Linear algebra can be thought of as the study of vectors, matrices, and linear transformations, all of which are ideas we’ll need to use in our journey to understand machine learning. We’ll start with vectors, which are the building blocks of linear algebra.
There are many ways to define vectors, but I’ll give you the most basic and practically relevant definition of a vector for now. I’ll introduce more abstract definitions later if we need them.
By ordered list, I mean that the order of the numbers in the vector matters.
For example, the vector v=⎣⎡4−315⎦⎤ is not the same as the vector w=⎣⎡15−34⎦⎤, even though they have the same components.
v is also different from the vector u=⎣⎡4−3151⎦⎤, even though their first three components are the same.
In general, we’re mostly concerned with vectors in Rn, which is the set of all vectors with ncomponents or elements, each of which is a real number. It’s possible to consider vectors with complex components (the set of all vectors with complex components is denoted Cn), but we’ll stick to real vectors for now.
The vector v defined in the box above is in R3, which we can express as v∈R3. This is pronounced as “v is an element of R three”, or “v is in R three”.
A general vector in Rn can be expressed in terms of its n components:
v=⎣⎡v1v2⋮vn⎦⎤
Subscripts can be used for different, sometimes conflicting purposes:
In the definition of v above, the components of the vector are denoted v1,v2,…,vn. Each of these individual components is a single real number – known as a scalar – not a vector.
But in the near future, we may want to consider multiple vectors at once, and may use subscripts to refer to them as well. For instance, I might have d different vectors, v1,v2,…,vd, each corresponding to some feature I care about.
The meaning of the subscript depends on the context, so just be careful!
While we’ll use the definition of a vector as a list of numbers for now, I hope you’ll soon appreciate that vectors are more than just a list of numbers – they encode remarkable amounts of information and beauty.
In the context of physics, vectors are often described as creatures with “a magnitude and a direction”. While this is not a physics class – this is EECS 245, after all! – this interpretation has some value for us too.
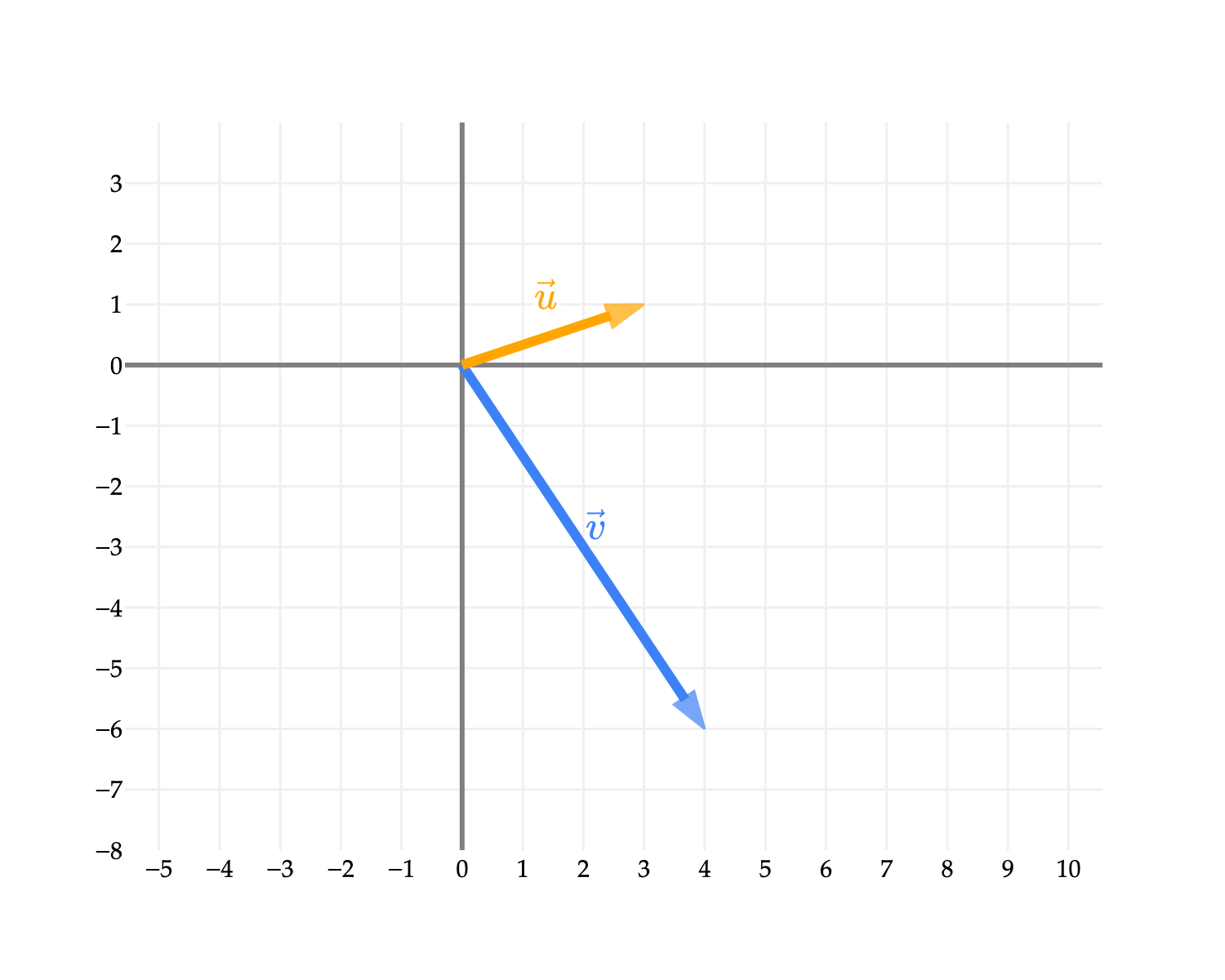
To illustrate what we mean, let’s consider some concrete vectors in R2, since it is easy to visualize vectors in 2 dimensions on a computer screen. Suppose:
u=[31],v=[4−6]
Then, we can visualize u and v as arrows pointing from the origin (0,0) to the points (3,1) and (4,−6) in the two dimensional Cartesian plane, respectively.
# This chunk must be in the first plotting cell of each notebook in order to guarantee that the mathjax script is loaded.
import plotly
from IPython.display import display, HTML
# Set default renderer to high-DPI static image
plotly.io.renderers.default = "png"
display(HTML(
'<script type="text/javascript" async src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.1/MathJax.js?config=TeX-MML-AM_SVG"></script>'
))
# ---
from utils import plot_vectors
import numpy as np
fig = plot_vectors([((4, -6), '#3d81f6', r'$\vec v$'), ((3, 1), 'orange', r'$\vec u$')], vdeltax=0.3, vdeltay=0.8)
fig.update_layout(width=500, height=400, yaxis_scaleanchor="x")
fig.update_xaxes(range=[-1, 6], tickvals=np.arange(-5, 15))
fig.update_yaxes(range=[-8, 4], tickvals=np.arange(-8, 4))
fig.show(scale=3)
Loading...
The vector v=[4−6] moves 4 units to the right and 6 units down, which we know by reading the components of the vector. In Chapter 2.2, we’ll see how to describe the direction of v in terms of the angle it makes with the x-axis (and you may remember how to calculate that angle using trigonometry).
