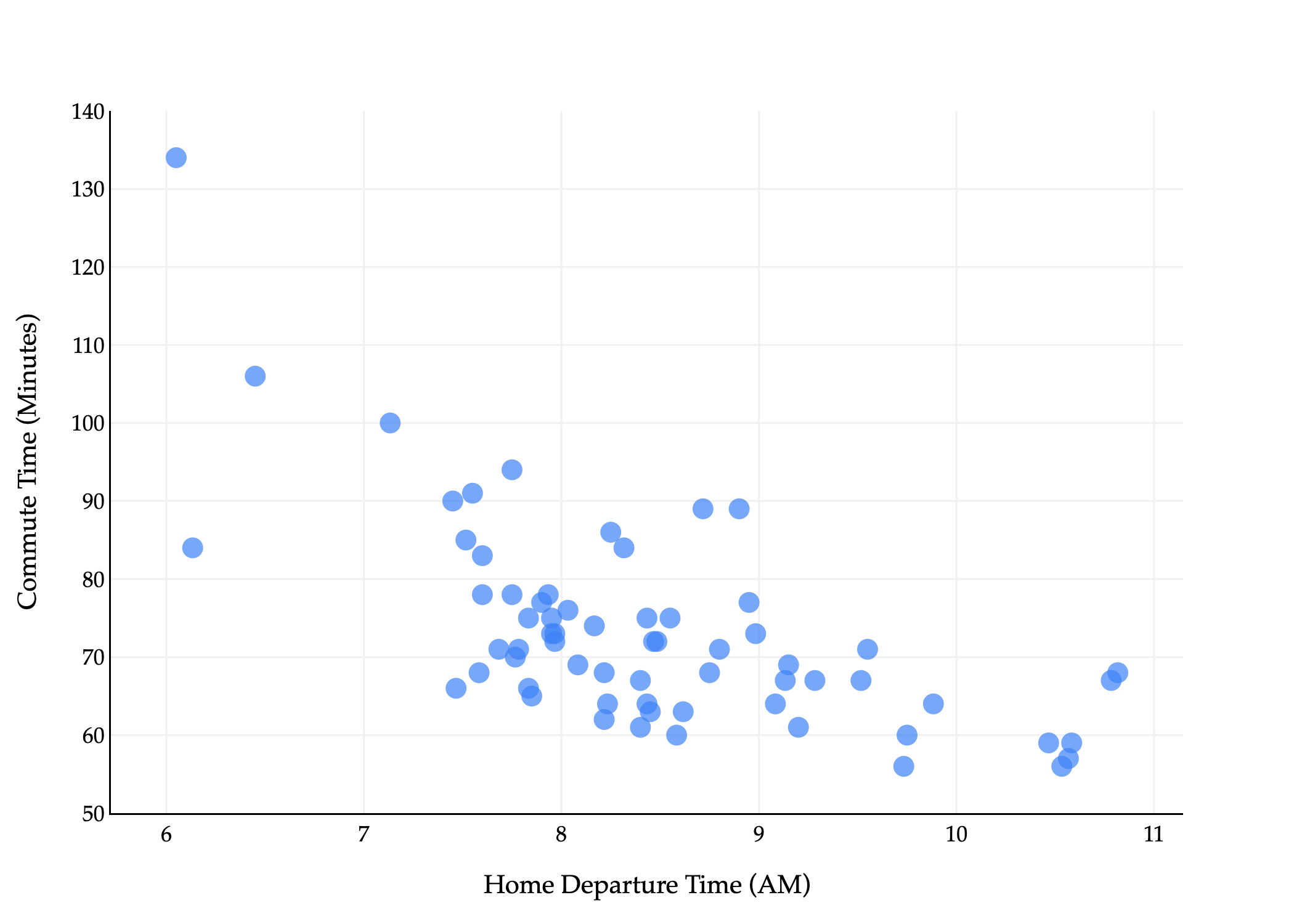
Suppose that you’re looking for an off campus apartment for next year. Unfortunately, none of them are in your price range, so you decide to live with your parents in Detroit and commute. To see if you can save some time on the road each day, you keep track of how long it takes for you to get to school.
This is a real dataset, collected by Joseph Hearn, except he lived in Seattle, not Metro Detroit. The full dataset contains more columns than are shown above, but we’ll focus on these few for now.
