In Chapters 2.4 through 2.6, we focused on understanding the subspace of Rnspanned by a set of vectors. I’ve been alluding to the fact that to solve the regression problem in higher dimensions, we’d need to be able to project a vector onto the span of a set of vectors. (To be clear, we haven’t done this yet.) Matrices will allow us to achieve this goal elegantly. It will take a few sections to get there:
In Chapter 2.7, we’ll define matrices, and learn to perform basic operations on them.
In Chapter 2.8, we’ll define the column space, row space, null space, and rank of a matrix, while introducing the CR decomposition along the way.
In Chapter 2.9, we’ll understand matrix-vector multiplication as a transformation of the vector, and learn how to invert a matrix and compute its determinant.
In Chapter 2.10, we’ll learn to project a vector onto the span of the columns of a matrix, closing the loop with Chapter 2.3.
Just remember that all of this is for machine learning.
For now, let’s consider the following three vectors in R4:
v1=⎣⎡3202⎦⎤,v2=⎣⎡11−1−2⎦⎤,v3=⎣⎡4900⎦⎤
If we stack these vectors horizontally, we produce a matrix:
⎣⎡∣v1∣∣v2∣∣v3∣⎦⎤=⎣⎡320211−1−24900⎦⎤
A is a matrix with 4 rows and 3 columns, so we might say that A is a 4×3 matrix, or that A∈R4×3.
It’s common to use the notation Aij to denote the entry in the i-th row and j-th column of A, e.g. A23=9.
In numpy, you can access the entry in the 2nd row and 3rd column of the 2D matrix A using A[1, 2], once we account for the fact that numpy uses 0-based indexing.
Activity 1
In the cell above, try and find the bottom-right entry of A, first using positive indexing and then using negative indexing.
I’ve introduced matrices in a very particular way, because I’d like for you to think of them as a collection of vectors, sometimes called column vectors. We’ll come back to this in just a moment. You can also think of a matrix as a collection of row vectors; the example A defined above consists of four row vectors in R3 stacked horizontally.
When we introduced vectors, n was typically the placeholder we’d use for the number of components of a vector. With matrices, I like using n for the number of rows, and d for the number of columns. This means that, in general, a matrix is of shape n×d and is a member of the set Rn×d. This makes clear that when we’ve collected data, we store each of our n observations in a row of our matrix. Just be aware that using n×d to denote the shape of a matrix is a little unorthodox; most other textbooks will use m×n to denote the shape of a matrix. Of course, this is all arbitrary.
As we’ll see in the coming sections, square matrices are the most flexible – there are several properties and operations that are only defined for them. Unfortunately, not every matrix is square. Remember, matrices are used for storing data, and the number of observations, n and number of features, d, don’t need to be the same. (In practice, we’ll often have very tall matrices, i.e. n≫d, but this is not always the case.)
Great – we know how to add two matrices, and how to multiply a matrix by a scalar. The natural next step is to figure out how – and why – to multiply two matrices together.
First, a definition.
Let’s use the Golden Rule. First – as the title of this subsection suggests – we’ll start by computing the product of a matrix and a vector.
Let’s suppose A is the same 4×3 matrix we’ve become familiar with:
A=⎣⎡320211−1−24900⎦⎤
And let’s suppose x is some vector. Note that we can think of an n-dimensional vector as a matrix with n rows and 1 column. In order for the product Ax to be valid, x must have 3 elements in it, by the Golden Rule above. To make the example concrete, let’s suppose:
x=⎣⎡103⎦⎤
How do we multiply Ax? The following key definition will help us.
Let me say a little more about the dimensions of the output. Below, I’ve written the dimensions of A (4×3) and x (3×1) next to each other. By the Golden Rule, the inner dimensions, both of which are bolded, must be equal in order for the multiplication to be valid. The dimensions of the output will be the result of looking at the outer dimensions, which here are 4×1.
4×3A3×1x=4×1output
So, the result of multiplying Ax will be 4×1 matrix, or in other words, a vector in R4. Indeed, the result of multiply a matrix by a vector always results in another vector, and this act of multiplying a matrix by a vector is often thought of as transforming the vector from Rd to Rn.
