the following problems is a classification or regression problem.
Given customer purchase history and demographics, predict whether they will buy a premium membership next month.
Using sensor data from manufacturing equipment, predict the remaining useful life of a machine component in hours.
Based on patient symptoms and vital signs, determine if treatment should be aggressive, moderate, or conservative.
Using weather data and soil conditions, predict crop yield per acre for the upcoming harvest season.
Given user behavior patterns on a website, predict which content category they will click on next.
The distinction between classification and regression isn’t always straightforward. For instance, predicting the exact number of times a customer will visit a website before making a purchase is considered a regression problem, even though the possible outcomes are limited to whole numbers like 0, 1, 2, 3, 4, 5, and so on, rather than any real value as in the other regression examples given above.
Unsupervised Learning¶
In supervised learning, the computer is “supervised” by the correct answers in its goal to find a function that makes good predictions. But, what if we don’t have any answers, and aren’t trying to predict anything?
Our focus in this course will mostly be on supervised learning, but I’ll briefly discuss two common forms of unsupervised learning: clustering and dimensionality reduction.
Clustering¶
Imagine you work at Netflix, and keep track of the ratings each user gives to each TV show. You might want to find groups of users who have similar tastes, so that you can recommend shows to them that they’re likely to enjoy.
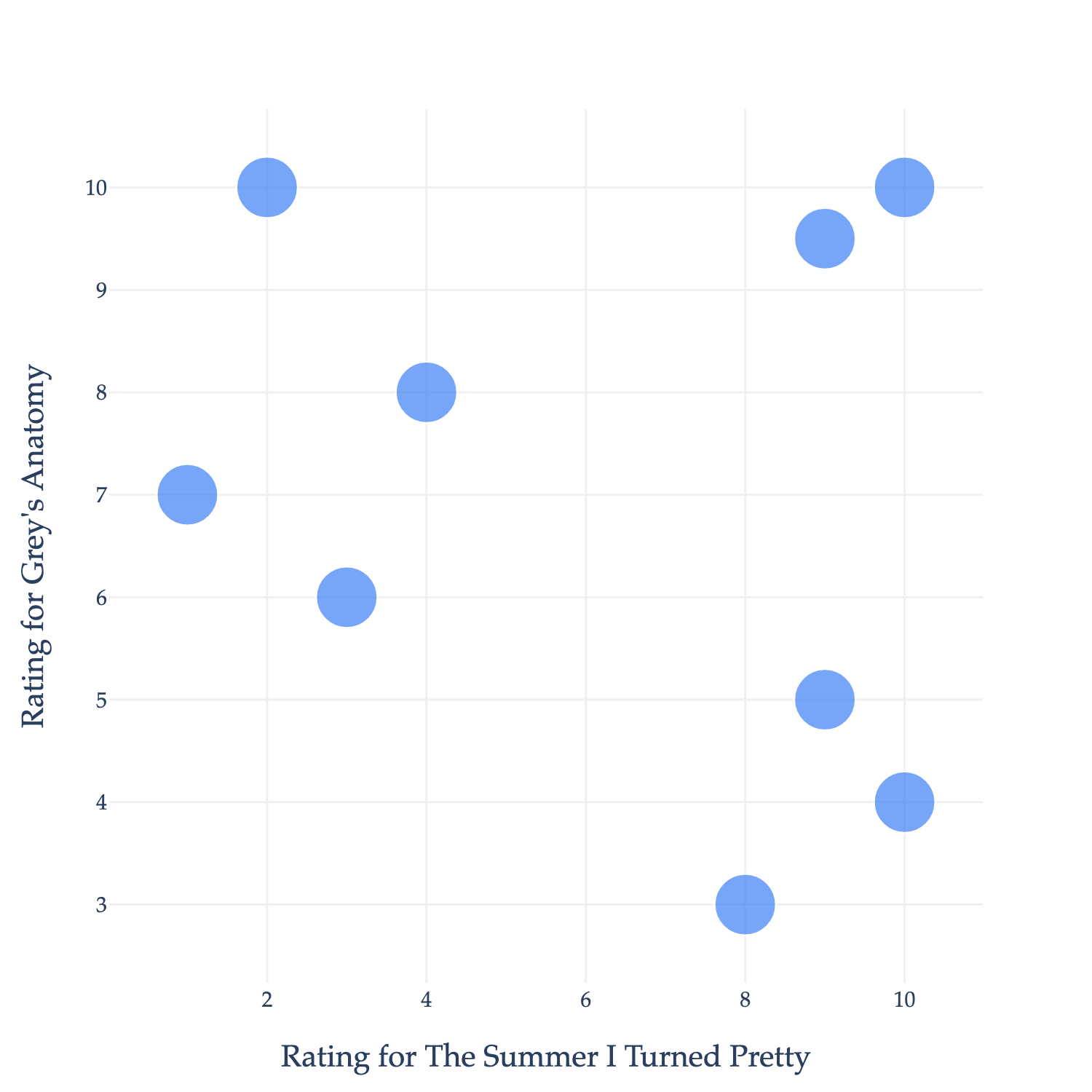
Neither of these shows are on Netflix, but they’re what I spent the summer watching, so they’ll have to work for now.