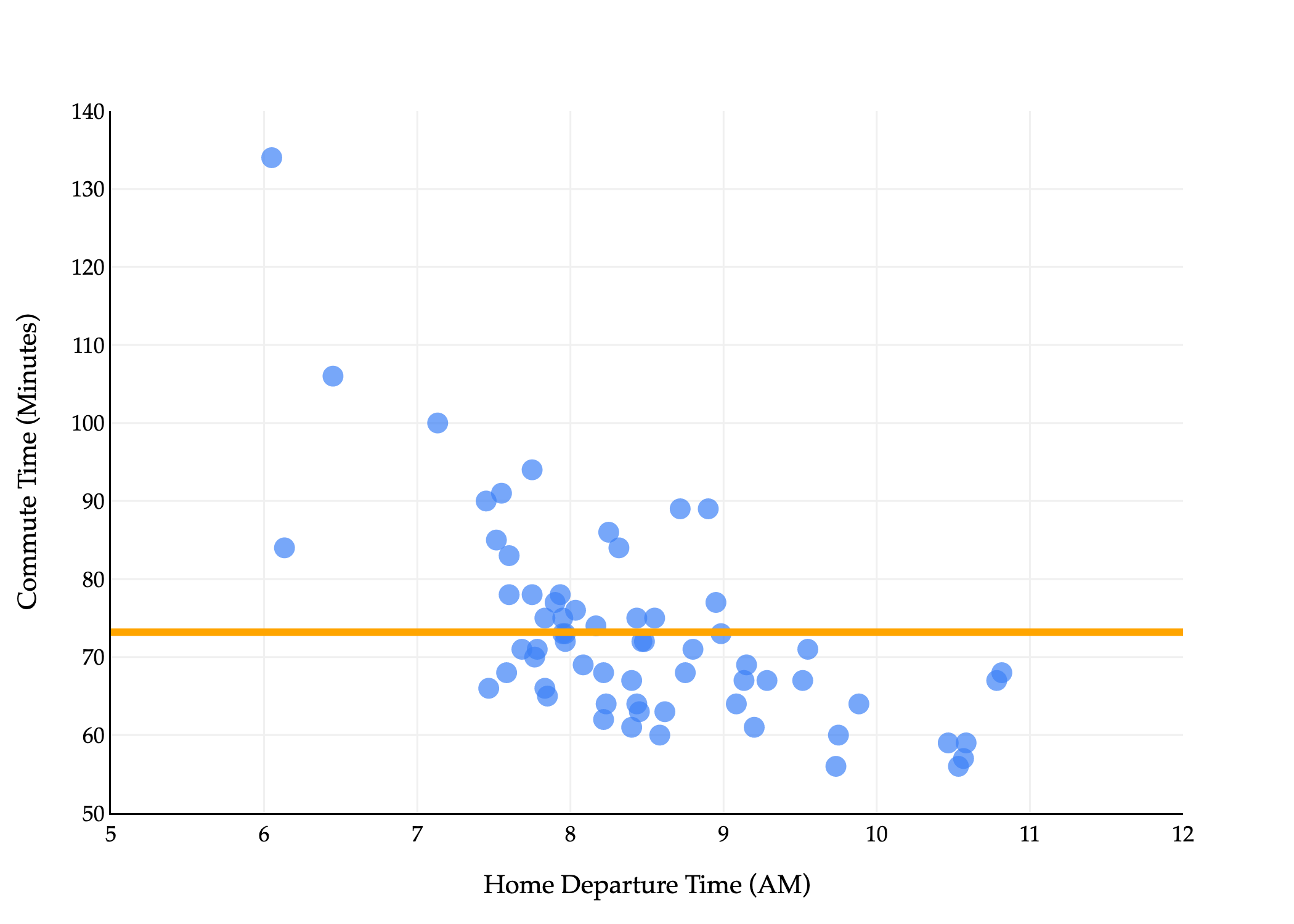
Our goal is to predict commute times, stored in the minutes column. This is our y variable. The natural first input variable, or feature, to consider, is departure_hour. This is our x variable.
We’ll use the subscript i to index the ith data point, for i=1,2,…,n. Using the dataset above, x1=10.816667 and y1=68, for instance.
Departure hours are stored as decimals, but correspond to times of the day. For example, 7.75 corresponds to 7:45 AM, and 10.816667 corresponds to 10:49 AM.
There’s a general downward trend: the later the departure time, the lower the commute time tends to be.
Again, our goal is to predict commute time given departure hour. That is, we’d like to build a useful function h such that:
predicted commute timei=h(departure houri)
This is a regression problem, because the variable we are predicting – commute time – is quantitative.
To build this function, the approach we’ll take is the machine learning approach – that is, to learn a pattern from the dataset that we’ve collected. (This is not the only approach one could take – we could build the function h however we want.)
However, in order to learn a pattern from the dataset that we’ve collected, we need to make an important assumption.
We don’t really need our function h to make good predictions on the dataset that we’ve already collected. We know the actual commute times on day 1, day 2, ..., day n. In other words, we’re working with a labeled dataset, in which we’re given the values of y1,y2,…,yn.
What we do need is for our function h to make good predictions on unseen data from the future, i.e. for future commutes, the ones we don’t know about yet. This is the only way our function h will be practically useful.
But, if the future doesn’t resemble the past, the patterns we learn from the past will not be generalizable to the future. For example, if a new highway between Detroit and Ann Arbor gets built, the patterns previously learned won’t necessarily still exist. This idea of generalizability is key, so keep it in mind even if we’re not explicitly talking about it.
I’ve used the word “model” loosely, but let’s give it a formal definition.
“All models are wrong, but some are useful.” - George Box
My interpretation of George Box’s famous quote is that no matter how complex a model is, it will never be 100% correct, so sometimes – especially when we’re starting our machine learning journey – it’s better to use a simpler model that is also wrong but interpretable.
We gain value from simple models all the time. In a physics class, you may have learned that acceleration due to gravity is 9.81 m/s2 towards the center of the Earth. This is not fully accurate – think about how parachutes work, for example – but it’s still a useful approximation, and one that is relatively easy to understand. A related idea is Occam’s razor, which states that the simplest explanation of a phenomenon is often the best.