So, how do we find those 4 components? As mentioned earlier, we compute each component by taking the dot product of a row in A with x.
A=⎣⎡320211−1−24900⎦⎤,x=⎣⎡103⎦⎤
Let’s start with the top row ofA, ⎣⎡314⎦⎤. The dot product of two vectors is only defined if they have equal lengths. This is why we’ve instituted the Golden Rule! The Golden Rule tells us we can only multiply A and x if the number of columns in A is the same as the number of components in x, which is true here (both of those numbers are 3).
Then, the dot product of the first row of A with x is:
⎣⎡314⎦⎤⋅⎣⎡103⎦⎤=3⋅1+1⋅0+4⋅3=15
Nice! We’re a quarter of the way there. Now, we just need to compute the remaining three dot products:
The dot product of the second row of A with x is ⎣⎡219⎦⎤⋅⎣⎡103⎦⎤=29.
The dot product of the third row of A with x is ⎣⎡0−10⎦⎤⋅⎣⎡103⎦⎤=0.
And finally, the dot product of the fourth row of A with x is ⎣⎡2−20⎦⎤⋅⎣⎡103⎦⎤=2.
The result of our matrix-vector multiplication, then, is the result of stacking all 4 dot products together into the vector ⎣⎡152902⎦⎤. To summarize:
Above, you’ll notice that x and the third row vector, ⎣⎡0−10⎦⎤, are orthogonal (rotate the plot so that you can see this), so the third component in
Ax=⎣⎡152902⎦⎤
is 0.
Activity 2
We’ll try not to bore you with mundane calculations in the future, but it’s important to perform matrix-vector multiplication by hand a few times to understand how it works.
In each part, perform the matrix-vector multiplication by hand or state that it cannot be done.
(While we haven’t yet looked at how to compute the product of two matrices, you can still answer this just using what you know about matrix-vector multiplication.)
In the cell below, use numpy to verify your answers. You’ll need to define the matrices and vectors as numpy arrays, and use the @ operator to perform the matrix-vector multiplication.
We’ve described matrix-vector multiplication as the result of taking the dot product of each row of A with x, and indeed this is the easiest way to actually compute the output. But, there’s another more important interpretation. In the above dot products, you may have noticed:
Entries in the first column of A (3, 2, 0, and 2) were always multiplied by the first element of x (1).
Entries in the second column of A (1, 1, -1, and -2) were always multiplied by the second element of x (0).
Entries in the third column of A (4, 9, 0, and 0) were always multiplied by the third element of x (3).
In other words:
Ax=⎣⎡320211−1−24900⎦⎤⎣⎡103⎦⎤=linear combination of columns of A1⎣⎡3202⎦⎤+0⎣⎡11−1−2⎦⎤+3⎣⎡4900⎦⎤=⎣⎡152902⎦⎤
At the start of this section, we defined A by stacking the vectors v1, v2, and v3 side-by-side, and I told you to think of a matrix as a collection of column vectors. The above result is precisely why – it’s because when we multiply A by x, we’re computing a linear combination of the columns of A, where the weights are the components of x!
Since Ax produces a linear combination of the columns of A, a natural question to ask at this point is whether the columns of A are all linearly independent. A only has 3 columns, each of which is in R4, so while they may or may not be linearly independent (are they?), we know they cannot span all of R4, as we’d need at least 4 vectors to reach every element in R4.
This is the type of thinking we’ll return to in Chapter 2.8. This will lead us to define the rank of a matrix, perhaps the single most important number associated with a matrix.
Activity 3
Consider the matrix M defined below.
M=[21−153−20140]
In each of the following parts, write out u concretely, compute Mu, and explain the result in English.
A vector whose second component is 1, and whose other components are 0.
A vector containing all 1s.
A vector containing all 51s.
A vector whose components sum to 1, whose first component is 53, and whose other components are all equal to one another.
Matrix-matrix multiplication – or just “matrix multiplication” – is a generalization of matrix-vector multiplication. Let’s present matrix multiplication in its most general terms.