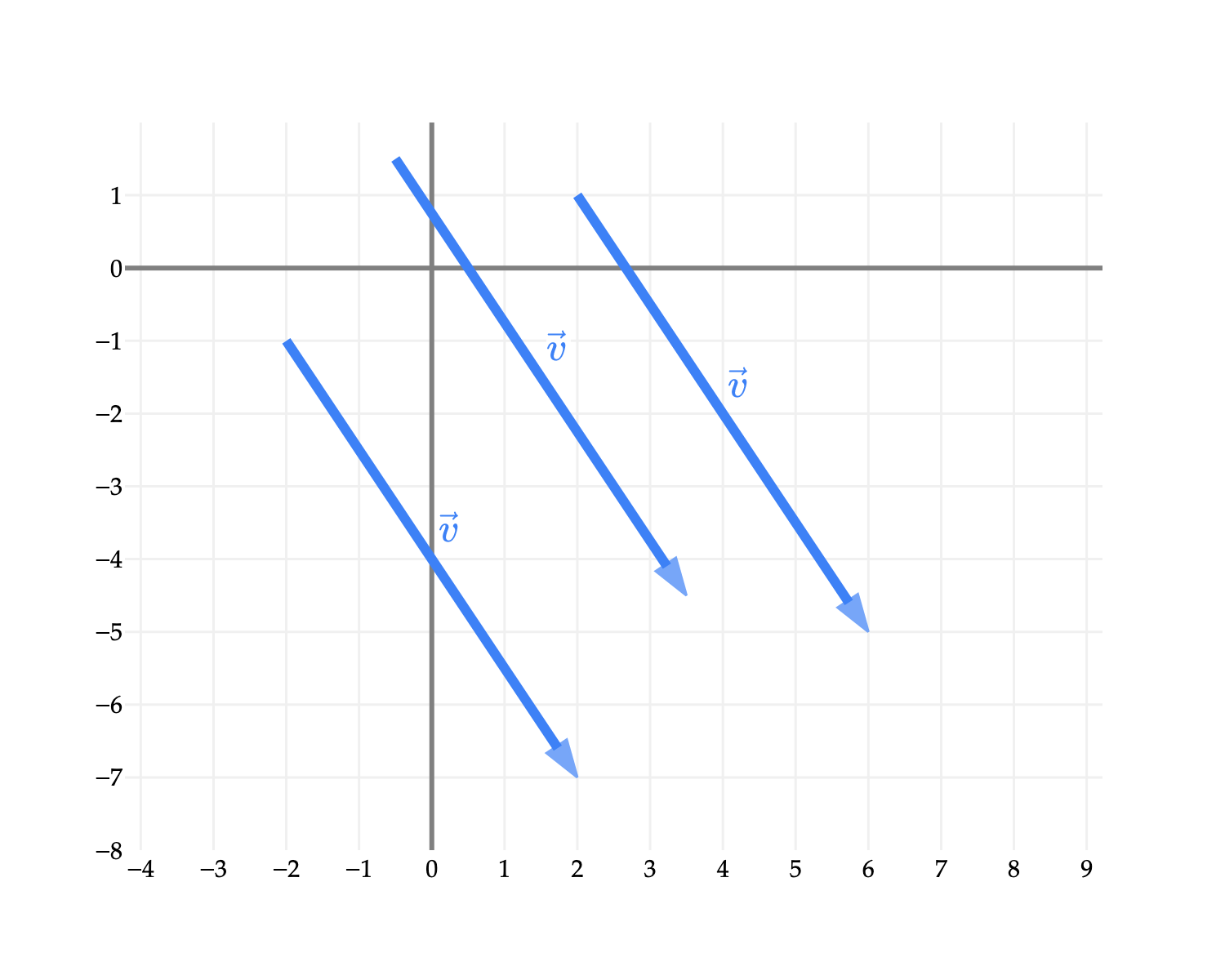
It’s worth noting that v isn’t “fixed” to start at the origin – vectors don’t have fixed positions. All three vectors in the figure below are the same vector, v.
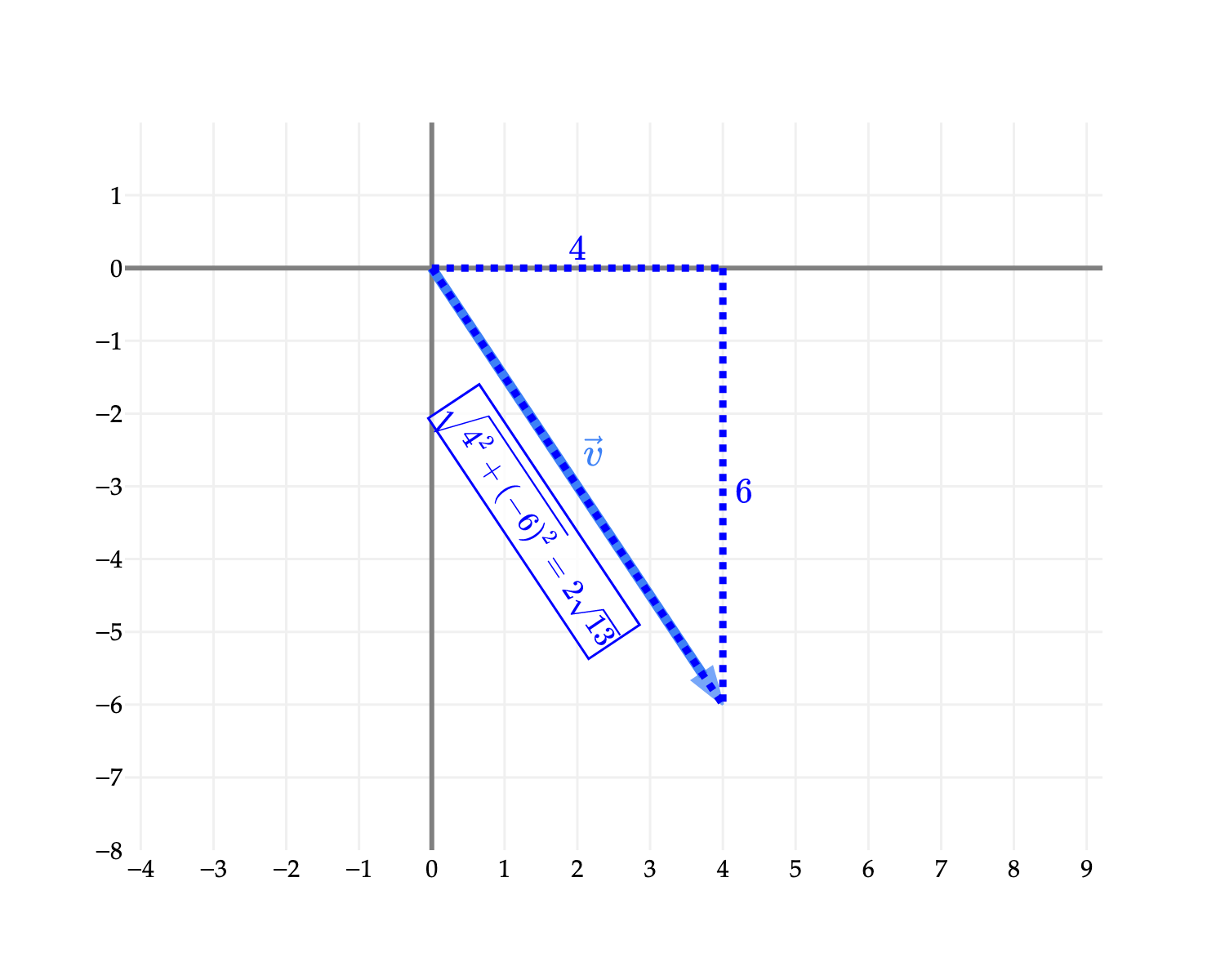
To compute the length of v – i.e. the distance between (0,0) and (4,−6) – we should remember the Pythagorean theorem, which states that if we have a right triangle with legs of length a and b, then the length of the hypotenuse is a2+b2. Here, that’s 42+(−6)2=16+36=52=213.
from utils import plot_vectors
import numpy as np
fig = plot_vectors([((4, -6), '#3d81f6', r'$\vec v$')], vdeltax=0.3, vdeltay=1)
# Add horizontal dotted line from (0,0) to (4,0)
fig.add_shape(
type="line",
x0=0, y0=0, x1=4, y1=0,
line=dict(color="blue", width=3, dash="dot")
)
# Add vertical dotted line from (4,0) to (4,-6)
fig.add_shape(
type="line",
x0=4, y0=0, x1=4, y1=-6,
line=dict(color="blue", width=3, dash="dot")
)
# Add label "4" above the horizontal line
fig.add_annotation(
x=2, y=0.3,
text="$4$",
showarrow=False,
font=dict(size=14, color="blue")
)
# Add label "6" to the right of the vertical line
fig.add_annotation(
x=4.3, y=-3,
text="$6$",
showarrow=False,
font=dict(size=14, color="blue")
)
# Add diagonal dotted line from (0,0) to (4,-6) - the hypotenuse
fig.add_shape(
type="line",
x0=0, y0=0, x1=4, y1=-6,
line=dict(color="blue", width=3, dash="dot")
)
# Add calculation annotation for the hypotenuse
fig.add_annotation(
x=1.4, y=-3.5,
text=r"$$\sqrt{4^2 + (-6)^2} = 2\sqrt{13}$$",
showarrow=False,
font=dict(size=12, color="blue"),
bgcolor="rgba(255,255,255,0.8)",
bordercolor="blue",
borderwidth=1,
textangle=np.arctan(6/4) * 180 / np.pi
)
fig.update_layout(width=500, height=400, yaxis_scaleanchor="x")
fig.update_xaxes(range=[-1, 6], tickvals=np.arange(-5, 15))
fig.update_yaxes(range=[-8, 2], tickvals=np.arange(-8, 2))
fig.show(config={'displayModeBar': False}, scale=3)
Note that the norm involves a sum of squares, much like mean squared error 🤯. This connection will be made more explicit in Chapter 3, when we return to studying linear regression.