Each point in the plot above represents a single user. We could try and predict a user’s rating for Grey’s Anatomy (GA) given their rating for The Summer I Turned Pretty (TSITP), which would be a supervised learning (regression) problem, but that’s not what we’re investigating now.
Instead, let’s treat the data as unlabeled. You might notice that the data naturally falls into three groups, or clusters:
The top-left group doesn’t like TSITP (a romantic drama) but does like GA (a medical drama).
The bottom-right group likes TSITP, but not GA.
The bottom-left group likes both TSITP and GA.
If I could mathematically describe these clusters, I could use their boundaries to recommend shows to other users. For instance, if most users in the bottom-right cluster like, say, The Office, and some new user who hasn’t watched The Office but likes TSITP and GA comes along, I could recommend The Office to them.
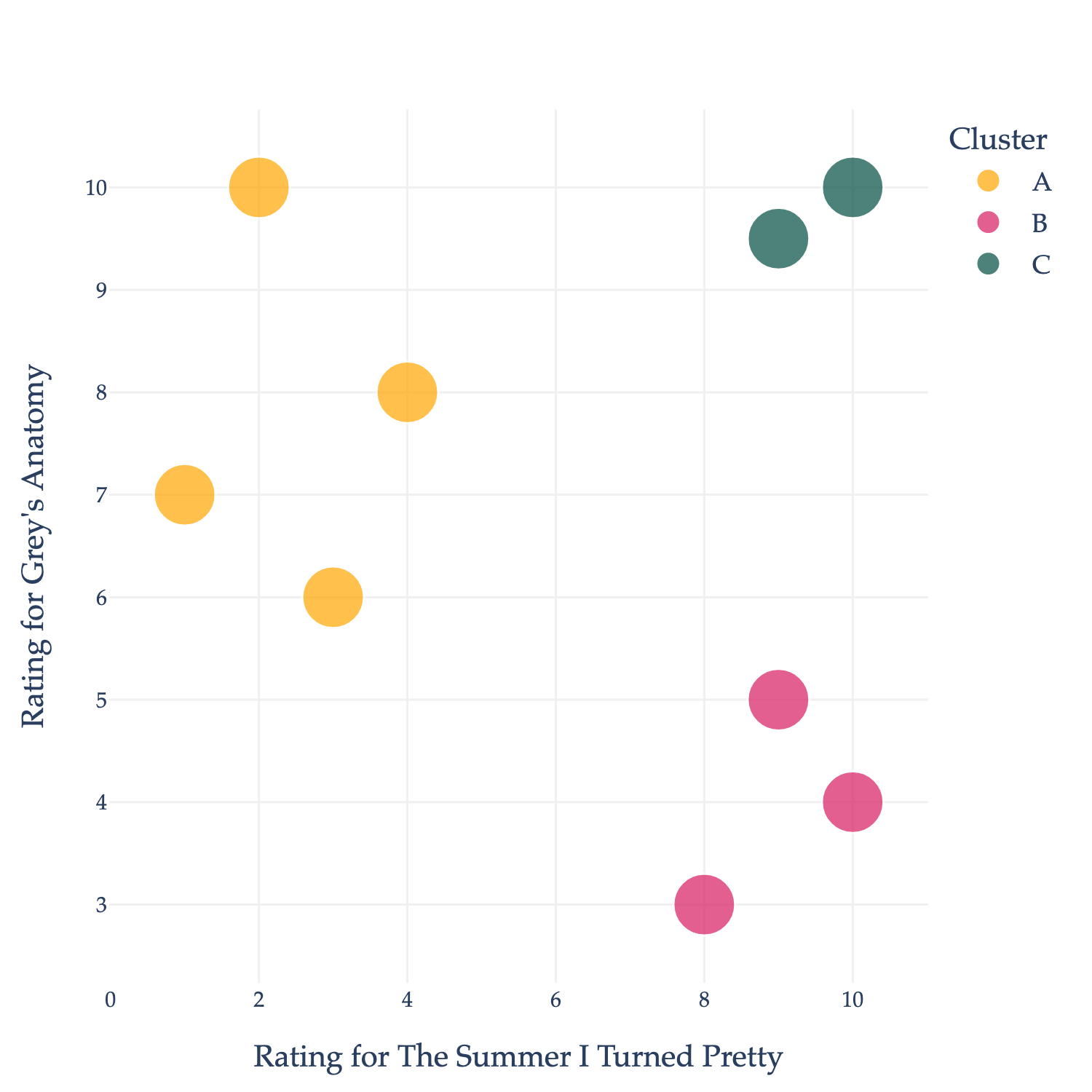
Placing points into clusters seems easy in the example above, but in practice, Netflix has millions of users and thousands of shows, meaning that the data is too large to visualize, much less cluster by hand. There are a variety of clustering algorithms that exist, each with their own strengths and weaknesses. We will not discuss clustering in this course – you’ll learn more in a future course dedicated to machine learning – but you can read more about how different clustering algorithms work here.
Activity 2
How would you explain the difference between clustering and classification to someone with no background in computer science or machine learning?
Dimensionality Reduction¶
As alluded to above, we’ll soon work with datasets with thousands of pieces of information (known as features) for millions of individuals. We typically store this information in a table or matrix, where each row corresponds to an individual and each column corresponds to a feature.
To illustrate, let’s return to the digit recognition example from the start of the section. I mentioned that each image in the dataset is a 28x28 pixel image, which means that to train the model, we’re using features per image. A table containing this information would have 70,000 rows (one per image) and 784 columns (one per pixel).
Activity 3
Why do you think most of the values above are 0?
This dataset is far too high-dimensional to visualize all at once – to draw a scatter plot as we did in earlier examples above, we’d need to be able to see 784 dimensions at once, while we can only see 3. We can look at a few images at a time, but we have no tool for visualizing the entire dataset.