Note that if p=1, this reduces to the matrix-vector multiplication case from before. In that case, the only possible value of j is 1, since the output only has 1 column, and the element in row i of the output vector is the dot product of row i in A and the vector B (which we earlier referred to as x in the less general case).
For a concrete example, suppose A and B are defined below:
A=⎣⎡320211−1−24900⎦⎤B=⎣⎡103272⎦⎤
The number of columns of A must equal the number of rows of B in order for the product AB to be defined, as the Golden Rule tells us. That is fortunately the case here. Since A has shape 4×3 and B has shape 3×2, the output matrix will have shape 4×2. Each of those 4⋅2=8 elements will be the dot product of a row in A with a column in B.
Let’s see if we can audit where these numbers came from. Let’s consider (AB)32, which is the element in row 3 and column 2 of the output. It should have come from the dot product of row 3 of A and column 2 of B.
And indeed, -7 is the dot product of ⎣⎡0−10⎦⎤ and ⎣⎡272⎦⎤.
You should notice that many of the numbers in the output AB look familiar. That’s because we used the same A as we did earlier in the section, and the first column of B is just x from the matrix-vector example. So, the first column in AB is the same as the vector Ax=⎣⎡152902⎦⎤ as we computed earlier. The difference now is that the output AB isn’t just a single vector, but is a matrix with 2 columns. The second column, ⎣⎡2129−7−10⎦⎤, comes from multiplying A by the second column in B, ⎣⎡272⎦⎤.
Note that as we add columns to B, we’d add columns to the output. If B had 10 columns, then AB would have 10 columns, too, without A needing to change. As long as the Golden Rule – that the number of columns in A equals the number of rows in B – holds, the product AB can be computed, and it has shape (number of rows in A)×(number of columns in B).
The first two properties – associativity and distributivity – match standard arithmetic properties that we’ve become accustomed to. The associative property allows you to, for example, compute ABx only by using matrix-vector multiplications, since you can first multiply Bx, which results in a vector, and then multiply A by that vector. (I had you do this in Activity 2 earlier in this section – I hope you did it! 🧐)
The fact that matrix multiplication is not commutative may come as a surprise, as every other form of multiplication you’ve learned about up until this point has been commutative (including the dot product).
In fact, if AB exists, BA may or may not! If A is n×d and B is d×p, then BA only exists if n=p. But even then, AB=BA in general.
For example, if A is 2×3 and B is 3×2, then AB is 2×2 and BA is 3×3; here, both products exist, but they cannot be equal since they have different shapes.
Even if A and B are both square matrices with the same shape, AB=BA in general. For illustration, consider:
A=[1324],B=[5768]
Then,
AB=[19432250]=BA=[23313446]
Activity 4
Activity 4.1
Let P=⎣⎡010001100⎦⎤, S=⎣⎡4000210003⎦⎤, and x=⎣⎡4612⎦⎤.
Evaluate Px and Sx. Then, explain in words what multiplying P and S by x does to x.
Evaluate PSx and SPx. The results should be different, as we’d expect, since matrix multiplication is not commutative in general. Explain the difference intuitively, given the “operations” P and S perform on x.
P is called a permutation matrix, and S is called a diagonal matrix.
Activity 4.2
The famous Fibonacci sequence of integers, F0,F1,F2,…, is defined as follows:
F0=0,F1=1,Fn=Fn−1+Fn−2 for n≥2
The first few terms in the sequence are 0,1,1,2,3,5,8,13,21,34,55,89,144,….
It turns out you can compute the nth term in the sequence using matrix multiplication.
Find a 2×2 matrix A such that A[Fn−1Fn−2]=[FnFn−1]. The answer uses relatively small numbers.
Compute A[10], i.e. the product of A and the vector [10].
Since A is square, we can multiply it by itself. Compute A2[10] and A3[10].
If you continue this process, you’ll find that An[10] is a vector containing the nth and (n−1)th terms in the Fibonacci sequence!
Activity 4.3
Using the same matrices P and S from Activity 4.1, compute (P−S)x and Px−Sx. Are both the results the same? If so, what property of matrix multiplication guarantees this?
Is the result of (P−S)x interpretable, in the same way that the results of Px and Sx were in Activity 4.1?