Shortly, we’ll see other norms, which describe different ways of measuring the “length” of a vector.
Activity 1
As we’ll see later in this section, a unit vector is a vector with norm 1. It’s common to use unit vectors to describe directions. For instance, there are infinitely many vectors in R2 that point in the same direction as v=[4−6] from above, like [2−3] and [40−60]. (If you don’t believe me, draw it out!)
Find a unit vector that points in the same direction as the vector x=[125], and verify that it has norm 1. Technically, to answer this, you’ll need to use the fact that vectors can be multiplied by a scalar, which we haven’t yet discussed, but see how far your intuition takes you!
What may not be immediately obvious is why the Pythagorean theorem seems to extend to higher dimensions. The two dimensional case seems reasonable, but why is the length of the vector w=⎣⎡6−23⎦⎤ in R3 equal to 62+(−2)2+32?
from utils import plot_vectors
import numpy as np
import plotly.graph_objects as go
fig = plot_vectors([((6, -2, 3), '#d81b60', '<b>w</b>')], vdeltax=-0.6)
# Add light blue triangle connecting (0, 0, 0), (0, -2, 0), and (6, -2, 0)
fig.add_trace(go.Mesh3d(
x=[0, 0, 6],
y=[0, -2, -2],
z=[0, 0, 0],
i=[0],
j=[1],
k=[2],
color='lightblue',
opacity=0.7,
showscale=False,
name='Triangle 1'
))
# Add red triangle connecting (0, 0, 0), (6, -2, 0) and (6, -2, 3)
fig.add_trace(go.Mesh3d(
x=[0, 6, 6],
y=[0, -2, -2],
z=[0, 0, 3],
i=[0],
j=[1],
k=[2],
color='#d81b60',
opacity=0.5,
showscale=False,
name='Triangle 2'
))
# Add dotted blue lines for the edges
edges = [
# Edge "2": (0,0,0) to (0,-2,0)
([0, 0], [0, -2], [0, 0]),
# Edge "6": (0,-2,0) to (6,-2,0)
([0, 6], [-2, -2], [0, 0]),
# Edge "h": (0,0,0) to (6,-2,0)
([0, 6], [0, -2], [0, 0]),
# Edge "3": (6,-2,0) to (6,-2,3)
([6, 6], [-2, -2], [0, 3])
]
for x_coords, y_coords, z_coords in edges:
fig.add_trace(go.Scatter3d(
x=x_coords, y=y_coords, z=z_coords,
mode='lines',
line=dict(color='blue', width=3, dash='dash'),
showlegend=False
))
# Add vertex labels with better positioning
vertices = {
'(0,0,0)': (-0.3, 0.3, 0.2),
'(0,-2,0)': (-0.3, -2.3, 0.2),
'(6,-2,0)': (6.3, -2.3, 0.2),
'(6,-2,3)': (6.3, -2.3, 3.3)
}
for label, (x, y, z) in vertices.items():
fig.add_trace(go.Scatter3d(
x=[x], y=[y], z=[z],
mode='text',
text=[label],
textfont=dict(size=12, color='black', family='Palatino'),
textposition='middle center',
showlegend=False
))
# Add edge labels at adjusted positions to avoid triangular areas
edge_labels = {
'2': (-0.5, -1, 0), # shifted left from midpoint of (0,0,0) to (0,-2,0)
'6': (2.2, -2.2, 0), # shifted up and back from midpoint of (0,0,0) to (6,-2,0)