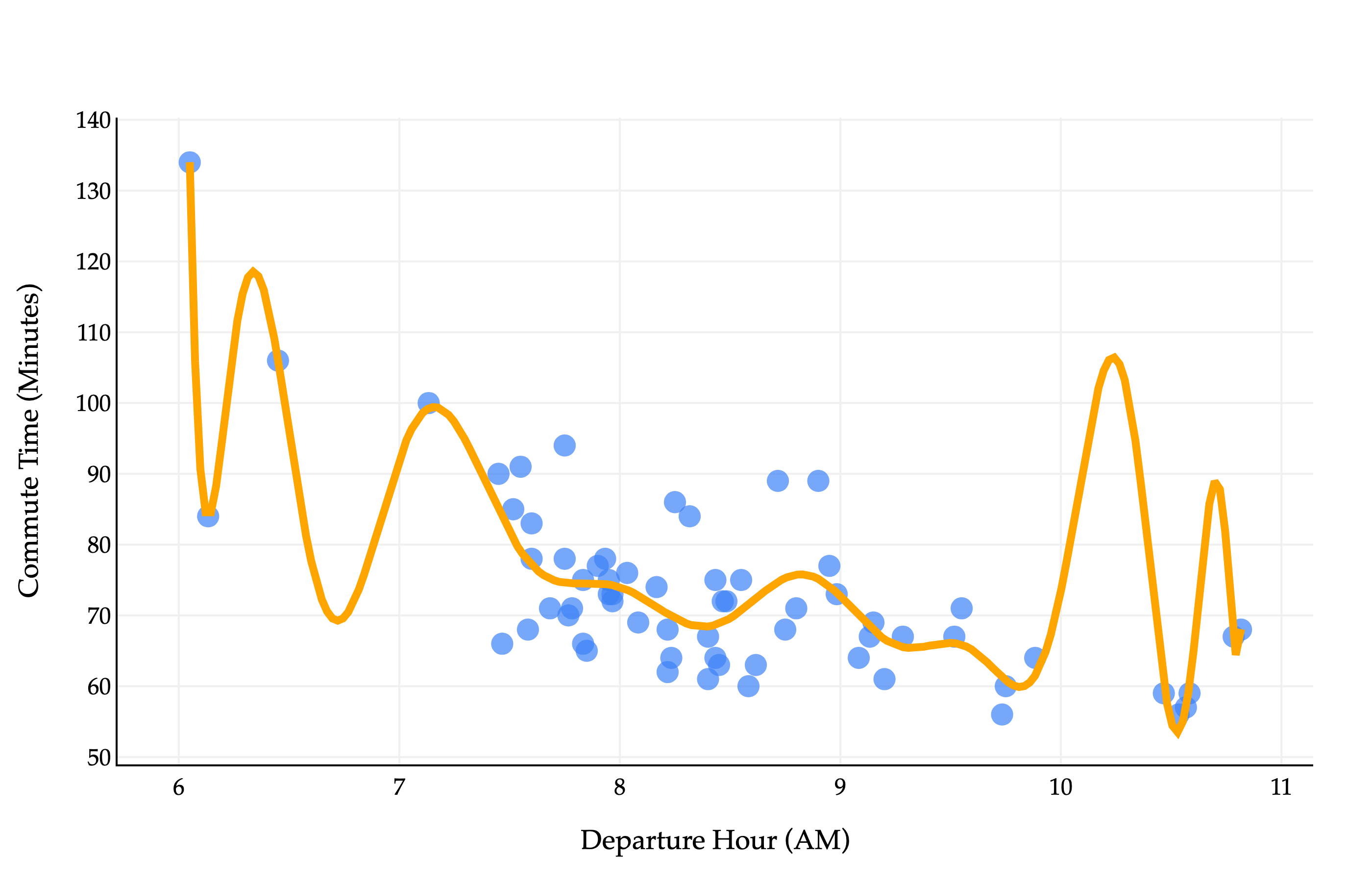
Above, you’ll see a degree-40 polynomial fit to our dataset. We’ll learn how to build such polynomials throughout the semester.
At first glance, it looks to be quite accurate, albeit complex. In fact, it’s a little too complex, and the phenomenon we see above is called overfitting. For xi’s in the dataset that we collected, sure, the polynomial will make accurate predictions, but for any xi’s that don’t match the exact pattern in the dataset, the predictions will be off. (For example, it’s unlikely that commutes will take 110 minutes around 10:15AM, but that’s what the model predicts.) This polynomial model wouldn’t generalize well to unseen data.
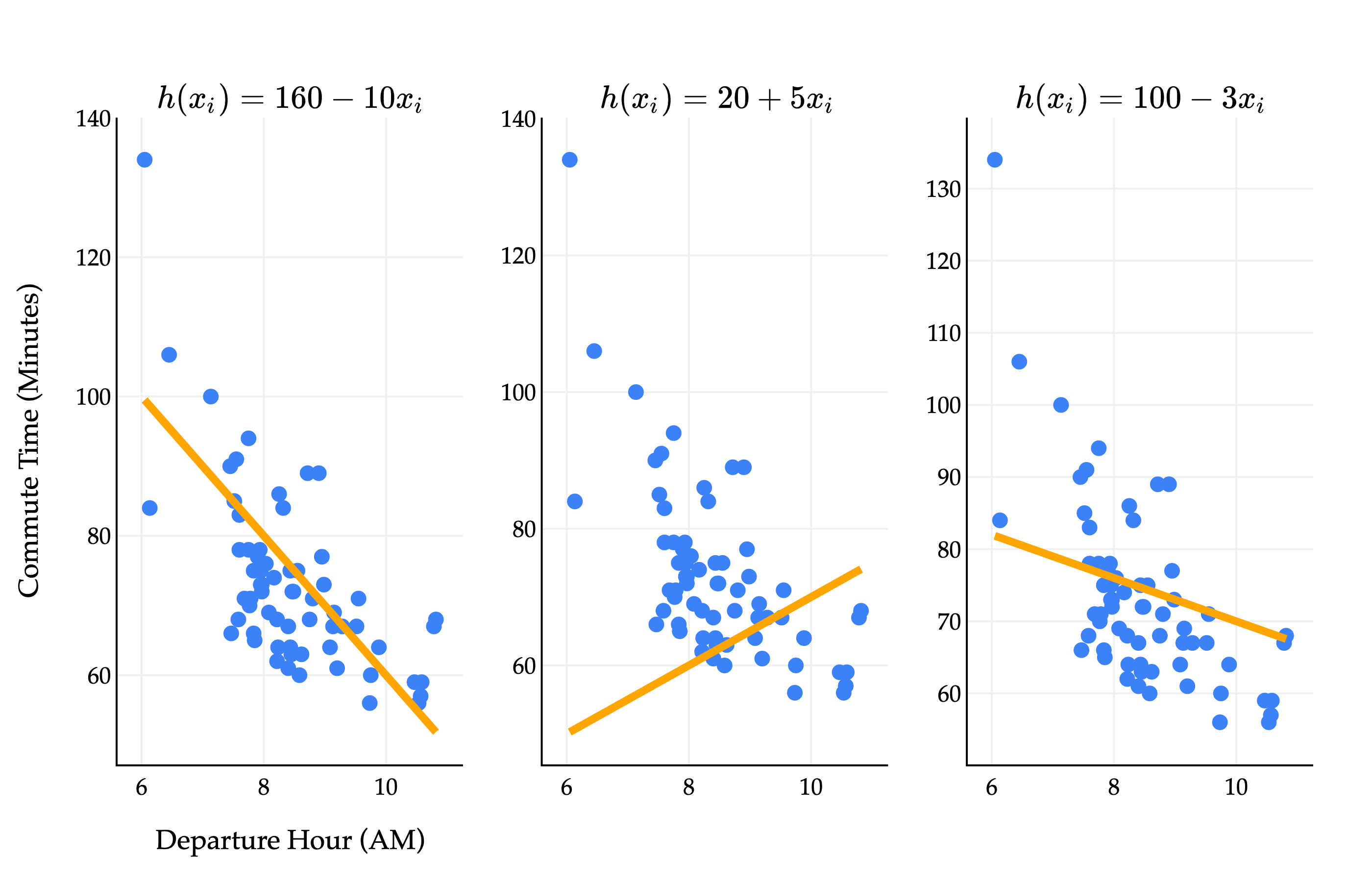
If we look at the scatter plot closely, it seems reasonable to start with a line of best fit, much like you may have seen in a statistics class. In fact, we’ll start with something even more simple than that. But first, some notation.