I’ve shown you the naïve – and by far most common – algorithm for matrix multiplication. If A and B are both square n×n matrices, then the runtime of the naïve algorithm is O(n3).
However, there exist more efficient algorithms for matrix multiplication. Strassen’s algorithm is one such example; it describes how to multiply two square n×n matrices in O(n2.807) time. The study of efficient algorithms for matrix multiplication is an active area of research; if you’re interested in learning more, look here.
Matrix multiplication, I might argue, is one of the reasons NVIDIA is the most valuable company in the world. Modern machine learning is built on matrix multiplication, and GPUs are optimized for it. Why? This comment from Reddit does a good job of explaining:
Imagine you have 1 million math assignments to do, they are very simple assignments, but there are a lot that need to be done, they are not dependent on each other so they can be done on any order.
You have two options, distribute them to 10 thousand people to do it in parallel or give them to 10 math experts. The experts are very fast, but hey, there are only 10 of them, the 10 thousand are more suitable for the task because they have the “brute force” for this.
GPUs have thousands of cores, CPUs have tens.
On that note, the @ operator in numpy is used for matrix multiplication; it is a shorthand for np.matmul. You can also use it to multiply a matrix by a vector.
To illustrate, let’s start with our familiar matrix A:
A=⎣⎡320211−1−24900⎦⎤
The transpose of A is:
AT=⎣⎡3142190−102−20⎦⎤
Note that A∈R4×3 and AT∈R3×4.
Why would we ever need to do this? To illustrate, suppose u=⎣⎡u1u2u3u4⎦⎤, and that we’d like to compute the product ATu. (Note that u must be in R4 in order for ATu to be defined, unlike x∈R3 in the product Ax). Then:
This is a linear combination of the rows of A, where the weights are the components of u. Remember, the standard product Ax is a linear combination of the columns of A, so the transpose helps us if we want to compute a linear combination of the rows of A. (Equivalently, it helps us if we want to compute the dot product of the columns of A with u – see the “Two Pictures” note from earlier in this chapter.)
The transpose also gives us another way of expressing the dot product of two vectors. If u and v are two vectors in Rn, then uT is a row vector with 1 row and n columns. Multiplying uT by v results in a 1×1 matrix, which is just the scalar u⋅v.
The benefit of using the transpose to express the dot product is that it allows us to write the dot product of two vectors in terms of matrix multiplication, rather than being an entirely different type of operation. (In fact, as we’ve seen here, matrix multiplication is just a generalization of the dot product.)
There are other uses for the transpose, too, so it’s a useful tool to have in your toolbox.
The first three properties are relatively straightforward. The last property is a bit more subtle. Try and reason as to why it’s true on your own, then peek into the box below to verify your reasoning and to see an example.
Why is (AB)T=BTAT?
Let’s start with just (AB)T and reason our way from there. Define C=(AB)T. C is presumably the product of two matrices X and Y, we just don’t know what X and Y are. By the definition of matrix multiplication, we know that Cij is the dot product of the ith row of X and the jth column of Y. How can we express the product C=XY in terms of A and B?
Let’s work backwards. Since Cij=(AB)ijT=(AB)ji by the definition of the transpose, we know that:
Cij=(AB)ji=(row j of A)⋅(column i of B)=(column i of B)⋅(row j of A)
This is a little backwards relative to the definition of matrix multiplication, which says that:
Cij=(XY)ij=(row i of X)⋅(column j of Y)
In order for the two definitions of Cij to be consistent, we must have:
(column i of B)⋅(row j of A)=(row i of X)⋅(column j of Y)
Row i of X is the same as column i of B, if X=BT.
Column j of Y is the same as row j of A, if Y=AT.
Putting this together, we have:
C=(AB)T=BTAT
as we hoped!
To make things concrete, let’s consider two new matrices A and B:
BTAT is the transpose of AB. Both AB and BTAT have 12 elements, both computed using the same 12 dot products.
The fact that (AB)T=BTAT comes in handy when finding the norm of a matrix-vector product. If A is an n×d matrix and x∈Rd, then:
∥Ax∥2=(Ax)T(Ax)=xTATAx
As we’ll soon see, some matrices A have special properties that make this computation particularly easy.