'3': (6.5, -2.1, 1.5), # shifted right from midpoint of (6,-2,0) to (6,-2,3)
'h': (4, -1, -0) # shifted up and back from midpoint of (0,0,0) to (6,-2,0)
}
for label, (x, y, z) in edge_labels.items():
fig.add_trace(go.Scatter3d(
x=[x], y=[y], z=[z],
mode='text',
text=[label],
textfont=dict(size=14, color='blue', family='Palatino'),
textposition='middle center',
showlegend=False
))
fig.update_layout(
scene=dict(
camera=dict(
eye=dict(x=-1.5, y=0, z=0.5)
)
)
)
fig.show(renderer="notebook")
Loading...
Loading...
There are two right angle triangles in the picture above:
One triangle has legs of length 6 and 2, with a hypotenuse of h; this triangle is shaded light blue above.
Another triangle has legs of length 3 and h, with a hypotenuse of ∥w∥; this triangle is shaded dark pink above.
To find ∥w∥, we can use the Pythagorean theorem twice:
h2=62+(−2)2=36+4=40⟹h=40
Then, we can use the Pythagorean theorem again to find ∥w∥:
∥w∥=h2+32=40+9=7=62+(−2)2+32
So, to find ∥w∥, we used the Pythagorean theorem twice, and ended up computing the square root of the sum of the squares of the components of the vector, which is what the definition above states.
This argument naturally extends to higher dimensions. We will do this often: build intuition in the dimensions we can visualize (two dimensions, and with the help of interactive graphics, three dimensions), and then rely on the power of abstraction to extend our understanding to higher dimensions, even when we can’t visualize. Thinking in higher dimensions is one of the key objectives of this course.
Vector norms satisfy several interesting properties, which we will introduce shortly once we have more context.
Vectors support two core operations: addition and scalar multiplication. These two operations are core to the study of linear algebra – so much so, that sometimes vectors are defined abstractly as “things that can be added and multiplied by scalars”.
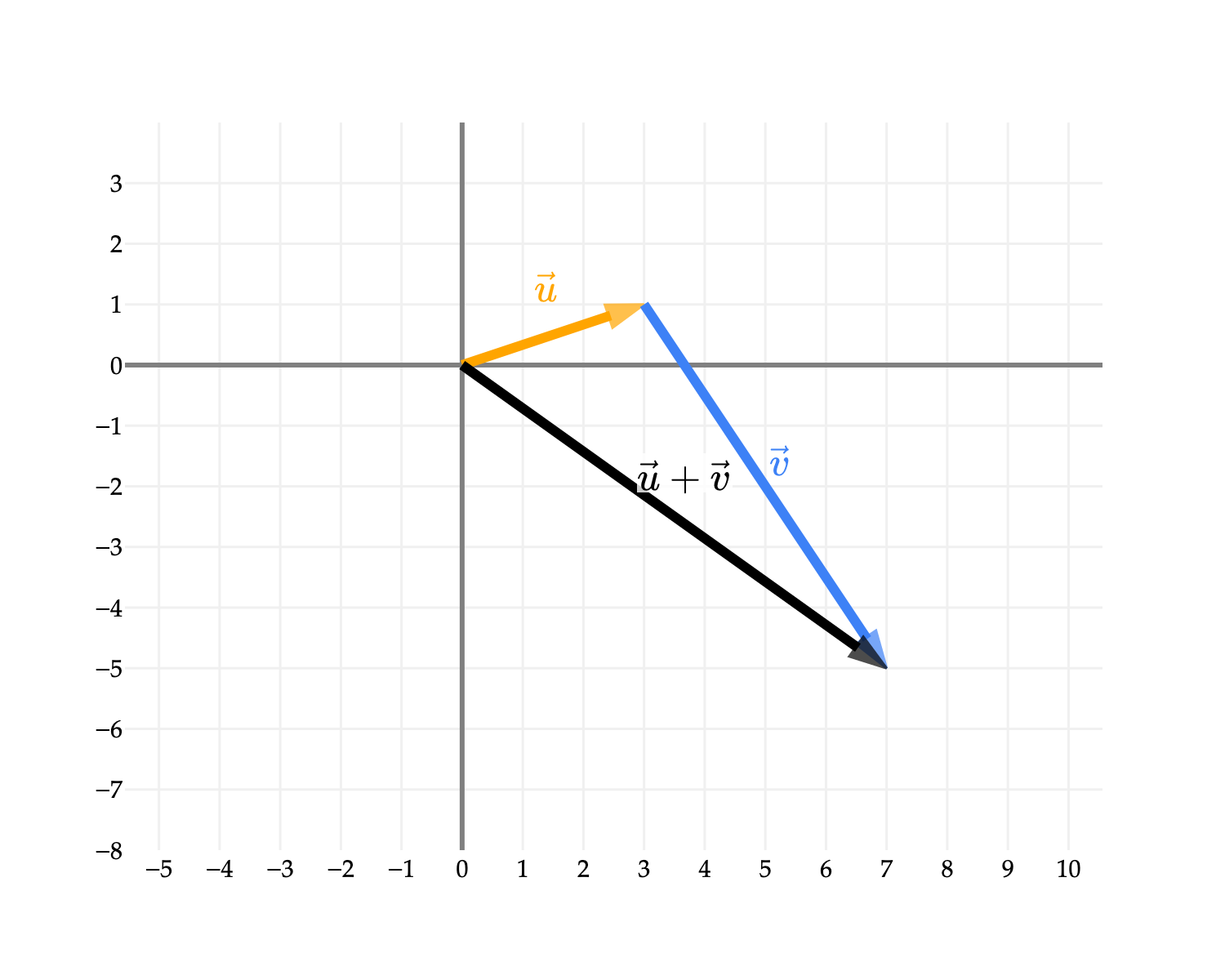
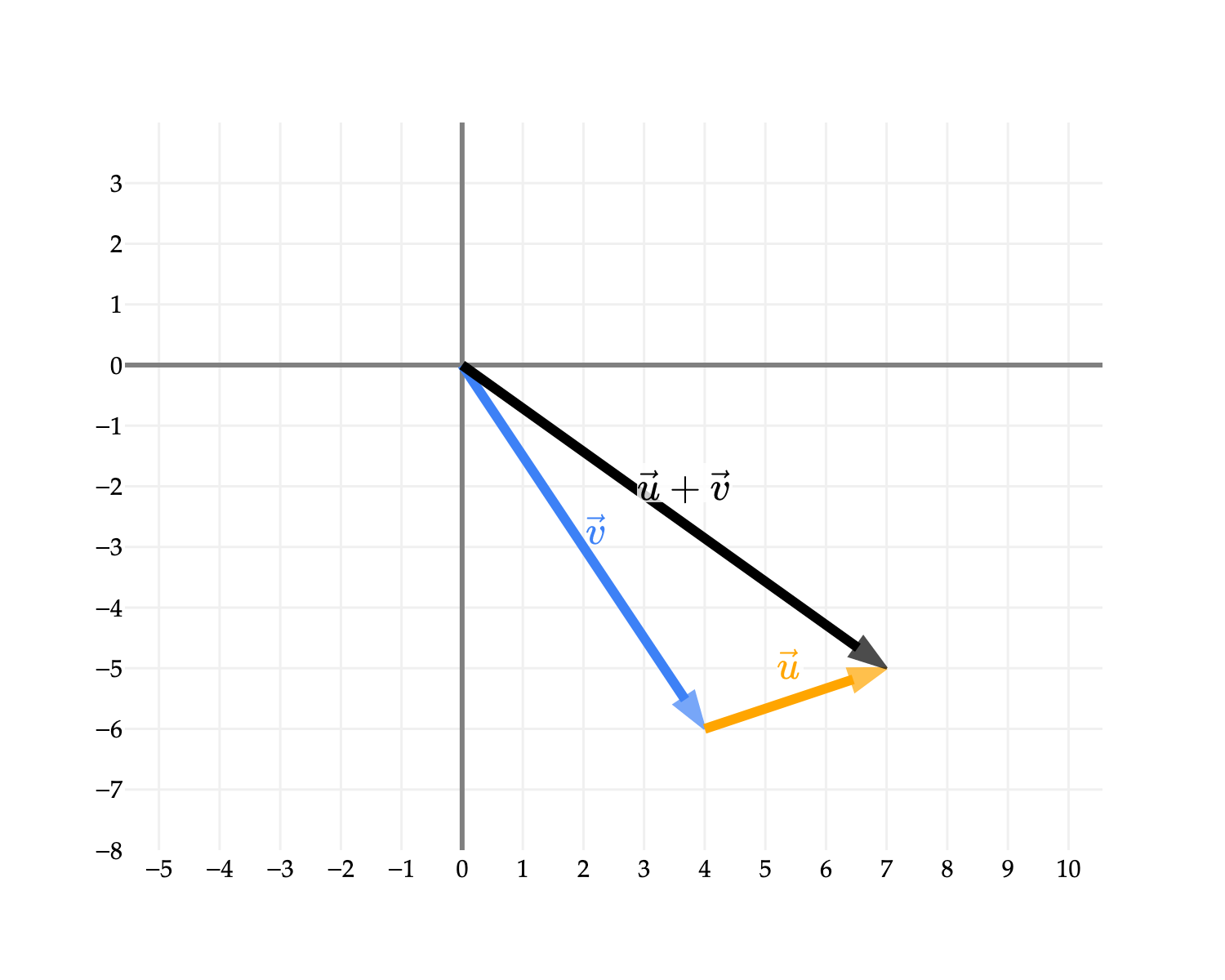
Vector addition is commutative, i.e. u+v=v+u, for any two vectors u,v∈Rn. Algebraically, this should not be a surprise, since ui+vi=vi+ui for all i.
Visually, this means that we can instead start with v at the origin and then draw u starting from the tip of v, and we should land in the same place.
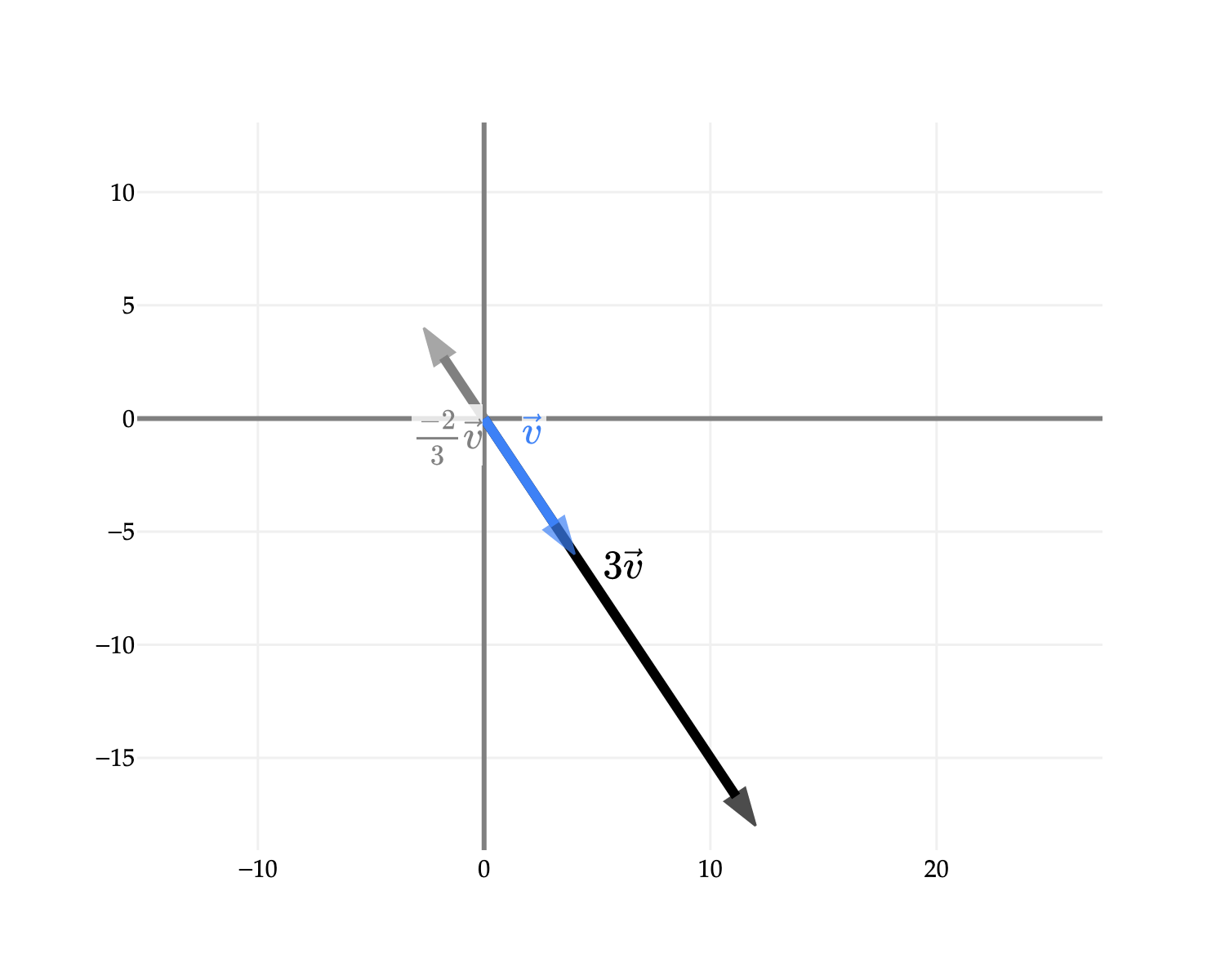
Using our examples from earlier, v=[4−6] as an example, 3v=[12−18]. Note that I’ve deliberately defined this operation as scalar multiplication, not just “multiplication” in general, as there’s more nuance to the definition of multiplication in linear algebra.