The hypothesis functions we’ll study have parameters, usually denoted by w, which describe the relationship between the input and output. The two hypothesis functions we’ll study are:
Constant model: h(xi)=w
Simple linear regression model: h(xi)=w0+w1xi
We’ll study the constant model first, but it’s easier to understand the role of parameters in the simple linear regression model.
h(xi)=w0+w1xi represents the equation of a line, where w0 is the intercept and w1 is the slope. Above, we see that different choices of parameters w0 and w1 result in different lines. The million dollar question is: among all of the infinitely many choices of w0 and w1, which one is the best?
To fully answer that, we’ll have to wait until Chapter 1.4. Surprisingly, that answer involves multivariable calculus.
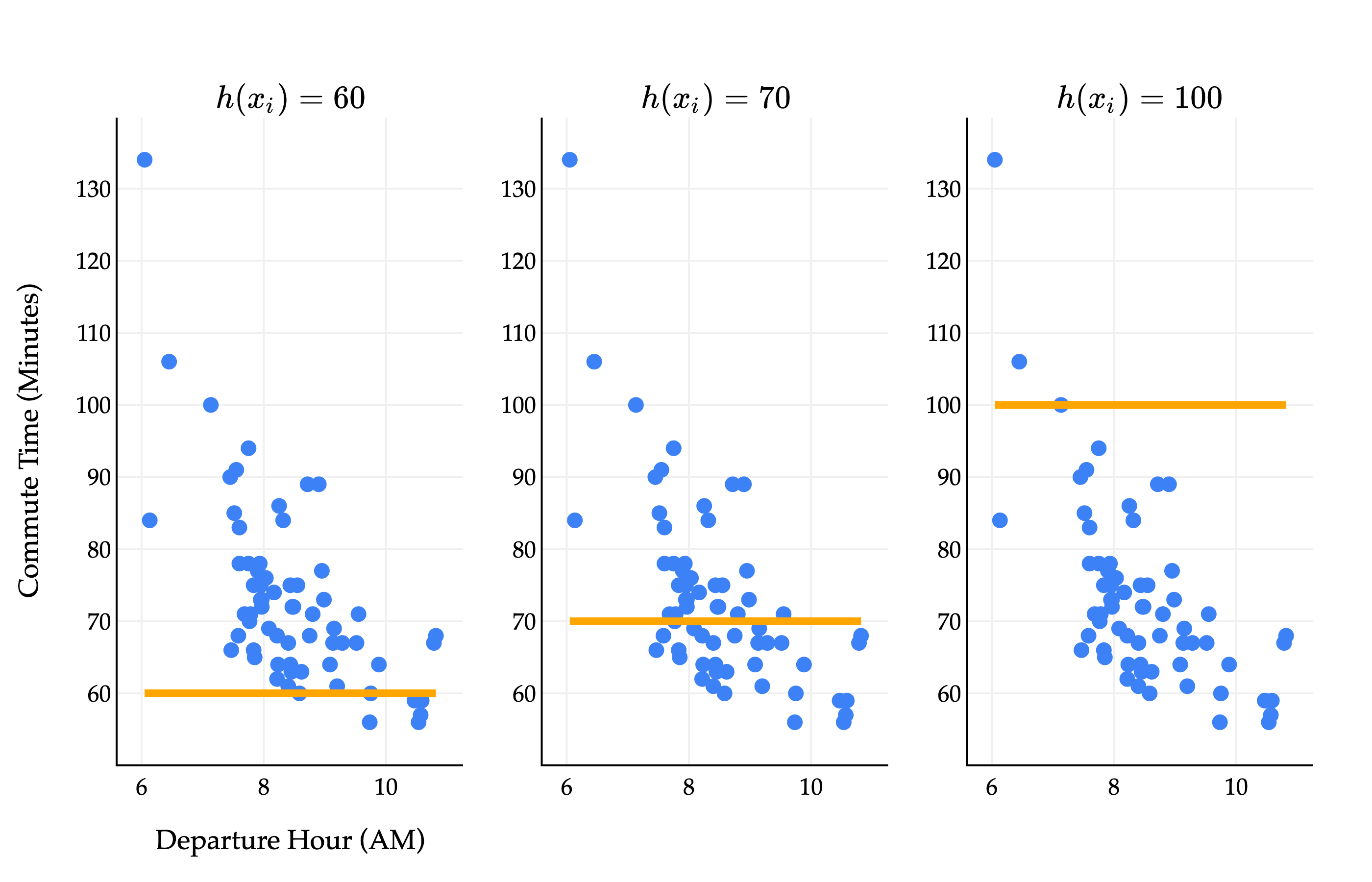
For now, let’s return to the constant model, h(xi)=w. The constant model predicts the same value for all xi’s, and looks like a flat line.