In numpy, the T attribute is used to compute the transpose of a 2D array.
Activity 6
Activity 6.1
In the cell above:
Define x to be an array corresponding to the vector x=⎣⎡103⎦⎤.
Find the norm of the product Ax using np.linalg.norm.
Find the norm of the product Ax using the fact that ∥Ax∥2=xTATAx, and verify that you get the same answer.
Activity 6.2
Suppose M∈Rn×d is a matrix, v∈Rd is a vector, and s∈R is a scalar.
Determine whether each of the following quantities is a matrix, vector, scalar, or undefined. If the result is a matrix or vector, determine its dimensions.
Mv
vM
v2
MTM
MMT
vTMv
(sMv)⋅(sMv)
(svTMT)T
vTMTMv
vvT+MTM
∥v∥Mv+(vTMTMv)Mv
Activity 6.3
Let A=⎣⎡23−1141⎦⎤, B=[120123], and C=⎣⎡101011210−11−1⎦⎤.
Compute AB, then multiply the result by C.
Compute A, then multiply the result by BC. Do you get the same result as above? If so, what property of matrix multiplication guarantees this?
Determine a formula for (ABC)T, and verify that your result works. (Hint: Start with the fact that (AB)T=BTAT.)
Saying “the identity matrix” is a bit ambiguous, as there are infinitely many identity matrices – there’s a 1×1 identity matrix, a 2×2 identity matrix, a 3×3 identity matrix, and so on. Often, the dimension of the identity matrix is implied by context, and if not, we might provide it as a subscript, e.g. In for the n×n identity matrix.
Why is the identity matrix defined this way? It’s the matrix equivalent of the number 1 in scalar multiplication, also known as the multiplicative identity. If c is a scalar, then c⋅1=c and 1⋅c=c. (0 is known as the additive identity in scalar multiplication.)
Similarly, if A is squaren×n matrix and x∈Rn is a vector, then the n×n identity matrix I is the unique matrix that satisfies:
Ix=x for all x∈Rn.
IA=AI=A for all A∈Rn×n.
A good exercise is to verify that the identity matrix satisfies these properties.