Visually, a scalar multiple is equivalent to stretching or compressing a vector by a factor of the scalar. If the scalar is negative, the direction of the vector is reversed. Below, −32v points opposite to v and 3v.
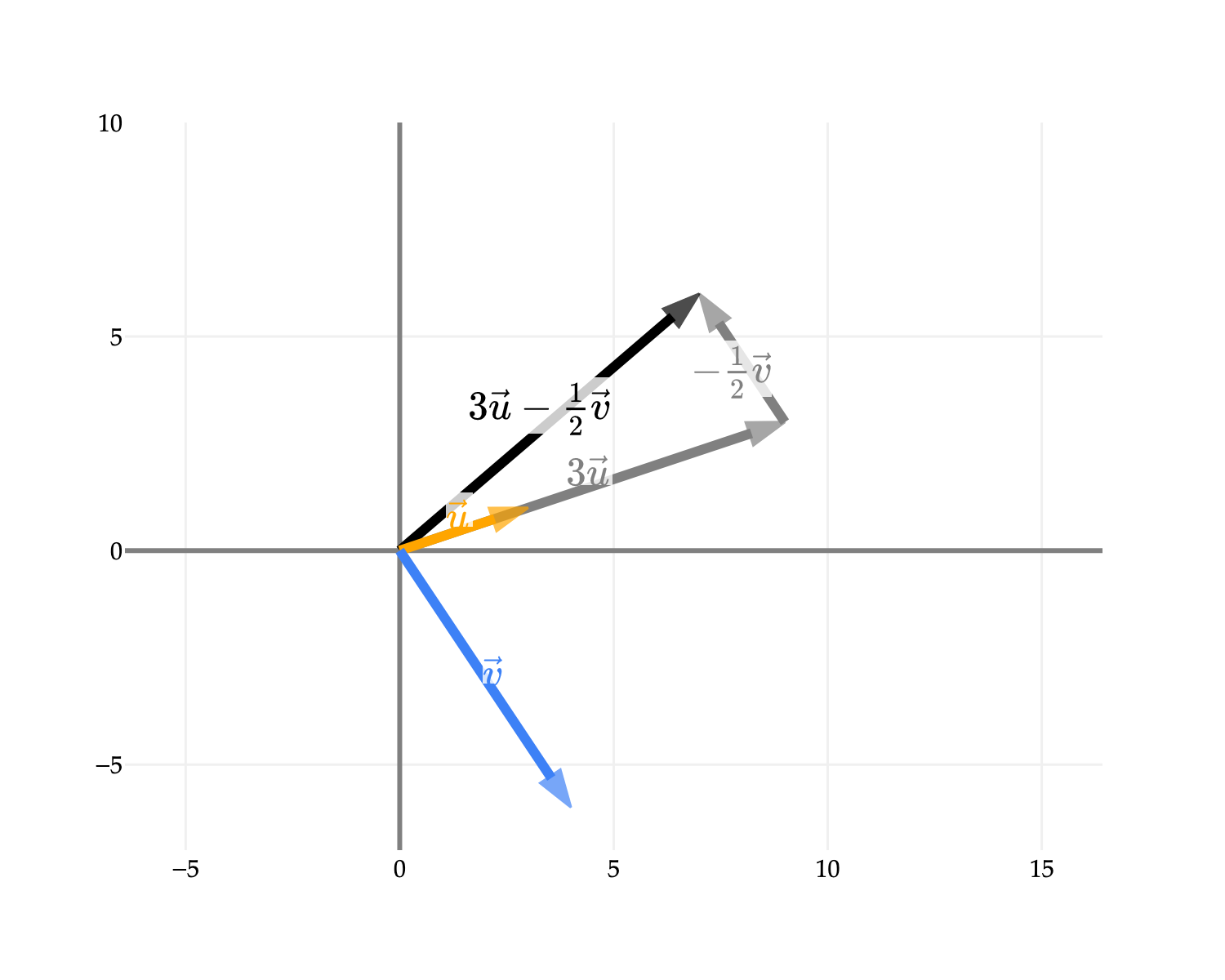
The two operations we’ve defined – vector addition and scalar multiplication – are the building blocks of linear algebra, and are often used in conjunction. For example, if we stick with the same vectors u and v from earlier, what might the vector 3u−21v look like?
3u−21v=3[31]−21[4−6]=[93]−[2−3]=[76]
from utils import plot_vectors_non_origin
import numpy as np
# Define coefficients (easily changeable)
c1 = 3
c2 = -1/2
# Define original vectors
u = np.array([3, 1])
v = np.array([4, -6])
# Calculate scaled vectors
scaled_u = c1 * u # -2u
scaled_v = c2 * v # 1.5v
result = scaled_u + scaled_v # -2u + 1.5v
# Calculate positions for vector addition visualization
origin = np.array([0, 0])
end_of_scaled_u = origin + scaled_u
end_of_result = origin + result
# Create vector list for plotting
vectors = [
# Step 1: -2u starting at origin (gray)
((tuple(origin), tuple(end_of_scaled_u)), 'gray', f'${c1} \\vec u$'),
# Step 2: 1.5v starting from end of -2u (gray)
((tuple(end_of_scaled_u), tuple(end_of_result)), 'gray', f'$-\\frac{1}{2} \\vec v$'),
# Final result: -2u + 1.5v (black)
((tuple(origin), tuple(end_of_result)), 'black', f'$3 \\vec u -\\frac{1}{2} \\vec v$'),
# Reference vectors (original u and v)
((tuple(origin), tuple(u)), 'orange', r'$\vec u$'),
((tuple(origin), tuple(v)), '#3d81f6', r'$\vec v$')
]
fig = plot_vectors_non_origin(vectors, vdeltax=0.3, vdeltay=0.5)
fig.update_layout(width=500, height=400, yaxis_scaleanchor="x",
xaxis_range=[-5, 15])
fig.show(scale=3)
The vector [76], drawn in black above, is a linear combination of u and v, since it can be written in the form 3u−21v. 3 and −21 are the scalars that the definition above refers to as a1 and a2, and we’ve used u and v in place of v1 and v2. (I’ve tried to make the definition a bit more general – here, we’re just working with d=2 vectors in n=2 dimensions, but in practice d and n could both be much larger.)