We’ll use the constant model for the rest of this section to illustrate core ideas in machine learning, and will move to more sophisticated models in Chapter 1.4.
If we’re forced to use a constant model, it’s clear that some choices of w (the height of the line) are better than others. w=100 yields a flat line that is far from most of the data. w=60 and w=70 seem like much more reasonable predictions, but how we can quantify which one is better, and which w would be the best?
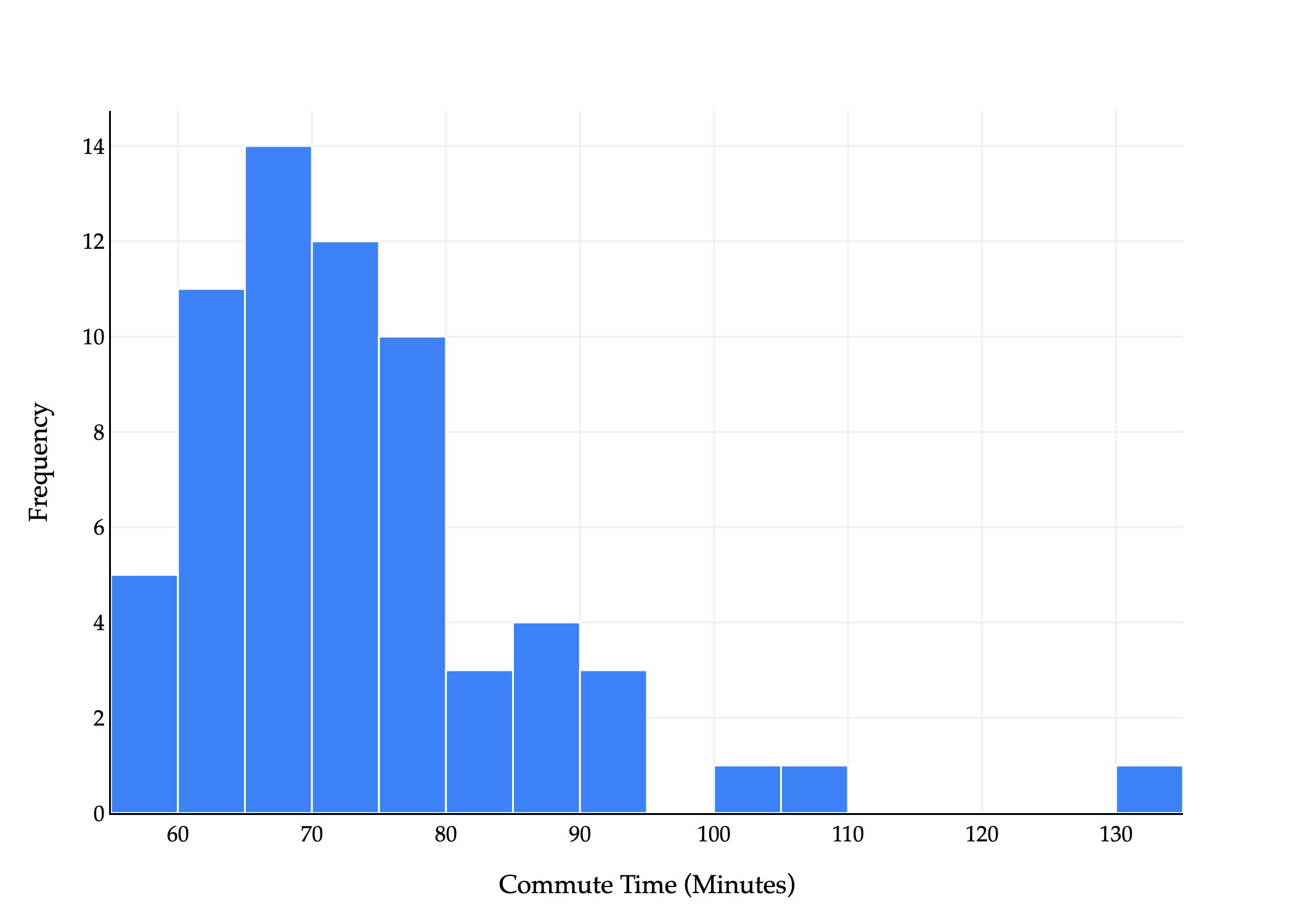
Since the constant model doesn’t depend on departure hours xi, we can instead draw a histogram of just the true commute times.
An equivalent way of phrasing the problem is, which constant w best summarizes the histogram above? Most commute times seem to be in the 60 to 80 range, so somewhere there makes sense. How can we be more precise?
To illustrate, let’s consider a small dataset of only 5 commute times.
y1=72,y2=90,y3=61,y4=85,y5=92
If asked to find the constant that best summarizes these 5 numbers, you might think of the mean or median, which are common summary statistics. There are other valid choices too, like the mode, or halfway between the minimum and maximum, or the most recent. What we need is a way to compare these choices.
A loss function quantifies how bad a prediction is for a single data point.
If our prediction is close ✅ to the actual value, we should have low loss.
If our prediction is far ❌ from the actual value, we should have high loss.
We’ll start by computing the error for a single data point, defined as the difference between an actual y-value and its corresponding predicted y-value.
ei=yi−h(xi)
where yi is the actual value and h(xi) is the predicted value.
Could this be a loss function? Let’s think this through. Suppose we have the true commute time yi=80.
If I predict 75, ei=80−75=5.
If I predict 72, ei=80−72=8.
If I predict 100, ei=80−100=−20.
A lower error is better, so 75 (error of 5) is a better prediction than 72 (error of 8). 100 seems to be the worst of the three predictions, but technically has the smallest error (-20). The issue is that some errors are positive and some are negative, and so it’s hard to compare them directly.