That’s where dimensionality reduction comes in.
A naïve approach to dimensionality reduction would be to simply drop some of the features. For instance, if we wanted to draw a scatter plot containing all 70,000 images, we could pick just 2 of the 784 features (pixels) to plot against each other. But, this would lose a lot of information, as just two pixels don’t tell us much about an image.
More sophisticated approaches, like principal component analysis (PCA), can “invent” new features that capture the most important information in the dataset.
Below, you’ll find the result of applying PCA to the MNIST dataset. Each point corresponds to an image. We’ve actually only included a random sample of 10,000 of the 70,000 images, as the full dataset would crowd the plot too much.
The PCA process did not use the labels in the dataset, i.e. it did not factor in whether the image was actually of a 0, 1, 2, 3, etc. when inventing these two new features. But, you’ll notice that in the plot of new feature 2 vs. new feature 1, the images are roughly clustered by true digit! For example, the 0s (middle right) all look similar to one another in 2D space. The plot above is interactive, so you can hover over a point to see its true digit.
We will cover PCA in depth in Chapter 5 of these notes – it is surprisingly involved, and requires a deep understanding of linear algebra to fully grasp. All in due time!
Reinforcement Learning¶
Reinforcement learning is less about finding a function that makes good predictions or finding structure in data, and more about finding a function (formally called a policy) that makes good decisions. Reinforcement learning is likened to the way humans pick up new skills, like cooking or riding a bike – by trying something, failing, and trying again, now equipped with the knowledge of what worked and what didn’t.
Perhaps the most famous example of reinforcement learning is AlphaGo, a model trained by Google DeepMind to play the game Go. Go is a board game similar to chess or checkers, but with a 19x19 grid and more sophisticated rules. To train AlphaGo, first, researchers showed the model 30 million games of Go played by human players. Then, they had the model play many games of Go against itself, giving it a reward for winning and a penalty for losing. Eventually, through trial-and-error, the model learned to play Go at a higher level than the human players. In 2016, AlphaGo defeated the reigning world champion at the time.