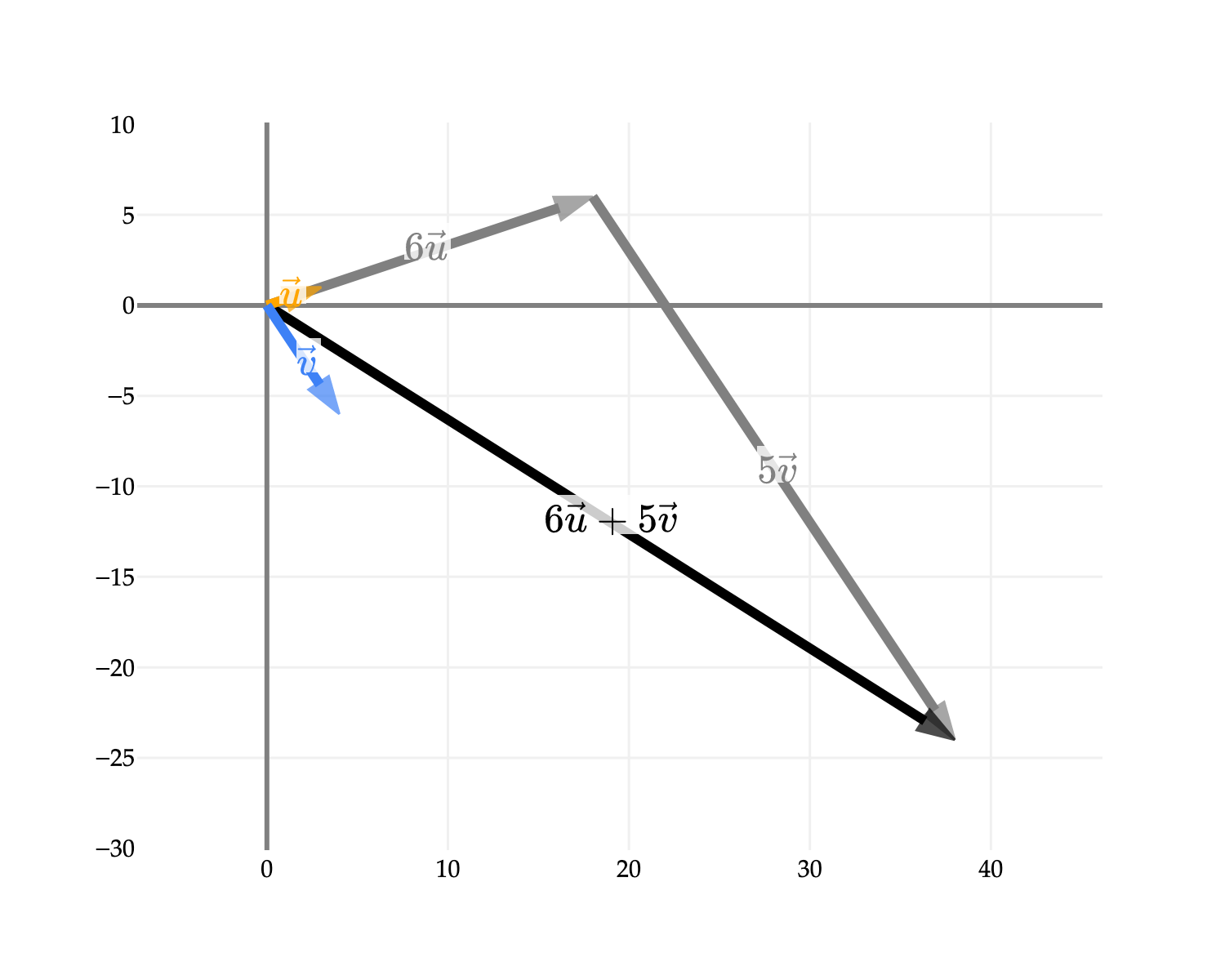
Here’s another linear combination of u and v, namely 6u+5v. Algebraically, this is:
6u+5v=6[31]+5[4−6]=[38−24]
Visually:
from utils import plot_vectors_non_origin
import numpy as np
# Define coefficients (easily changeable)
c1 = 6
c2 = 5
# Define original vectors
u = np.array([3, 1])
v = np.array([4, -6])
# Calculate scaled vectors
scaled_u = c1 * u # -2u
scaled_v = c2 * v # 1.5v
result = scaled_u + scaled_v # -2u + 1.5v
# Calculate positions for vector addition visualization
origin = np.array([0, 0])
end_of_scaled_u = origin + scaled_u
end_of_result = origin + result
# Create vector list for plotting
vectors = [
# Step 1: -2u starting at origin (gray)
((tuple(origin), tuple(end_of_scaled_u)), 'gray', f'${c1} \\vec u$'),
# Step 2: 1.5v starting from end of -2u (gray)
((tuple(end_of_scaled_u), tuple(end_of_result)), 'gray', f'${c2} \\vec v$'),
# Final result: -2u + 1.5v (black)
((tuple(origin), tuple(end_of_result)), 'black', f'${c1} \\vec u {"+" if c2 >= 0 else ""} {c2} \\vec v$'),
# Reference vectors (original u and v)
((tuple(origin), tuple(u)), 'orange', r'$\vec u$'),
((tuple(origin), tuple(v)), '#3d81f6', r'$\vec v$')
]
fig = plot_vectors_non_origin(vectors, vdeltax=0.3, vdeltay=0.5)
fig.update_layout(width=500, height=400, yaxis_scaleanchor="x")
fig.update_layout(xaxis_range=[-1, 40], yaxis_range=[-30, 10])
fig.show(scale=3)
I like thinking of a linear combination as taking “a little bit of the first vector, a little bit of the second vector, etc.” and then adding them all together. (By “little bit”, I mean some amount of, e.g. 6u is a little bit of u.) Another useful analogy is to think of the original vectors as “building blocks” that we can use to create new vectors through addition and scalar multiplication.
This idea, of creating new vectors by scaling and adding existing vectors, is so important that it’s essentially what our multiple linear regression problem boils down to.
In the context of our commute times example, imagine dept contains the home departure time, in hours, for each row in our dataset, and dom contains the day of the month for each row in our dataset. If we want to use these two features in a linear model to predict commute time, our problem boils down to finding the optimal coefficients w0, w1, and w2 in a linear combination of 1, dept and dom that best predicts commute times.
vector of predicted commute times=w01⎣⎡11⋮1⎦⎤+w1dept+w2dom
We’re going to spend a lot of time thinking about linear combinations. Specifically:
Again, just as an example, suppose the two vectors we’re dealing with are our familiar friends:
u=[31],v=[4−6]
These are d=2 vectors in n=2 dimensions. With regards to the Three Questions:
Can we write b as a linear combination of u and v?
If b=[76], then the answer to the first question is yes, because we’ve shown that:
3u−21v=[76]
Similarly, if b=[38−24], then the answer to the first question is also yes, because we’ve shown that:
6u+5v=[38−24]
If b is some other vector, the answer may be yes or no, for all we know right now.
If so, are the values of the scalars on u and vunique?
Not sure! It’s true that [76]=3u−21v, but for all I know at this point, there could be other scalars a1=3 and a2=−21 such that:
a1u+a2v=[76]
(As it turns out, the answer is that the values 3 and −21are unique – you’ll show why this is the case in a following activity.)
What is the shape of the set of all possible linear combinations of u and v?
Also not sure! I know that [76] and [38−24] are both linear combinations of u and v, and presumably there are many more, but I don’t know what they are.
(It turns out that any vector in R2 can be written as a linear combination of u and v! Again, you’ll show this in an activity.)
We’ll more comprehensively study the “Three Questions” in Chapter 2.4. I just wanted to call them out for you here so that you know where we’re heading.
Drag the plot above to look at all five vectors from different angles. You should notice that all of the linear combinations of w and rlie on the same plane! We’ll develop more precise terminology to describe this idea, once again, in Chapter 2.4.
Property 1 states that it’s impossible for a vector to have a negative norm. To calculate the norm a vector, we sum the squares of each of the vector’s components. As long as each component vi is a real number, then vi2≥0, and so ∑i=1nvi2≥0. The square root of a non-negative number is always non-negative, so the norm of a vector is always non-negative. The only case in which ∑i=1nvi2=0 is when each vi=0, so the only vector with a norm of 0 is the zero vector.
Property 2 states that scaling a vector by a scalar scales its norm by the absolute value of the scalar. For instance, it’s saying that both 2v and −2v should be double the length of v. See, at this point, if you can prove why this is the case.
Property 3 is a bit more interesting. As a reminder, it states that:
∥u+v∥≤∥u∥+∥v∥
This is a famous inequality, generally known as the triangle inequality, and it comes up all the time in proofs. Intuitively, it says that the length of a sum of vectors cannot be greater than the sum of the lengths of the individual vectors – or, more philosophically, a sum cannot be more than its parts. It’s called the triangle inequality because it’s a generalization of the fact that in a triangle, the sum of the lengths of any two sides is greater than the length of the third side.
To prove that the triangle inequality holds in general, for any two vectors u,v∈Rn, we’ll need to wait until Chapter 2.2. We don’t currently have any way to expand the norm ∥u+v∥ – but we’ll develop the tools to do so soon. Just keep it in mind for now.
Activity 6
The triangle inequality says that:
∥u+v∥≤∥u∥+∥v∥
In the example above, we had 74<10+52. In other words, there was strict inequality.
Find a pair of vectors u,v (say, in R2) such that the triangle inequality achieves equality, i.e. ∥u+v∥=∥u∥+∥v∥.