So ideally, a loss function shouldn’t have negative outputs. How can we take these errors, in which some are positive and some are negative, and enforce that they’re all positive?
The most common solution to the problem of negative errors is to square each error. This gives rise to the first loss function we’ll explore, and arguably the most common loss function in machine learning: squared loss.
The squared loss function, Lsq, computes (actual−predicted)2. That is:
Lsq(yi,h(xi))=(yi−h(xi))2
Why did we square instead of take the absolute value? Absolute loss is a perfectly valid loss function – in fact, we’ll study it in Chapter 1.3 – and different loss functions have different pros and cons. That said, squared loss is a good first choice because:
The resulting optimization problem is differentiable, as we’ll see in just a few moments.
It has a nice relationship to the normal distribution in statistics, as we’ll see in Chapter 6, at the end of the course.
Let’s return to our small example dataset of 5 commute times.
y1=72,y2=90,y3=61,y4=85,y5=92
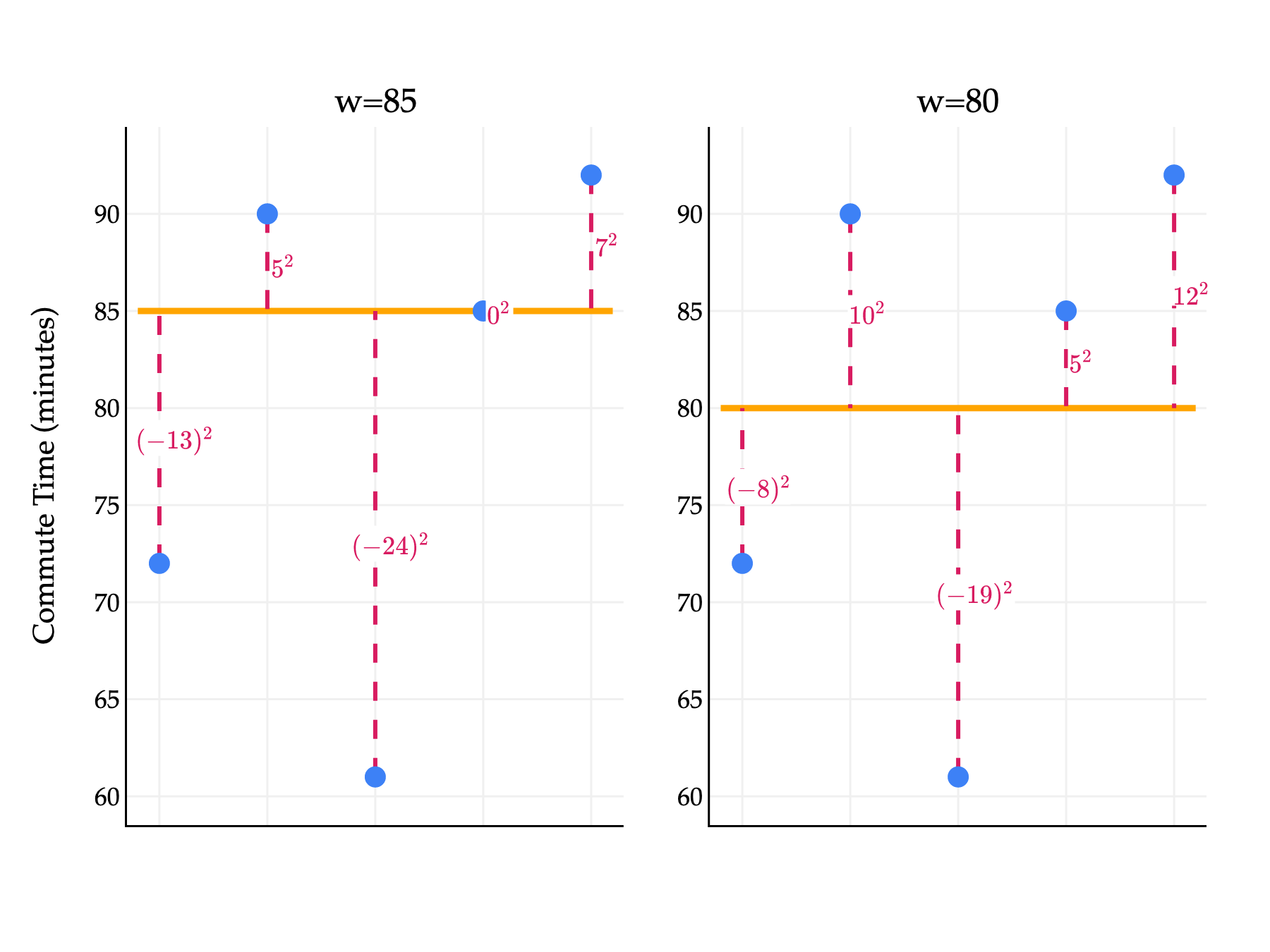
How can we use squared loss to compare two choices of w, say w=85 (the median) and w=80 (the mean)? Let’s draw a picture (in which the x-axis positions of each point are irrelevant, since we’re not using departure hours).