Watch the AlphaGo documentary for free on YouTube.
We won’t discuss reinforcement learning any further in this course. If you’d like to learn more, start by reading this blog post. It was written by Demis Hassabis, the CEO of Google DeepMind – who also recently won the Nobel Prize in Chemistry – and explains the inner workings of AlphaGo in 2016 before it beat the world champion. I like this post not only because it’s written in a way that’s accessible to non-technical readers, but also because it shows you a snapshot of the growing excitement surrounding machine learning a decade ago.
Deep Learning¶
“Deep learning” is a popular term that doesn’t appear in the taxonomy I presented earlier, but it’s a term you’ve probably heard of.
All three types of machine learning – supervised learning, unsupervised learning, and reinforcement learning – could involve “deep learning”, which really just means machine learning using neural networks. Neural networks are called “deep” because they can have many “layers” of computation, i.e. many functions that are applied to the input data before returning a prediction, representation, or action.
For example, here’s a neural network with several layers, that could be used to predict the species of a penguin given its bill length and body mass, by first predicting the probability of each species.
While we won’t spend much time on neural networks in this course – you’ll need to wait for your next machine learning course to see them in depth – we will spend the entire semester understanding all of the operations they use and how they work together. Every line, circle, and box you see in the diagram above represents some sort of operation in linear algebra.
Large Language Models¶
I’ve given you an overview of three big branches of machine learning: supervised learning, unsupervised learning, and reinforcement learning. What’s not clear is how large language models, like ChatGPT, fit into this taxonomy. It turns out that large language models are created using all three of these types of machine learning (and also deep learning).
A language model is trained on a collection of text documents, called a corpus. To illustrate how they work, let’s look at a small example corpus.
is the umich the best? my friend said ucsd is the best, is the umich better?
Think of predicting the next word in a sequence of words as implementing randomized, intelligent autocomplete, using patterns from data. For instance, if we start with the phrase “is the”, a language model trained on this corpus might predict “umich” or “best” as the next word, since both “is the umich” and “is the best” appear in the corpus. It probably wouldn’t predict “friend” as the next word, as “is the friend” doesn’t appear in the corpus.
“is the umich” appears twice as often as “is the best”. Language models estimate probabilities, so a language model trained on this specific corpus would learn:
In order for language models to produce natural-sounding text, researchers have found that they need to use some randomness in how they generate outputs. So, instead of always autocompleting “is the” with the most likely word (i.e., “umich”), they sample from a distribution of words, weighted by the probabilities learned above. So, of the time, the model will autocomplete “is the” with “umich”, and of the time, it will autocomplete “is the” with “best”. Then, it’ll continue to predict the next word in the sequence, using the last few words as context. This explanation is a bit simplistic, but captures the gist of how language models work at a high level.
A large language model (LLM) is a language model that is trained on a large (massive!) dataset of text. The recently released GPT-5, and its predecessors, GPT-4 and GPT-3.5, are all LLMs created by OpenAI; ChatGPT is a chatbot that uses GPT for autocompletion, with some additional logic to make the interactions seem more natural. Claude, Gemini, and Grok are also LLMs, created by Anthropic, Google, and X (formerly Twitter), respectively.
The corpuses for these LLMs are trillions of words long, containing books, most publicly available websites, and more; since they were trained on such massive datasets, they are able to answer questions about a broad range of topics. With the above explanation in mind, it’s not hard to see why LLMs sometimes output realistic-sounding text that is not actually true – they randomly generate sequences of words that are statistically likely to appear in their corpuses, but not necessarily true.
All three of the branches of machine learning – supervised learning, unsupervised learning, and reinforcement learning – play a role in training LLMs.