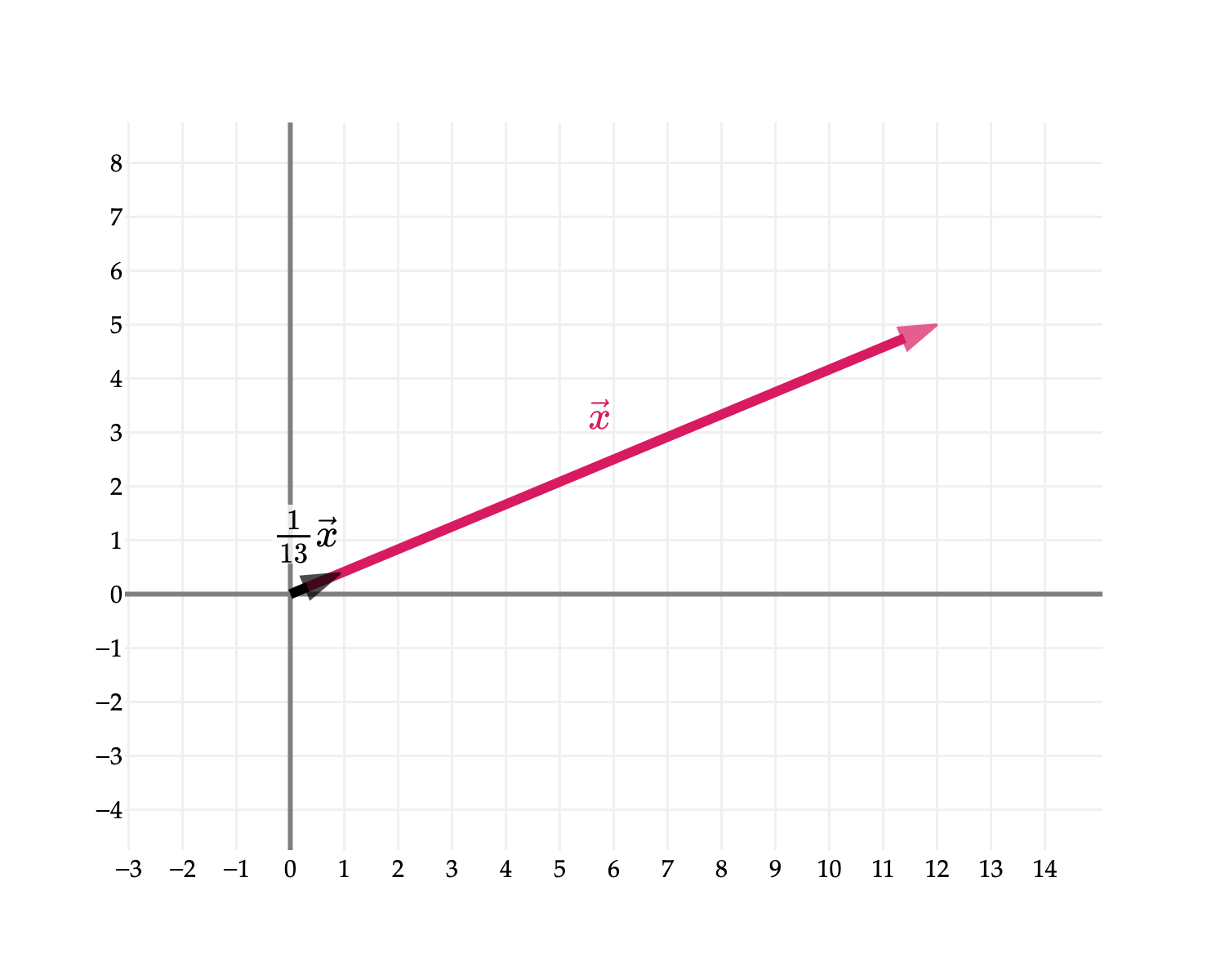
It’s common to use unit vectors to describe directions. I’ll use the same example as in Activity 1, when this idea was first introduced. Consider the vector x=[125]. Its norm is ∥x∥=122+52=169=13. (You might remember the (5,12,13) Pythagorean triple from high school algebra– but that’s not important.)
There are plenty of vectors that point in the same direction as x – any vector cx for c>0 does. (If c<0, then the vector cx points in the opposite direction of x.)
But among all those, the only one with a norm of 1 is 131x. Property 2 of the norm tells us this.
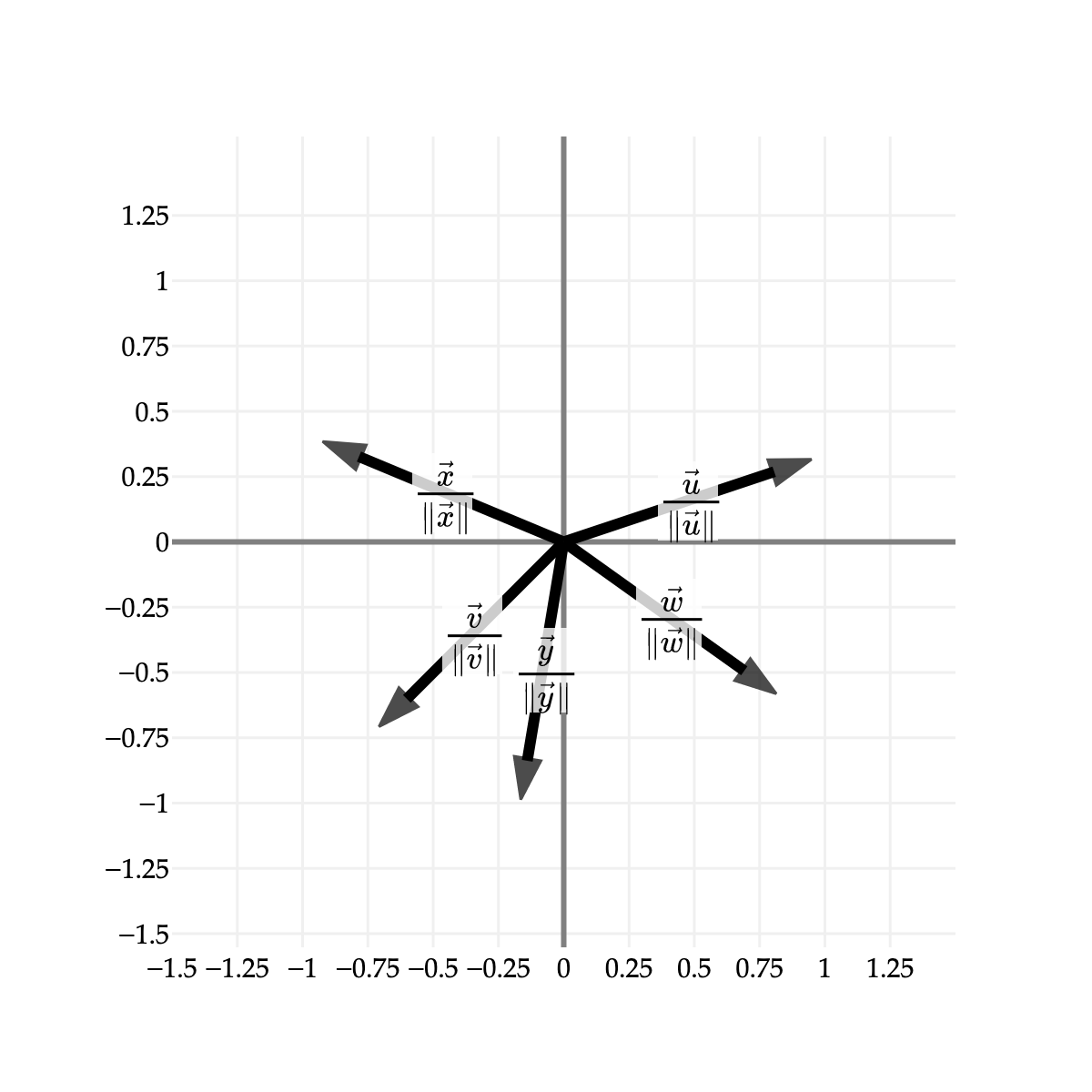
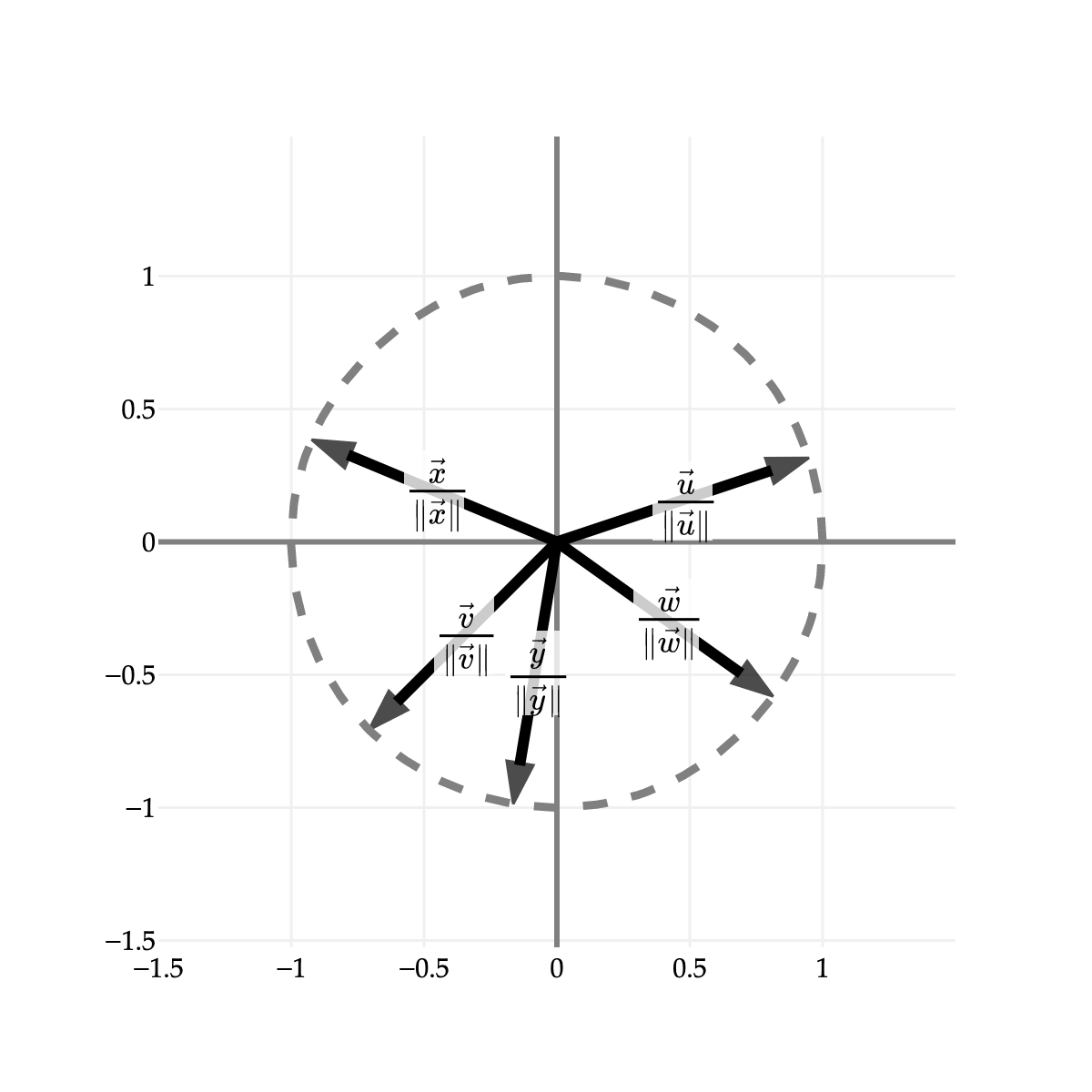
What do these vectors all have in common, other than being unit vectors? They all lie on a circle of radius 1, centered at (0,0)!
from utils import plot_vectors
import numpy as np
import plotly.graph_objects as go
# Draw the shaded unit circle
theta = np.linspace(0, 2 * np.pi, 200)
x_circle = np.cos(theta)
y_circle = np.sin(theta)
# Add the vectors on top
fig = plot_vectors([((3 / np.sqrt(10), 1 / np.sqrt(10)), 'black', r'$\frac{\vec u}{\lVert \vec u \rVert}$'),
((-1 / np.sqrt(2), -1 / np.sqrt(2)), 'black', r'$\frac{\vec v}{\lVert \vec v \rVert}$'),
((7 / np.sqrt(74), -5 / np.sqrt(74)), 'black', r'$\frac{\vec w}{\lVert \vec w \rVert}$'),
((-12 / 13, 5 / 13), 'black', r'$\frac{\vec x}{\lVert \vec x \rVert}$'),
((-1 / np.sqrt(37), -6 / np.sqrt(37)), 'black', r'$\frac{\vec y}{\lVert \vec y \rVert}$')
], vdeltax=0, vdeltay=0)
# Add dotted circle outline
fig.add_trace(go.Scatter(
x=x_circle,
y=y_circle,
mode="lines",
line=dict(color="gray", dash="dash", width=3),
hoverinfo='skip',
showlegend=False
))
fig.update_layout(width=400, height=400, yaxis_scaleanchor="x")
fig.update_xaxes(range=[-1.5, 1.5], tickvals=np.arange(-1.5, 1.5, 0.5))
fig.update_yaxes(range=[-1.5, 1.5], tickvals=np.arange(-1.5, 1.5, 0.5))
fig.show(scale=3)
The circle shown above is called the norm ball of radius 1 in R2. It shows the set of all vectors v∈R2 such that ∥v∥=1. Using set notation, we might say:
{v:∥v∥=1,v∈R2}
That this looks like a circle is no coincidence. The condition ∥v∥=1 is equivalent to v12+v22=1. Squaring both sides, we get v12+v22=1. This is the equation of a circle with radius 1 centered at the origin.
In R3, the norm ball of radius 1 is a sphere, and in general, in Rn, the norm ball of radius 1 is an n-dimensional sphere.
Activity 7
Find the unit vector that points in the same direction as z=⎣⎡40−3−3⎦⎤.
So far, we’ve only discussed one “norm” of a vector, sometimes called the L2 norm or Euclidean norm. In general, if v∈Rn is one vector, v=⎣⎡v1v2⋮vn⎦⎤, then its norm is:
∥v∥=v12+v22+⋯+vn2=i=1∑nvi2
This is, by far, the most common and most relevant norm, and in many linear algebra classes, it’s the only norm you’ll see. But in machine learning, a few other norms are relevant, too, so I’ll briefly discuss them here.
The L1 or Manhattan norm of v is:
∥v∥1=∣v1∣+∣v2∣+⋯+∣vn∣=i=1∑n∣vi∣
It’s called the Manhattan norm because it’s the distance you would travel if you walked from the origin to v in a grid of streets, where you can only move horizontally or vertically.