import numpy as np
import plotly.graph_objects as go
from plotly.subplots import make_subplots
y = np.array([72, 90, 61, 85, 92])
preds = [85, 80] # predictions changed to 85 and 80
# create 1 row, 2 columns with reduced horizontal domain for each subplot
fig = make_subplots(
rows=1,
cols=2,
subplot_titles=[f"w={p}" for p in preds],
horizontal_spacing=0.08 # increase spacing between subplots to shrink each horizontally
)
for j, h in enumerate(preds):
losses = y - h # show the loss value, not squared loss
# Horizontal prediction line
fig.add_trace(
go.Scatter(
x=[0.8, 5.2], # shrink x-range to compress horizontally
y=[h, h],
mode="lines",
line=dict(color="orange", width=3),
name=f"$w={h}$",
showlegend=False
),
row=1, col=j+1
)
# Vertical dashed error lines
for i, yi in enumerate(y):
fig.add_trace(
go.Scatter(
x=[i+1, i+1],
y=[yi, h],
mode="lines",
line=dict(color="#D81B60", width=2, dash="dash"),
showlegend=False
),
row=1, col=j+1
)
# Data points
fig.add_trace(
go.Scatter(
x=np.arange(1, 6),
y=y,
mode="markers",
marker=dict(size=10, color="#3D81F6"),
name=r"$y_i$",
showlegend=False
),
row=1, col=j+1
)
# Annotations for losses (show as loss, no arrow, place nearby)
for i, (yi, loss) in enumerate(zip(y, losses)):
fig.add_annotation(
x=i+1 + 0.15, # slight offset to the right
y=(yi + h) / 2,
text=f"${'(' + str(int(loss)) + ')' if loss < 0 else str(int(loss))}^2$",
showarrow=False,
bgcolor="white",
font=dict(size=12, family="Palatino", color="#D81B60"),
row=1, col=j+1
)
# Shared axis styling
fig.update_xaxes(
range=[0.7, 5.3], # shrink x-axis range for each subplot
showticklabels=False,
showgrid=True,
gridwidth=1,
gridcolor="#f0f0f0",
showline=True,
linecolor="black",
linewidth=1
)
fig.update_yaxes(
showgrid=True,
gridwidth=1,
gridcolor="#f0f0f0",
showline=True,
linecolor="black",
linewidth=1
)
# Layout
fig.update_layout(
showlegend=True,
yaxis_title="Commute Time (minutes)",
plot_bgcolor="white",
paper_bgcolor="white",
width=600,
height=450,
margin=dict(l=60, r=30, t=60, b=60),
font=dict(
family="Palatino Linotype, Palatino, serif",
color="black"
)
)
fig.show(renderer="png", scale=3)
Each output of Lsq, shown in pink, describes the quality of a prediction for a single data point. For example, in the left plot above, the annotated (−13)2 came from an actual value of 72 and a predicted value of 85:
Lsq(72,85)=(72−85)2=(−13)2=169
What we’d like is a single number which describes the quality of our predictions across the whole dataset, almost like a “score” for each choice of w. Then, we can compare scores to choose the best possible w. One way to construct such a score is to take the average of the squared losses.
The function Rsq takes in any prediction w and outputs the mean squared error of that w. We’re searching for the value of w that makes Rsq(w) as small as possible, as that would correspond to the w that makes the best possible predictions, for our humble constant model.
Where did the letter R come from? It stands for risk, as in “empirical risk”. I’ll speak more on this soon. For now, remember that:
L always refers to loss for a single data point.
R always refers to average loss across an entire dataset.
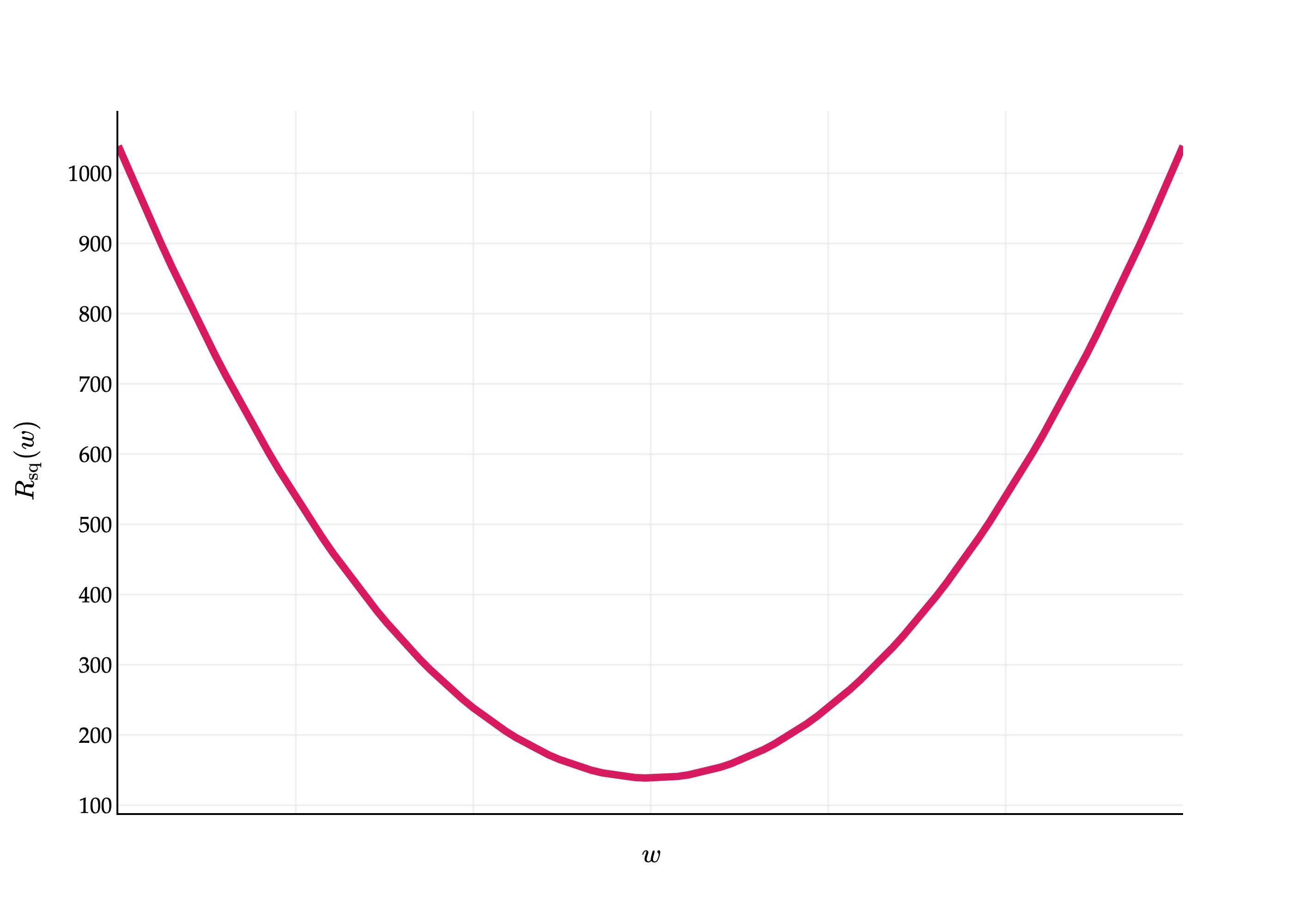
What does Rsq(w) actually look like, if we were to plot it? It is the sum of 5 quadratic functions – namely, 51(72−w)2, 51(90−w)2, and so on – and so it’s a quadratic function too, and looks like a parabola.