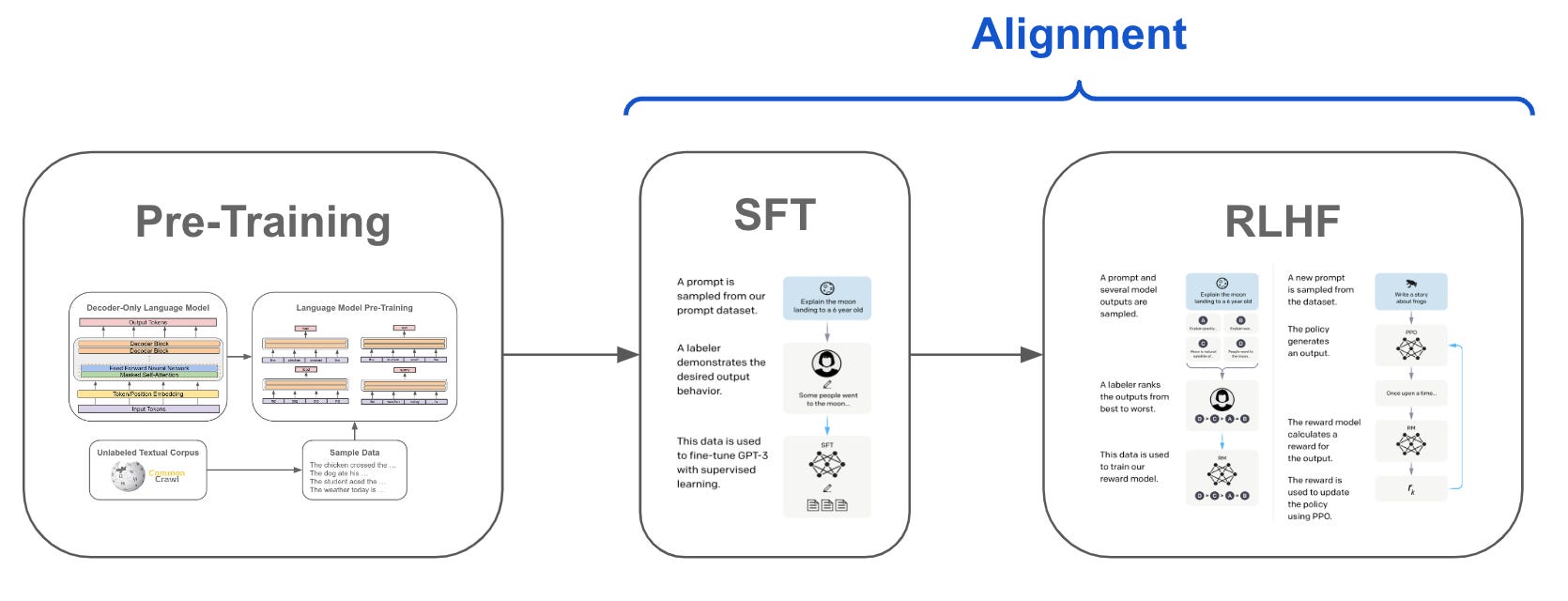
The three stages of LLM training (image source; more reading from OpenAI).
First, an LLM is taught how to predict the next word in a sequence of words, by estimating probabilities like . In this task, there are no labels – the “labels” come from the corpus of text itself. So, this first stage – called pre-training – is somewhere in between supervised learning (because it’s predicting) and unsupervised learning (because there are no labels), and is often thought of as self-supervised learning.
Then, more supervised learning – specifically, supervised fine-tuning (SFT) – is used to train the LLM to get better at answering questions for any one particular task, using a dataset of questions and ideal answers created by humans.
Finally, to ensure the LLM gives answers that humans find useful, it is repeatedly asked a question, and humans vote on their favorite answers. These human preferences are used to create a reward function that the LLM can use to improve its answers using reinforcement learning (sometimes called reinforcement learning with human feedback (RLHF)).
Neural networks – and more specifically, the transformer architecture – are the computational backbone that makes all these steps possible. Transformers, first introduced in 2017 by researchers at Google in a now-famous paper, are excellent at extracting meaning from text data out-of-order. For instance, in the sentence “The bank was steep,” a transformer can distinguish that “bank” refers to a riverbank rather than a financial institution by considering the context provided by “steep”, even though the word “bank” appears before “steep” in the sentence. For a detailed technical introduction to how transformers work, see the transformers course by Hugging Face.
Training state-of-the-art LLMs is a resource-intensive process – some insiders estimate that training OpenAI’s new GPT-5 cost a few billion dollars and several months. You and I (probably) don’t have billions of dollars, but we do have a few months together, and in that time, we will learn about the mathematical underpinnings that make this all possible.