The L∞ or maximum norm of v is:
∥v∥∞=imax∣vi∣
This is largest absolute value of any component of v.
For any p≥1, the Lp norm of v is:
∥v∥p=(i=1∑n∣vi∣p)p1
Note that when p=2, this is the same as the L2 norm. For other values of p, this is a generalization. Something to think about: why is there an absolute value in the definition?
All of these norms measure the length of a vector, but in different ways. This might ring a bell: we saw very similar tradeoffs between squared and absolute losses in Chapter 1.
Believe it or not, all three of these norms satisfy the same “Three Properties” we discussed earlier.
Back to x=[125]. What are the L2, L1, and L∞ norms of x?
Let’s revisit the idea of a norm ball. Using the standard L2 norm, the norm ball in R2 is a circle. What does the norm ball look like for the L1 and L∞ norms? Or Lp with an arbitrary p?
The L1 norm ball looks like a diamond. Any vector with an L1 norm of 1 will lie on the boundary of the ball. The L∞ norm ball looks like a square, and the L1.3 norm ball looks like a diamond with rounded corners.
This is not the last you’ll see of these norm balls – in particular, in future machine learning courses, you’ll see them again in the context of regularization, which is a technique for preventing overfitting in our models.
Activity 8
In the case of x=[125], the L1 norm (12+5=17) is greater than the L2 norm (122+52=169=13), i.e. ∥x∥1>∥x∥2.
Find a vector y∈R2 such that ∥y∥1=∥y∥2.
Try and find a vector z∈R2 such that ∥z∥1<∥z∥2. What do you encounter?
Prove that ∥x∥2≤n∥x∥∞ for any vector x∈Rn. (Hint: Start with the definition of the L2 norm of x, square it, and try and compare each element in the sum to the largest element in the vector.)
It’s been a while since we’ve experimented with numpy. A few things:
As we’ve seen, arrays can be added element-wise by default.
Arrays can also be multiplied by scalars out-of-the-box, meaning that linear combinations of arrays (vectors) are easy to compute. The above two facts mean that array operations are vectorized: they are applied to each element of the array in parallel, without needing to use a for-loop.
To compute the (L2) norm of an array (vector), we can use np.linalg.norm.
Suppose you didn’t know about np.linalg.norm. There’s another way to compute the norm of an array (vector), that doesn’t involve a for-loop. Follow the activity to discover it.
Activity 9
In the cell above:
Write u ** 2. Squaring a vector is not an operation we’ve discussed (and isn’t an operation that exists in math), but numpy gives you back another array. What does this array contain?
Using np.sum and the new array you just created, find the norm of u without using np.linalg.norm.
Find the norm of 3 * u - 0.5 * v using the same technique, and make sure you get the same result as was already displayed for you.
In general, we’ll want to avoid Python for-loops in our code when there are numpy-native alternatives, as these numpy functions are optimized to use C (the programming language) under the hood for speed and memory efficiency.