import pandas as pd
import numpy as np
import plotly.graph_objects as go
from plotly.subplots import make_subplots
df = pd.read_csv('data/commute-times.csv')
f = lambda h: ((72-h)**2 + (90-h)**2 + (61-h)**2 + (85-h)**2 + (92-h)**2) / 5
x = np.linspace(50, 110, 100)
y = np.array([f(h) for h in x])
fig = go.Figure()
fig.add_trace(
go.Scatter(
x=x,
y=y,
mode='lines',
name='Data',
line=dict(color='#D81B60', width=4)
)
)
fig.update_xaxes(
showticklabels=False,
showgrid=True,
gridwidth=1,
gridcolor='#f0f0f0',
showline=True,
linecolor="black",
linewidth=1,
)
fig.update_yaxes(
showgrid=True,
gridwidth=1,
gridcolor='#f0f0f0',
showline=True,
linecolor="black",
linewidth=1,
)
fig.update_layout(
xaxis_title=r'$w$',
yaxis_title=r'$R_\text{sq}(w)$',
plot_bgcolor='white',
paper_bgcolor='white',
margin=dict(l=60, r=60, t=60, b=60),
font=dict(
family="Palatino Linotype, Palatino, serif",
color="black"
)
)
fig.show(renderer='png', scale=4)
The question is, though, what is the w-value of the vertex of this parabola? That is, which w minimizes Rsq(w)?
Before we find the answer, let’s cast our problem in more general terms, so that the answer is applicable to any dataset. Suppose we have a dataset of n actual commute times, y1,y2,…,yn. Our goal is to find the w that minimizes:
While it looks like there are many variables in this equation, we know the actual values in the dataset, so we can treat y1,y2,…,yn as constants. The only true variable is w.
How do we minimize Rsq(w)? There are a few approaches. We’ll use a calculus-based approach here, though in Homework 1 you’ll look at an alternative approach. For a refresher on the relevant calculus ideas, see Chapter 0.2.
Rsq(w) is a function of a single variable, w. To minimize a function of a single variable, we should:
Take the derivative of Rsq(w) with respect to w.
Set the derivative equal to 0 and solve for w.
Verify that the second derivative at the critical point is positive.
Let’s go through these steps one by one.
Step 1: Take the derivative of Rsq(w) with respect to w
Finally, we’ll pull the constant of -2 out of the sum.
dwdRsq(w)=−n2i=1∑n(yi−w)
We could simplify this further, but this form will do just fine. Don’t forget, though, that the expression on the right side is a function of w.
Step 2: Set the derivative equal to 0 and solve for w
−n2i=1∑n(yi−w)=0
First, we’ll multiply both sides by −2n to get rid of the fraction.
i=1∑n(yi−w)=0
Separating the sum into two parts gives us:
i=1∑nyi−i=1∑nw=0
i=1∑nyi can’t be broken down much further. But, i=1∑nw is the sum of n copies of w, i.e. w+w+…+w. This is just nw!
i=1∑nyi−nw=0
Adding nw to both sides, then dividing both sides by n, gives us:
w∗=n1i=1∑nyi
The value of w that minimizes Rsq(w) is w∗=n1∑i=1nyi. Notice that I’ve called it w∗; think of “star” as meaning “best” or “optimal”.
The formula for w∗ should look very familar. It’s the mean of y1,y2,…,yn!
Step 3: Verify that the second derivative at the critical point is positive
We already know that Rsq(w) is a parabola, which means that its only critical point is a global minimum. But, we’ll be thorough just to set a good example.
Here, we’ll need to find the second derivative of Rsq(w) with respect to w.
The second derivative is 2 for all values of w, including at the w∗ we found. This tells us that Rsq(w) is concave opening upwards across its entire domain, so the critical point we’ve found corresponds to a global minimum.
What was the point of all of that algebra? To recap:
We decided to use the constant model, h(xi)=w, to make predictions.
To find the best value of w – a model parameter • we decided to minimize mean squared error:
Rsq(w)=n1i=1∑n(yi−w)2
Using calculus, we found that the value of w that minimizes Rsq(w) is
w∗=n1i=1∑nyi=Mean(y1,y2,…,yn)
In other words, the mean minimizes mean squared error. This is a remarkable result. We use the mean all of the time in daily life, and now we’ve proven that it is optimal in some sense. It is the constant with the smallest mean squared error, no matter the dataset we’re working with.
Another name for w∗ is an optimal model parameter. In the context of our full commute times dataset, the optimal model parameter is the mean commute time. Visually, the value of w∗≈73 tells us the optimal “height” at which we should draw the constant model, h(xi)=w.
Is this the best possible model? No, of course not – we’re not capturing the fact that later departure times are associated with shorter commute times. But as a first attempt at building a model, the constant model is valuable. If someone asked you how long your commutes are, saying something like “about 73 minutes” is reasonable.
What’s next?
In Chapter 1.3, we’ll investigate other loss functions, like absolute loss.
In Chapter 1.4, we’ll reintroduce the simple linear regression model, h(xi)=w0+w1xi, and see how to find the best values of w0 and w1.