Activity 7
Let X=⎣⎡1−1203−230−12⎦⎤.
Compute XTX.
Then, compute the transpose of XTX. What do you notice? (XTX is called a symmetric matrix.)
Compute XTX+21I. We’ll use matrices of the form XTX+λI in Chapter 5.
This section was relatively mechanical, and I didn’t spend much time explaining why we’d multiply two matrices (or a matrix and a vector) together. More context for this operation will come throughout the rest of the chapter.
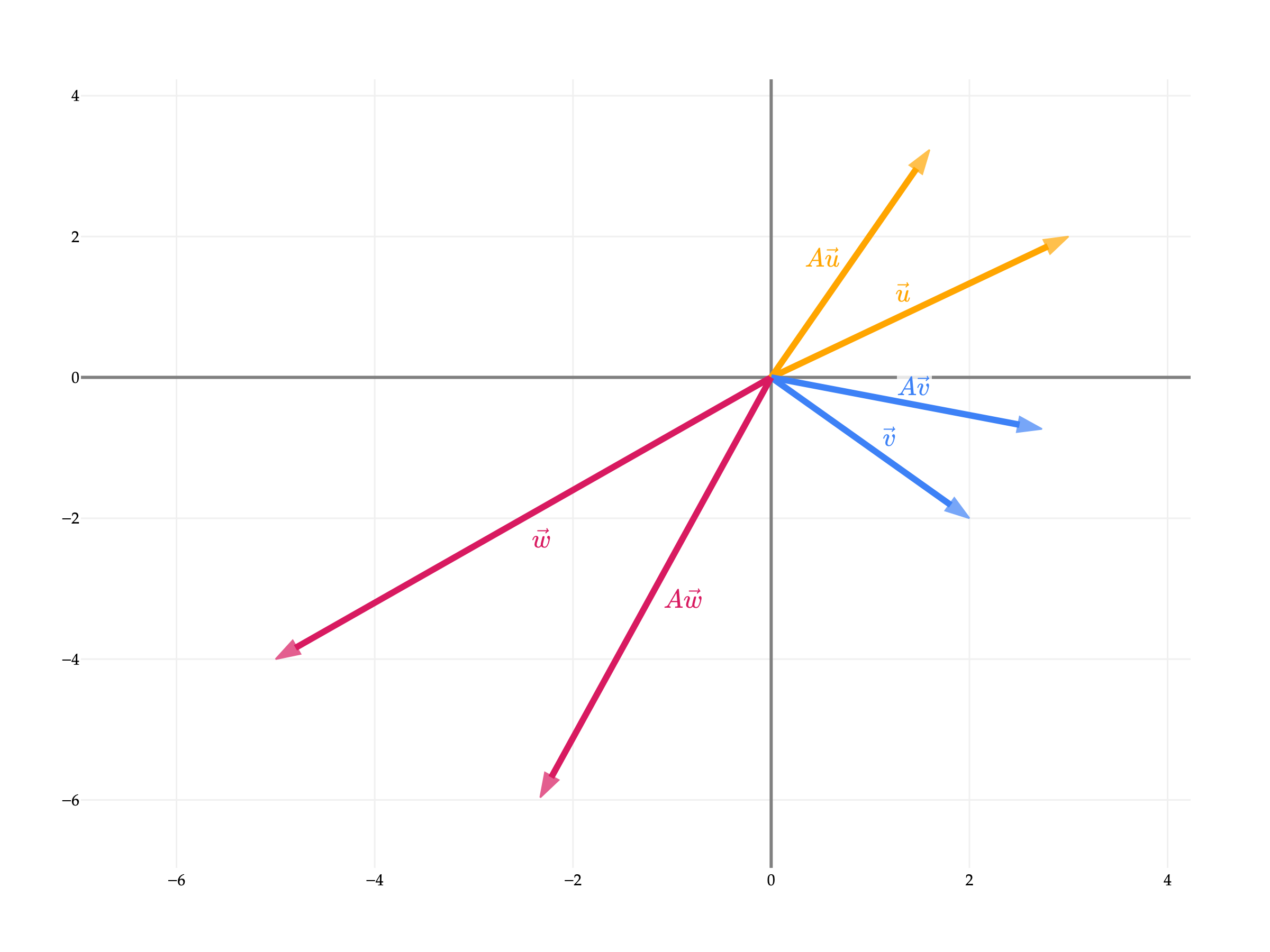
To conclude, I want to show you some of the magic behind matrix multiplication.
Consider the relatively innocent looking 2×2 matrix
A=⎣⎡2321−2123⎦⎤
Below, you’ll see that I’ve drawn out six vectors in R2.
u=[32] and Au
v=[2−2] and Av
w=[−5−4] and Aw
What do you notice about the vectors Au, Av, and Aw? and how they relate to u, v, and w?
from utils import plot_vectors
import numpy as np
A = np.array([[np.cos(np.pi/6), -np.sin(np.pi/6)], [np.sin(np.pi/6), np.cos(np.pi/6)]])
u = np.array([3, 2])
v = np.array([2, -2])
w = np.array([-5, -4])
Au = A @ u
Av = A @ v
Aw = A @ w
fig = plot_vectors([(tuple(u), 'orange', r'$\vec u$'),
(tuple(v), '#3d81f6', r'$\vec v$'),
(tuple(w), '#d81a60', r'$\vec w$'),
(tuple(Au), 'orange', r'$A \vec u$'),
(tuple(Av), '#3d81f6', r'$A \vec v$'),
(tuple(Aw), '#d81a60', r'$A \vec w$')], vdeltay=0.3)
fig.show(scale=3, renderer='png')
A is called a rotation matrix, since it rotates vectors by a certain angle (in this case, 6π radians, or 30∘). Rotations are a type of linear transformation.
Not all matrices are rotation matrices; there exist plenty of different types of linear transformations, like reflections, sheers, and projections (which sound familiar). These will all become familiar in Chapter 2.9. All I wanted to show you for now is that matrix multiplication may look like a bunch of random number crunching, but there’s a lot of meaning baked in.